October 2002, Issue 83 Published by Linux Journal
Front Page | Back Issues | FAQ | MirrorsThe Answer Gang knowledge base (your Linux questions here!)
Search (www.linuxgazette.com)

Editor: Michael Orr
Technical Editor: Heather Stern
Senior Contributing Editor: Jim Dennis
Contributing Editors: Ben Okopnik, Dan Wilder, Don Marti
![[tm]](../gx/tm.gif) ,
http://www.linuxgazette.com/
,
http://www.linuxgazette.com/
|
...making Linux just a little more fun! |
From The Readers of Linux Gazette |
 An idea to the Linux Project. Make a complete new Help System/manuals :-)
An idea to the Linux Project. Make a complete new Help System/manuals :-)As I initially planned to go after this with the Editors' Scissors I couldn't decide quite what to snip without having to put my own nickel's worth in at multiple places. Leaving it intact is a better example of the sort of ordinary soul who wants a simple set of instructions.
I'll suffice to say that I favor his attitude, but fear the sort of people who already have even heard of Linux Gazette might be above his "level 1" threshold, and he is not in the least bit clear where to draw dividers for his other 4 levels. He also shows a bit of intelligence and may be beyond "level 1" himself, too.
Many commercial distros come with "quick start" guides geared for the discs in the package. If you need that, I urge you, it's worth spending the money.
Beyond a fairly minimum start, what's a spreadsheet if you won't put numbers in it, an email program if you can't decide who to send mail to ... do we know any mail programs that will tell you why not to spam before letting you use them? There is more to life than simply being told, step by step, which button to push.
On the other hand, the big name distros at this point have so many applications in them that a "level 1" manual covering each would get so huge no level 1 personality would dare crack it, or the set of them, open. We used to have it as a cartoon on the wall back when I was in tech support: "I can tell I'm getting to this guy. I heard him open the shrink wrap on the manual."
But we will cheerfully point a News Byte entry at resources that make some effort to divide up the world of Linux info along the lines of how much experience you have. And yes, Mr. Larsen, that will require us to point you at a website somewhere. The weapon, should it come to exist, is no good if we truly keep it a secret. -- Heather
This mail is about making an even better manual -and help system, which
ordinary endusers can understand, and read and USE. smile - positive -
friendly - but not clever
![]()
I am sorry, that I try to pass my idea around to various people by e-mail, but I have not yet found out the perfect way to do do.
I hope, that my ideas would saw an even better idea, because I am not that clever.
I am running my private "war" laugh to make Linux user friendly.
And this is my contribution to the Linux Project, I mean this idea.
If you don't like me, just scrap this letter
![]()
There is sitting so many ordinary people out there, surfing the internet, using windows, and having lots of problems. So it is for me. I have worked with win3.11, 95 and now win 98. The screen freeze, programs cannot work together and so on. You probably know?
Therefore I now find that "D-day" has come, to attack. joking
It is time to make the millions og people, surfing the Internet, shift from windows to Linux.
But in order to accomplish this, it is needed with a campagn called:
"Now Linux has become really userfriendly to install, use and surf the
internet with", or maybe a better name ?
![]()
Therefore my idea goes towards making e.g. 5 levels of help manuals. The total easy manual could be level 1. The levels for the professionals 2 - 5 hi
Keep -and continue developing Linux and its help -and manualsystem as is.
This level 1 manual should be made, by letting a completely newbie sit next to an Linux expert. Then they together shall install -and use Linux, and the necessary programs. Then let's say, a journalist shall write alle the stupid questions down into a manual. Just like the conversation goes on. It must be completely simple, only ordinary words.
E.g. "You take the Linux cd called binary 1, and put it into the cd box"
and so on !!
![]() The whole way, like this.
The whole way, like this.
Then the same thing with all the important everyday programs. I mention: Start and log into Linux Connection to the internet - set up same -browser - mail program - news program - text editor - spread sheet - zip program - backup program - pgp program - wine - direct cable - real player - scandisk - webcopier (wget) - how to install a new program - and to remove it - and probably some more. Those are my minimum windows programs. I just mention those I use. I mean just the minimum number of programs. All above programs shall have this minimum level 1 manual, so people can start using Linux and more important open the individual program and immediately start using it. Only the minimum points, so you do not have to read pages and pages, to make it work. And please lots and LOTS OF EXAMPLET. That is the simplest way.
Keep all the existing (man - info - howto etc) as is. They belong to
level 2 - 5 !!
![]() They shall be used as cross reference. But here also is needed a
complete Linux reference book, covering about everyting, because Linux
now is so extensive.
They shall be used as cross reference. But here also is needed a
complete Linux reference book, covering about everyting, because Linux
now is so extensive.
I know, because I was at one point working with the High Pack surveying program. It came with huge manuals. Nobody was able to read it, og had the time. Then I made a manual of some a4 pages. I just wrote down just what I did, which buttons I pressed.
If you do not change attitude towards the paedagogic principles, concerning using computer programs, one do not move much towards getting people using Linux.
Only the minimum programs and their level 1 manuals, so people can begin using Linux. Then they later can fiddle into the more extensive matters, if they want to, or are able to.
Also, tell the programmers, to make their user programs simpler, and not having so many possibilities. Because it confuses normally people.
I say, make it SIMPLE and "talking" normally language, Do not call things devices, but floppy, cd, etc. because people do not understand it, and they then just stick to windows, because they have been brainwashed to use this!
Hope you get my message???
![]()
![]()
![]()
![]()
![]()
![]()
I repeat, keep the existing as is, but make this simple manual, as the secret weapon of Linux. I shall here in the end just mention, that I gave above idea to Bill Gates. But he just told me to approach him with a lawyer. He was afraid to be sued by me. But that is not my idea. Just giving a suggestion.
Maybe you can get just a tiny new thinking from this letter.
I am an old pensioner, and I can only give this idea, as my contribution to the Linux Project, which I find fantastic. But I still have difficulties in getting my Linux work. I cannot remember all I read. And please also free us from this phrase: "just go to this and this website". It is ok on level 2 - 5.
I am wondering, that now data programs has existed for so long, but still one is using this ridiculous complex manuals. I think programmers has been brainwashed by windows manuals/help system, which really is no good.
I think that the closest way to get enduser using Linux in buried in the help system, which has been neclected, I think ! I think this clever programmers are buried in the very programming, and are missing the link to the end-user
An example of what I mean: Word Perfect is a program, which main purpose is to be used to write a letter: In order to use the program do the following: 1. To open the program do so and so.... 2. To write a letter do so and so.... 3. When you have written the letter you should save it to both a harddisk and a floppy disk. Do so and so.... 4. To print the letter do so and so...... 5. And so on...... All the smart gadgets with the program is not necessary to show.
I mean, that the important thing is, to be able to use the various programs immediately.
Then if you want to do the more complex things with the program, use level 2, 3, 4 or 5. smile a lot ( I think, that even my older sister would be able to understand!)
If you can get lots of people going surfing the Internet and writing
letters, as a minimum, using Linux, maybe a part of them slowly will
begin digging into other parts of Linux. And that would be good, at
least I think so!
![]() Maybe, even that was your ultimate goal?
Maybe, even that was your ultimate goal?
Sorry, if I repeat something, but I am old.
Kind regards
A grass root, who hope to saw just a tiny seed still -laughing -
positive - friendly
September 2002.
Please do not reply, thank you
![]()
PC-MOSThis is a multi-part message in MIME format.
[argh. stop that, it's a serious waste of bits. For a oneliner question you just sent 3 extra email header lines, and a stack of HTML.]
Where can i find myself a copy of PC-MOS?
We don't know. The fact that the Answer Guy, Jim Dennis, took a best shot at poking around the internet a number of years ago, to answer a question about it, is the best we've got. PC-MOS itself appears to have disappeared and all that remains may well be all the search engine entries that point to our dusty little tidbits on the topic.
But if you've got a Linux question, or you got a thing you were trying to do with PC-MOS and wonder if some flavor or other of Linux is up to doing that for you... please, feel free to ask in more detail!
Minimal Linux (Redhat 7.2) InstallationI have a 40 GB hard disk. I have Redhat 7.2 installed with all the features on the hard disk taking about 2GB. I used the grub boot loader.
Now I have done a minimal redhat(7.2) installation on my hard disk.I could not go below 275 mb though. I edited my old grub.conf that is with the first installation and added this new redhat minimum installation paths.
During the boot when i select minimum version i got an error saying bios wasn't able to reach my new installation because of the cylinder limit. So I made a work around by specifying the boot of the old installation( both of them are same versions) and changed the root to my new installation. This worked and i was able to boot into my new installation.
Now after booting into my new minimum installation i deleted all the docs and man pages and further reduced my installation size from 250 mb to about 135 mb. After this i used the dd command to image the new installation to another linux partition which i created and having a size of only 200mb. I copied only the first 135 mb from the source partition to the target partition.
I added another label in grub.conf to point to this partition and tried to boot. But after some initialisation messages it stopped after showing the message kernel panic. I saw a message stating that "attempt to access block beyond reach" and showed the block limit on the partition and the block which was tried to access. Obviously the block it was trying to access was beyond the limit.
I am doubting whether this is some kind of fragmentation problems.Whether the first 135 mb of the source disk doesn't contain all the installed data. Could it be that this data is scattered all over this partition and i cannot image it directly into another partition. If that is the case what can i do about this? Is there any defragmentation tools available under linux?
My aim is to reduce the linux installation size and to make an image of this reduced installation on a seperate 200 mb disk and to be able to boot and work on it.
I actually don't know whether this method works.This is a sort of experimentation.
Are there any other way of achieving this aim?
thanx
sree
U of Phoenix
Tue, 13 Feb 2001 10:00:12 -0500
K.Woodward (kwoodwar from mindspring.com)
Hi,
I have a problem trying to setup Linux to access the servers at the University of Phoenix. The servers (Microsoft IIS) require a "log on using Secure Password Authentication" under Microsoft Outlook Express. I understand that this requires a email and news reader to authenticate using the WindowsNT Challenge/Response (NTCR) protocol [a really bad use of the http protocol]. The school does have a website to get to the email and news groups but it is timed and is very particular and seems to like rejecting Netscape Navigator access. The UOP Tech group's pat answer is that they only support Outlook Express under Windows, I want a Linux answer.
Is there any program or daemon that I could run to allow me to authenticate using this protocol so I could use Linux based email and news readers? I have tried using pine, staroffice, and leafnode and several others which are common under KDE/RedHat 6.2.
Thanks,
K. Woodward
I am using linux to try to connect to UOP now and have not found an answer to the problem that you had did you ever find a solution that worked if you did could you outline it for me.
Thank you,
Pat Norton
[LG 82] 2c Tips #2 completionAdam,
The site for this Tip doesn't appear to be up any more. Do you have an alternate source or can send me the rpm or the source rpm?
Thanks,
Bill Thompson
I (the LG editor) was unable to reach that link when I was proofreading 2-Cent Tips ("connection timed out"), but I was hoping it was a temporary error. We at LG do not have any alternate sources or RPMs. Maybe Adam who submitted the tip does. -- Mike
I usually go poking around for them on rpmfind.net if I know some file they contain, or on freshmeat.net if I know the name of the project, in the hopes of finding whatever upstream source tree might remain. Sometimes I can find out why there's not an rpm anymore, but that's pretty rare. -- Heather
How about Jed?First of all: LG is great! One of the best newsletters (?) I've ever read. Easy to browse webpage, understandable language, various topics. Great, just great.
There's just one thing I'm missing: there was a column for Emacs - fans, a nmber of articles about vim, even nano was mentioned. And what about jed? It's as powerful and customizable as emacs, but much lighter and easier to use. Will there be a few lines about this great tool?
regards,
Lukasz Grabun
We'd be happy to publish an article on jed if somebody volunteers to write it. Would you? The Author Information at http://www.linuxgazette.com/faq/author.html shows the desired HTML format.
Penguins, Lizards, and Pandas?I'm proud to say that I've been a Linux user since July 2002 and I've enjoyed my new found computing freedom very much. I've also learned a lot, too.
I began my Linux experience with my purchase of Mandrake 8.2, a great distro. for a beginner, like myself. I also started out using KDE as my desktop manager, but have now found new liberties with the use of Window Maker. Which brings me to my submission to you today.
Linux itself has the wonderful Tux as its
representative. KDE has a dragon-like lizard, and
Gnome has a footprint of a gnome, I'm assuming. After
reading from the Window Maker web site, I learned that
Window Maker has chosen a Panda as it's mascot. So, I
decided to make a contribution to the line up of cute
and cuddly cartoon PR "toons" with this
drawing of Amanda, the Window Maker panda:
![[cute Windowmaker panda]](misc/mail/WM_Panda2-small.png)
Oh, that's soooo cute! A panda with an attitude. /me likes.
![]() -- Ben
-- Ben
Now, don't you just want to start using Window Maker? :o)
Nope.
![]() But then, I'm an "icewm" junkie from way back.
But then, I'm an "icewm" junkie from way back.
I think I'll have to lobby Marko Macek for a mascot now. -- Ben
Keep the very informative issues of Linux Gazette coming! I enjoy them very much.
David Bouley
Glad you like'em, David! Stick around; there's always more good stuff in the works. -- Ben
An explanation sidebar might be inline about what a PNG is, why GIF, and now JPEG, are Bad Ideas, and why Internet Exploiter 5 doesn't know how to deal with PNG's. At least not as URLs; maybe it gets them right as inlines... -- jra
The only problem I've seen with PNG is that Netscape 4 displays a solid filled rectangle instead of the image if the image contains any transparency.
As for JPG, I've heard conflicting information on whether any patent applies to it, but the last I heard was that there wasn't a problem. Have you heard differently? -- Nike
JPEG is fine. The so-called JPEG patent is bogus, and if Forgent tries to use it, they will lose it (like BT and the hyperlink patent) (This is from the leading defender of software patents, Greg Aharonian: http://www.aful.org/wws/arc/patents/2002-07/msg00029.html)
(Linux Journal has been using PNG instead of GIF since our redesign last year, and there have been no complaints.) -- Don
And of course, Don ought to know, since he cheerfully burns all GIFs. (http://www.burnallgifs.org) It's a good site to check on why a number of patents out there are really quite foolish. -- Heather
In any case, PNG and JPG have quite different uses. PNG is good at compressing line art but bad at compressing things with lots of colors (e.g., photographs), whereas for JPG it's the reverse. Whenever somebody sends a GIF to LG, I convert it to both PNG and JPG, and take whichever one has the best compromise of small size and color brilliance. It's not always one or always the other. Sometimes the sizes are hugely different, as in one being four times the size of the other. -- Mike
Thank you!I read your article "Routing & Subnetting 101", and... wow! I listened to my teacher ramble on for almost 3 hours and I didn't absorb a darn thing. By reading your article I think I know enough to really get my hands dirty.
Thanks, Again.
Bryan Lord
Questions to linux-questions-only@ssc.com and linux-questions-only@ssc.comWe're working towards getting all sites that mention us to give the correct address, and to get them to not mention us if they suggest we cover anything that's not about computers.
Please spread the word!
bridging and routingPlease do not publish my email address; I will read the Gazette for any responses.
Email address will not be published. It shows up in this correspondence, but there's no public archive of this list.
We do publish addresses for Mailbag items and 2-Cent Tips, but not for Answer Gang questions. That's Heather's choice as the TAG Editor Gal. If I were doing it I'd publish addresses in the Answer Gang column too, because why should that column be different? In any case, you don't know which of the three columns your letter might appear in. A lot of it has to do with whether it produces one or two short replies or a long discussion.
So the only way a reader can guarantee his/her address won't be published is to specifically ask us not to.
-- Mike
Originally, the Answer Guy column was purely the answers of Jim, but as it changed, The Answer Gang column is now about matters which have pretty much been solved, or discussed to death in some fascinating way. Therefore unless the original querent's problem remains unsolved -- a real stumper -- there's little need to provide his or her email address, but we do mention the name.
In the case of Tips other people may have useful comments, so the address is offered.
Unless, of course, they'd like to be anonymous.
People do not get selected for Help Wanted if they wish to be anonymous. You can't beg a few thousand readers for help that way. They just have to have a complete and interesting enough description to tantalize one of the Gang to answer them. -- Heather
(no subject)[ An 8 line sig block claiming confidentiality, erased per its instructions. ]
Must be confidential indeed; it didn't say anything but this!
This mailing list (The Linux Gazette Answer Gang, which makes its home at linux-questions-only@ssc.com) is not a confidential location. It is a mailing list filled with a medium sized handful of Linux folk, who expect as their main pay a bunch of warm fuzzies and the knowledge that a really juicy answer can be published for the readers of our monthly magazine. Opinions are likely to run rampant, conclusions may or may not occur (we guarantee nothing) and attachments in HTML are often ignored or grumbled about unless you're defending a foreign character set (yes, we have translators). It's a good idea to actually dust off your sense of humor because we definitely use ours.
If you need an answer in some business-like fashion, you'll have to consider a consultant instead. LinuxPorts has a good list of them.
If you want an answer in a "Making Linux a Little More Fun" fashion
you'll at least need to provide us a real question, and if this
sig block of yours is automatic, a disclaimer that supercedes it and
grants publishing permission. We have examples in our "Ask The Gang"
FAQ; see http://www.linuxgazette.com for more. Lots more
![]()
Your HTML attachment has been sent to the shredder; it wanted a snack and we won't be passing out candy for almost a month !
Pl give solutionHi choudhary,
Dear sir, Pl give sol these problem 1 Write a shell script to print end of a glossary file, in reverse order . using array (Hint use awk ,tail )
Q-2 Modify call command to accept more than one month? Q-3 Write a shell script to print file names one per line has directory showing serial number of file
I see schools have started again...
While we're perfectly willing to help you with any questions you have about Linux, we will NOT help you with your homework.
I am sure you will find all the info to solve the problems in the textbook(s) your professor gave you (or had you buy). It (they) might be a very interesting read - just try it.
Grtz,
Frank
Letter of inquiryDear Sir,
I am writing this letter to inquire about your product Red Hat Linux. I saw Red Hat Software's advertisement . . .
Red Hat is a company of its own; you should follow contact information provided in the advertisement. -- Heather
Try
http://www.redhat.com
-- Dan Wilder
We don't make Linux, we just blather about it.
See
http://www.redhat.com as well as
http://www.linux.org and probably
http://www.li.org not to mention
http://www.tldp.org
-- jra
. . . for version 5.1 of Linux in the issue of Linux Journal.
That's an interesting case of time travel you have there; you've reached the Linux Gazette, which is a related pubication in that we're hosted by the same publishing company.
Red Hat 5.1 is quite ancient... -- Heather
RedHat is up to 7.3 in production release, and there's a beta 7.4 out there somewhere, I think, rotting people's cats' teeth. -- jra
They [Red Hat] are mirrored in a number of countries so it should be possible to find an instance of the 7.2 "GPL edition" disc on servers nearer to you. Beware that downloading 650 MB can take a while, though. -- Heather
I was quite impressed with the capabilities as listed in the advertisement, and I would like to learn some more about the product. I am a student and we are studying about Linux and this is the reason why I want to learn more about the product.
Running older versions of Linux for experimental purposes, or studying what was claimed of Linux a few years ago to see how it has grown, are both valid student projects. -- Heather
another thing is I want to subscribe a magazine about linux operating system.
In that case you came to the right place, almost :D
I cheerfully direct you to the website for Linux Journal, http://www.linuxjournal.com where you can use a secure connection to subscribe, or find more information about having it sent to you monthly.
Linux Gazette is only available as a webzine although that leads to some unusual "subscription" models in the form of Sitescooper, debian packages (lg-subscription), and services that can tell you when a website changes. These features are not provided by staff of the Gazette but rather, by volunteers elsewhere. -- Heather
Hope you could reply me as soon as possible.
Sincerely yours,
Dang
Hope you found this useful!
Thank you, and enjoy Linux. -- Heather
ssc subscriptionI subscribe to various linux/dos/security/pascal/xbase lists, so knowing what "ssc" is is somewhat difficult. Once a month you send me a reminder to make sure I still want to subscribe. Please consider describing the various subscriptions, including other ones that might be of interest.
SSC is Specialized Systems Consultants, Inc, the company that publishes Linux Gazette, the print magazine Linux Journal (http://www.linuxjournal.com), and books and reference cards about Linux/Unix. The message you get once a month is from our mailing-list server, reminding you how to unsubscribe or change your settings. Other mailing lists we run are are at http://www.ssc.com/mailman/listinfo and in the top right corner of http://www.linuxjournal.com . A few are discussion lists, but most are announcement-only lists (newsletters).
-- Mike
How to Ask a QuestionHow can I ask a question to the answer gang?
Naresh
Send your note to the address: linux-questions-only@ssc.com
Make your subject a useful one.
Make your description of what you're trying to do, and what is going wrong, sufficiently detailed and interesting that some of the gang can answer it.
We might answer in a big burst, or after a long time, or not at all. A small portion of the "not at all" get pubbed as Help Wanted and readers from all over the world may give those a shot - but for that the description does have to be pretty clear.
We've more details in the Linux Gazette FAQs.
Good luck! -- Heather
|
...making Linux just a little more fun! |
By |
 Canon BJC 250
Canon BJC 250Regarding Bessie's problem in the sept. 2002 issue of LG (Help Wanted #1): http://www.linuxgazette.com/issue82/lg_mail.html#wanted/1
I also have one of these printers, and it has worked nicely, at least for monochrome. I have done limited color testing - early on, it would print in color if I selected a different printer driver at that time (bj 200 is only capable of doing monochrome). Colors were somewhat washed out, and i never got around to really testing things like gamma correction. Besides, that was some time ago, before cups et al.
I sent bessie an email asking if she were using cups. There is a little difference in the revs of cups at least with Mandrake 8.1 which is what I'm currently running. If I use printerdrake, i am able to select a bj200 driver, which is perfect for doing monochrome printing, and the test page prints just fine. If i use another printer configuration tool, there is no corresponding entry for my printer. However, selecting a similar model driver is doable if the exact model is not listed -- and seemingly in (how?) recent cups it is not. And seemingly, there are different printer databases. (i built cups 1.1.10 I think sometime ago from source).
sendmail and CourierThis is in regards to September's help wanted #2: http://www.linuxgazette.com/issue82/lg_mail.html#wanted/2 -- Heather
Hi,
First, you'll have a problem using sendmail and maildir, since, sendmail does not support maildir, only qmail and postfix support this. If you've a
However, consider using procmail as the local delivery agent. I believe sendmail will support this, though I should mention I haven't used sendmail for quite a few years. Anyway, procmail supports maildir delivery.
-- Dan Wilder
A different reader seemed to believe that sendmail cannot, only postfix and qmail -- but yet another reader chimed in that it's the default on his distro for sendmail to use procmail as its local delivery, after which it's of course no problem. Sadly they had confidentiality notes on their mails, so no juicy details. Sorry. -- Heather
Postfix hates OutlookThis is for help wanted #3 in September's issue: http://www.linuxgazette.com/issue82/lg_mail.html#wanted/3 -- Heather
Determine if the mail server is trying to perform reverse resolution for your IP address. This can lead to odd time-out problems with various services. A quick test is to add a mapping for your IP address to the mail server's /etc/hosts and see if the problem goes away.
Regards, Dustin
From: SnT_BaBS <babs@sntteam.org>
I think that u can't access root account with pop3 server for security reason ...
Maybe i'm wrong ... but it can be ...
Regards
![]()
Babs here has to at least be partly right. Postfix doesn't speak POP3 -- it speaks SMTP! Common pop3 servers include qpopper, solidpop, or ipop3d. -- Heather
ping with ipmasqThis is in reply to the September 2002 help wanted #4: http://www.linuxgazette.com/issue82/lg_mail.html#wanted/4 -- Heather
Hello Matt and LG,
My name is David Ranch and I am the author of the IP Masquerade HOWTO as well as the TrinityOS documentation project.
Anyway, regarding your eth0/eth1 issue, have you checked the DUPLEX setting on the Ethernet switch? The tell-tale signature of this is the "carrier" transitions in your "ifconfig' output. Since you have a switch and not a dual-speed hub, make sure it's set to FULL DUPLEX for that port connected to eth1. You also might want to force the speed on that port to 100 as well. Ethernet auto-negotiation has always been a problem.
If that doesn't fix things, do you have a different Ethernet card to try? Personally, I think all LNX* network cards are pretty crappy though they do work. I've had great luck with any Tulip-based network card (Netgear FA310 [not the 311, etc]), Intel EtherExpress, etc.
Ps. The comment from Heather at the bottom of
http://www.linuxgazette.com/issue82/lg_mail.html#wanted/4
is plain wrong. The IPMASQ code has supported ICMP MASQ since the Linus kernel 1.2 days (possibly earlier).
--David
In fact, I did see some references to it behaving correctly - later - but never have figured out why it wouldn't work in real life while I was dealing with it. Which means that while it's surely supported, if I'm in a situation on a 2.2.x kernel where ICMP is not working past NAT, I have no idea how to convince it to start working.
Oh well, we all have our specialties; I'll go back to tweaking X displays and tuning up laptops, now.
I absolutely agree that the Tulip chipset is the good stuff. Never leave home without it. -- Heather
multilinkHello John, LG,
My name is David Ranch and I am the author of the IP Masqeurade HOWTO as well as the TrinityOS guide.
Anyway, I saw your LG question:
http://www.linuxgazette.com/issue82/lg_mail.html#wanted/5
First off, one of the posters mention that EQL is the solution. This is incorrect as EQL is rarely supported any other terminal servers than possibly older Livingston Portmaster. Like you mentioned, you want MultiLink PPP.
Oops, I thought they were one and the same. Thanks for pointing out my misconception. -- John Karns -- Heather
Before you start looking into setting this up, you should call your ISP and see if they allow ML-PPP? Many don't and the few that do usually only support it for ISDN users.
Good point, one which I forgot to make. -- John -- Heather
Anyway, here are some URLs that should help you in your MLPPP quest if your ISP does infact support ML-PPP for dialup users.
http://www.google.com/search?hl=en&;ie=UTF-8&oe=UTF-8&q=setting+up+multilink+ppp+on+linux&btnG=Google+Search
--David
And thanks for the URL's. -- John -- Heather
power managementHello.
My new PC running Linux has the new Intel motherboard that supports only ACPI, not APM. I understand from the vendor that Linux does not support ACPI as yet. Hence, I can't put my machine in stand-by or sleep mode. The only solutions are to keep it running (room temperature gets high during day time ~80 degrees) or power off.
Is Linux planning to support ACPI any time soon? Are there other alternatives to power off? After all, one of the best advantages of Linux is that you don't need to boot it every time you want to use the machine. It can run for a long time without crashing.
Thanks.
SG
[Ashwin N] Linux has support for ACPI in 2.4.x kernels. I suppose it wasn't there in the older kernels.
You'll need to install/upgrade your Linux distribution/kernel.
Hello. Thanks for the prompt reply. I guess the vendor knows less about Linux than I do. He installed RH 7.3 with kernel 2.4.18-3 on the PC, which as you say supports ACPI. Unfortunately, it is not activated. In the directory /etc/rc.d/init.d I can find apmd but not acpid. Do I have to reconfigure/recompile the kernel to get it working. I checked up all the Linux How-Tos and FAQs and can't find any information about getting ACPI to work.
Thanks.
SG
[Rick Moen] Googling found this unofficial HOWTO: http://www.columbia.edu/~ariel/acpi/acpi_howto.txt
- It's linked from this summary page:
- http://mobilix.org/apm_linux.html
- And perhaps you've already come across the ACPI 4 Linux Project:
- http://acpi.sourceforge.net
Adding Win98 to a second HDO.K. I know this is a lame one but I don't want to mess up!
My children are now of the age that they are fighting over whose turn it is on the (old) computer - it has Windows 95 and (unfortunately) they like some of the silly games that children love - namely Mario (no I haven't found one to run under Linux).
So now I am under pressure to use my Linux box as a second Windows machine to satisfy the children (no funds for even a second hand 'puter).
On my Linux box I have two hd's, one 20 GB - the main one and a second one of 6 GB. I want to put Windows 98 on the second hd. How do I make sure that Windows uses the second hd and not wipe out my Linux one? Also how do I rescue the mbr from Windows after the install? - I'm using Mandrake 8.2 with Lilo.
Nigel Ridley
[JimD] Take out the Linux drive. Make it a slave. Install the smaller drive (as standalone at first). Install Win '9x. Change the smaller drive to be the master (if necessary) and re-install the big drive. (Leave a small non-DOS partition near the front of it if you can).
Now boot from a rescue CD or floppy specifying root=/dev/hdbX (as appropriate) and add the appropriate entries for an "other" stanza to your /etc/lilo.conf. Then run /sbin/lilo to install a new MBR on the little drive.
(The MBR on the big drive will be preserved, irrelevant until it's put back into a system as a master or standalone).
You might not need to use that small non-DOS partition that you created --- but I'd reserve it anyway (if the Win '9x installer will let you). You can boot from a Linux rescue disc or diskette to run Linux fdisk and mark the small partition as OS/2 or with some sort of hibernation volume type --- anything but Linux, since I hear that newer Microsoft releases with eradicate Linux partitions with extreme prejudice.
There are undoubtedly a multitude of alternative approaches. You could use GRUB and it's notion of "hidden" drives (to swap the identities of the two drives during the boot process, in memory). You might be able to install it (standalone) and then make it the slave (LILO) but I think MS Windows would get unhappy about not having a C drive.
[John K.] If one is resigned to using sharing the system with the rogue OS, then the above is another good reason to keep MSW straight-jacketed in an environment such as a virtual machine where it can't do any damage to things it has no business touching.
[JimD] I think John is thrying to suggest that you could use VMWare (or Plex86 if you're daring, or WINE) to run Win '9x as a process under Linux.
This works pretty well --- but has a few downsides that might apply to you're needs:
- VMWare needs lots of memory and plenty of CPU horsepower. If you machine is older (less than about a 650Mhz Pentium II or so) or doesn't have lots of memory (128Mb minimum, 512Mb won't be wasted) then you may find this approach acceptable.
- You might have relatively limited support for sound, USB joysticks, etc. You said you're kids are fighting over games (IIRC) and Windows' rehosted under a virtual machine and running a game is likely to be unpleasantly slow.
- VMWare is pretty good as a product. However it's not free -- purchasing it will more than double your cost over buying the requisite copy of Win '98. Plex86 (FreeMWare) is free but many not be up to the task of running the software you need nor supporting your hardware. It will certainly be more work (learning curve) on your part.
- You're kids may have to learn a little Linux/UNIX in order to get the VMWare (or other) virtual machine running and booted, possibly switching it to full screen mode and sometimes (perhaps) get back to it or out of it and back to the Linux host under various possible situations. You might make this all pretty transparent (they log in via xdm/gdm/kdm etc, it starts the VM session and then the just choose shutdown and they log back out).
However, it might be just what you're looking for. Take a look at these websites:
- VMWare:
- http://www.vmware.com
- WINE:
- http://www.winehq.com
- CodeWeavers (WINE related):
- http://www.codeweavers.com
- TransGaming (WINEX):
- http://www.transgaming.com
- Plex86 (FreeMWare):
- http://www.plex86.org
[Heather] They might enjoy TuxRacer, which I've actually seen in stores. Linux can also emulate Nintendos, Game Boys, and some other gaming systems -- you have lots of options.
If You're Not Part of the Solution, You're Part of the PrecipitateQuoting Dan Wilder:
Another spate of Klez worm reports to the victim, whose email
address is forged in the "From: " header of the virus-bearing mail.
I've started letting people whose autoresponders send me these misdirected advisories that they have one day to turn it off or disable it, after which they'll be permanently killfiled after the next offence.
Dear readers: If you don't know how to (or buy) an autoresponder that does competent SMTP header analysis, so you're sure it's sending virus advisories to the correct party, then you honestly have no business running one, and will end up causing large numbers of people to classify you as, in effect, a spammer and to act accordingly.
Trust me, you don't want to put yourself in that category -- and nobody's going to care about your protestations of meaning well.
autocad on linuxSaw your not yet. I am a mechanical engineer. I run autocad daily on linux using vmware. (Running SuSE 8.0 or 7.3, AMD 1.4 with 768 Mg) Works beautifully. Frequently I had 10 or 15 sessions of autocad running at the same time. Never a problem. Nice also when want to reload or update as from 7.3 to 8.0 simply copy the back the windows 2000 file. To me it is the preferrable way to run autocad.
-richard
ringing a bell when compilation is finishedHi:
I wanted to share a little bash function I put together to check for the status code returned by a process (typically "make"). After using IDEs which generate audio feedback after successful compilation, I realized that this could be done by a bash function, which I call "ok".
I typically run the function right after a long build like this:
make -f Makefile ; ok
It then returns a pleasant note if all went well, and something less pleasant if not. Here is the source:
[zorro@box84 build]$ cat /etc/profile.d/check_return_value.sh
#!/bin/sh
ok() {
if [ $? -eq 0 ]; then
play /usr/share/sounds/chord.au
echo " SUCCESS "
else
play /usr/share/sounds/warning.wav
echo " *ERROR* "
fi
}
Works every time (so far).
Configuring the GUI, the GUI wayHeather Stern wrote:
(In response to q querent having trouble with mice)
The section you are looking for in your /etc/X11/XF86Config-4 file (well, it might be in just plain /etc, but anyway) is "Pointer" for the mice declarations themselves and "ServerLayout" for the list of gadgets it will honor.
[Ben] You could also use "xf86cfg" if you like graphical tools. I've found that it takes a little getting used to, but is well done, and - once you understand the basic idea behind the layout - nicely intuitive.
[Heather] Ben presumes you use Debian. If you use RedHat, you'd want "Xconfigurator". If you use SuSE, the correct beastie is "SaX" and can also be found in the YaST menus.
On older distros there was a TCL/tk app called "XF86Setup" but it does nothing to help guess your video card or monitor characteristics. If you need this, a brief glance at the results of "lspci" is worth your while, and check your notes about what the maximum resolution is for your monitor, before you run the app. It's not very happy when you switch away from its task and back again.
The XF86Setup program, at least, has keyboard commands for everything, so it will work that way until you finally pick the right mouse protocol and can start clicking on things.
If you're afraid of jumping to graphical mode until you've got something like a useful config file created, "xf86config" is a totally text mode program, which asks you questions from the database of X gadgetry. But do make sure that it creates an XFree86 version 4.x file, and not a version 3.x file ... they are very different. The section "ServerLayout" mentioned above didn't exist in version 3.
Diald problems againI've got Debian 3.0 almost set up to my liking, but one thing I can't get to work is diald.
I installed Debian from scratch and pppd configuration was quite easy. "pon ntlworld" works, similarly kppp only required me to change auth to noauth in ppp.options and it worked. Diald OTOH has me puzzled.
Debian 3.0 has a completely new diald configuration. All the stuff that used to appear in /etc/diald has gone. The only configuration file it uses seems to be in /var/cache.
"ps aux" shows that diald starts up OK. "route" shows that it has set up sl0 as the default interface, but when I try to access anything on the internet I get an immediate DNS lookup failure. There are none of the usual messages in /var/log/messages indicating that it's trying to dial out and do a DNS lookup.
What have I tried?
- I've reconfigured it half a dozen times.
- I've tried "grep diald /var/log/*"
- I've copied my old /etc/diald from potato and selected "old-config" in "dpkg-reconfigure diald".
- I've copied the dialup rules from old standard.filters into /etc/diald.options
- I've read everything I could find about the new configuration in /usr/share/doc/diald
- I've google searched for "debian woody diald problem"
- I've searched the debian-user archives
Now I'm stumped. I could throw away the new /etc/init.d/diald script and import the old one potato, together with all the rest of the configuration for potato, but even if that works, I would prefer not to rely on an "obsolete" configuration.
But, about a week later, Neil solved it... -- Heather
I've got this working. It still doesn't work with the Debian 3.0 configuration, but I noticed that one difference from 2.2 was that there was no named running on 3.0. I installed bind and this together with the 2.2 configuration seems to have got it working.
Neil
I know that a few apps want to look up the local machine by hostname; I usually deal with this by adding /etc/hosts entries. But there are a handful of other advantages to using a local caching name daemon. If you need the cache to persist through reboots (bad power lines, maybe?) consider pdnsd. -- Heather
dual boot with XPHalloMy name is Debojit Acharya and i am from india. It will be highly apperciated if you kindly answer the questions furnished below :-1. I have a 10 GB hard disk with Win 98 installed on it. Now i want to Install Win XP and Red Hat Linux 7.2 on to a new 80 GB hard drive.
I have seen this succeed; it depends a little bit on whether your BIOS likes such large drives, but once you can get the OS' to see them they deal with the rest of the details pretty well.
I want to have multibooting feature with Win 98 (on the old 10GB HDD), Win XP and Linux (on the new 80 GB HDD) as OSs.
I don't know if mswin will let you boot XP from a second drive.
The easiest way by far for Linux, would be to have LOADLIN.EXE and a copy of your favored linux kernel sitting on the old win98 C: ... then just offer Linux as one of the mswin boot menu choices.
A floppy would work (for Linux at least; possibly for winxp but don't believe me ... check their knowledgebase).
How to go about it? 2. I had Mandrake Linux 8.2 installed on one of old HDD's partitions. Later i had tried to delete the partition by booting from the Mandrake bootable CD. Though the partition got deleted but had not been uninstalled properly because even now, at the system startup screen, the default OS is shown as Linux with Win 98 as the second choice. But after logging into Linux it gets hanged.
You still have the old LILO master boot record from the time when you had Mandrake on /dev/hda, however since Mandrake itself ... or more correctly speaking, that kernel ... is no longer there, the menu option goes to an explicit location on disk -- which no longer has a kernel!
If you store at least one Linux kernel on your /dev/hda drive -- for example, in C:\LINUX -- then you will be able to install a fresh LILO boot record which points at it, and knows about you wanting to mount a /dev/hdbN partition as your root volume when you select Linux. You must re-run /sbin/lilo, after editing /etc/lilo.conf to meet your new setup. Unfortunately, the kernel and bootloader really do have to be on the same disk.
If you switch to GRUB a different story follows, but it's still probably a good idea to keep a kernel on your first hard drive.
Pls help me get out of this.
Thanks. Bye,Debojit.
Hiding SAMBA sharesTake a look at this link it may help:
http://www.oreilly.com/catalog/samba/chapter/ch05.html
Look down the page to the section on Preventing Browsing (5.1.1)
O'Reilly's books are really great references for technical materials.
Hope this helps.
recompiling the kernel with a X11 keymapHello Answers Gang,
Is there a way to recompile the kernel so as to get the X11 keymap in the console?
See
linux/drivers/char/defkeymap.c
linux/drivers/char/consolemap.c
paying special attention to the comments at the beginning of defkeymap.c
However, it is not necessary to recompile the kernel. Your initialization scripts (in /etc/rc.d, /etc/rc.d/init.d, or /etc/init.d depending on your distribution) very likely have a call to "loadkeys" someplace in them. This loads a keymap at boot time. If not, you can easily add such. See
man loadkeys
Linux multilanguageHey Jim,
I was reading over some of your responses to people's problems and it seems you are pretty knowledgable of the linux os.
[Ben] These days, Jim sits by the fire in his slippers and points with his pipe to stuff he wants done... or something like that.
With quite a shell collection on the mantelpiece, I'd add. (Jim is our resident shell-script expert. He has no problem constructing shell pipelines several apps deep.) -- Heather
I was wondering if you could point me in the correct direction with an issue i am facing. I am looking to write a C program that will use some sort of API call to detect what language is installed on a linux box and then launch a correct web page. Does linux have an API? How do you find out these environment variables? I have been researching for hours and have come up empty. Any help would be very appreciated.
[Dan] No doubt Jim or somebody else has more info, but for starters, try
apropos locale
and the related manpages, for example
man 7 locale
A system's locale is set during installation, and controls among other things the multilanguage support built into many GNU programs using the "gettext" utilities. See also
man gettext
[Ben] Take a look at the LANG variable. It's somewhat odd (e.g., the default value for English is 'C' (???))
[Heather] I think the default value is 'C' and if you have a basically English distro that's the language you'll, ahem, C. You can specify one or another of the English variants but I've seen it cause some things to act weird - I assume the exact same weirdness they'd offer if I picked an international variant they dunno how to handle.
[Ben] ...but mostly it follows the ISO3166 standard for naming, e.g. "de", "fr", "kr", etc. It's also far from certain that everyone will have it set on their system. For example, I read a lot of Russian stuff, but leave my LANG at the default setting and execute specific programs with a local LANG definition:
LANG=ru_RU rxvt -n Muttley -e mutt -y
In my opinion, though, LANG is as close as you'll come to what you're looking for as is possible in the wild wooly world of Unix.
Re: exe to iso filesAnd if you're trying to write a Linux or otherwise generated ISO under Windows, you can see "Best of ISO Burning Under Windows" - Issue 68, 11th TAG article: http://www.linuxgazette.com/issue68/tag/11.html -- Heather
Interestingly enough, I discovered, apparently El Torito bootability is a feature of the image -- I burned those Linux BBC's from a bare ISO, no command switches to tell the Windows burner to make it bootable, and it Just Worked.
I hadn't realized that it was (in Linux terms) mkisofs, not cdrecord, that did that work.
[JimD] Yes, it's the -b option to mkisofs that does the trick (and it's obviously not necessary at record time --- though most other OS have software that integrate the mkisofs with the burn. I prefer the modularity of he Linux approach.
In retrospect it ought to be obvious, but I don't even want to admit to the amount of time I spent looking for that switch in my (by which I mean "my sister's") Windows burner software.
LJWNN Tech TipsWhen you ssh from a NAT network, do your connections mysteriously drop after a few minutes of activity?
Keep ssh connections up by adding
ProtocolKeepAlives 30
to your ~/.ssh/config file.
See man ssh_config.
|
...making Linux just a little more fun! |
 The Answer Gang
The Answer Gang
 By Jim Dennis, Ben Okopnik, Dan Wilder, Breen, Chris, and... (meet the Gang) ... the Editors of Linux Gazette... and You! |
 Greetings from Heather Stern
Greetings from Heather SternDear readers, welcome to October in the world of The Answer Gang.
Statistics: About 680 messages this month. I say "about" because I can't count spam that hit the filters, and I'm not counting admin notes that I spotted and put aside early. That's just the total I had to split.
Peeves of the month --or-- how not to get an answer:
- ask a question about printers, and don't bother to look at http://www.linuxprinting.org first. A lot of our answers are gentle pointers to HOWTOs, as we assume real newbies don't know about The Linux Documentation Project (http://www.tldp.org) yet, either.
If you have already looked at a a HOWTO, for a pumpkin's sake do not say "I looked at all the HOWTOs and it made no sense." That just makes us sad and worried that our own answers won't help you any either.
Tell us whatever phrases confused you, and tell us what sort of sense you expected of it. We may be inspired to "translate" the techie bits into English, or point you at the pre-requisite HOWTO that goes before it, which already does. Probably we'd copy the maintainer so that the clearer answer gets to help a lot more people. If so you could feel proud you'd helped the LDP by making it more readable- gosh, it's my first week of school, maybe those Answer Guys will do my homework for me. I dunno what the prof is talking about anyway, so I won't even rephrase he question.
"sure, give us your professor, we'll advise him on a few pointers to give you." Here's the first hint; try the class textbook. The second: if you don't understand the question ask the professor about it. It's his or her job to explain it to you; you pay the school good money for that.
Especially distressing were the ones who want us to pick their masters thesis for them. Research and new insights are the basis for handing out such a degree, right? So I'd think it needs a bit more research than firing a note off to a batch of linux gurus on some mailing list somewhere. You need some background, you need a topic, you need some actually interesting new theory, you need some ways to test or explore that theory, and then you need to make the paper presentable at an academic level. I suggest typing the keywords "linux" and "proceedings" into the nearest search engine, and following their examples for style, reading them for content, and considering whether they are aiming for the same academic audience or if you need a slightly different tone. Simmer with new ideas, garnish lightly with a conclusion, publish to taste. Keep notes throughout and have a complete bibliography so people can follow how you came to think of it all.
Not really a peeve at all, but rather interesting: Crossover questions with Microsoft OS' are up. On the other tentacle, awareness that they're talking to Linux people here is too. For the record two Knowledgebases might come in handy:
- ours -- http://www.linuxgazette.com/tag/kb.html
- theirs -- http://support.microsoft.com
No, we have no idea whether any MS varieties can boot off a second drive. We suggest swapping the disks. Linux will boot fine as long as the bootloader has a kernel on the same media. Even if that's a floppy with SYSLINUX, or a Windows install with LOADLIN.EXE lying around.
Here's a touch of what The Answer Guy himself (Jim Dennis) and I have been up to. We visited Portland, Oregon this weekend - meeting some old friends - and got a tip about this great recycling project, http://www.FreeGeek.Com. We swung by their offices and it's just the coolest thing... assuming that you find big boxes piles of discarded cards and monitors and so on fascinating, of course. We sure did
Anyways, they get people in the community involved in putting these old bits back together into wimpy little machines that Linux can still make usable. The stuff that's hopeless, they snip the heavy metals and chips out of for recycling. Meanwhile some folks who previously knew nothing about computers, except maybe "where's the on switch" are learning how to tell an ethernet card from a modem, and so on. There are probably other projects like this out there, too. I'd like to hear from a few of them.
Now on to some All Hallow's Eve fun.
We really had to start coughing while cleaning out the cobwebs this time. Not one, but two questions about copies of Red Hat so old the moths are stuffed and buzzing around with beards and canes. The answers weren't very tasty, so you'll be spared them.
For slimy worms we've been pestered by the Klez worm all month. See the Two Cent Tips for more on that. Ugh.
We do have some candy though.
Ghoulies and monsters, we've got a definition of the term daemon that might be particularly useful this month. Plus how to get 'em started. LAN stuff got you spooked? We've got some great notes to chew on. if you find uninterruptiple sleep bothers you, we'll tell you how to kill that ghost... probably! Mwa ha ha ha, ha ha! See you next month!
Issue 80 - The Mailbag -> Kylix - observationsTranslation (c) 2002 Santy
Answered By Faber Fedor, Ben Okopnik, John Karns, Mike Orr, Heather Stern
Hello!, I suppose that somebody already will have clarified this to you, but just in case...
(I am Spanish, and my English is not very good, I hope that it is sufficient to explain to me well...)
Kylix
Fri, 21 Jun 2002 14:37:51 -0400
Octavio Aguilar (oam from mail.cosett.com.bo)
translated by Mike Orr, except for one part by Heather Stern.
![]() !ah! Un comentario demonio (daemon )siguifica Dinamic access memory, estoy
equivocado?
!ah! Un comentario demonio (daemon )siguifica Dinamic access memory, estoy
equivocado?
Ah! A daemon commentary means dynamic access memory, or am I mistaken?
Octavio-- Sorry, I've never used Kylix. I just ran a demo once. I don't understand your second question. Memory is hardware; a daemon is software. And what's a "daemon commentary"?
[Santy] Here Octavio asks if daemon (demon is "demonio" in spanish) means "dynamic access memory" I believe that he thinks that daemon is an acronym ->"D-ynamic A-ccess EM-memory ON-???) or so, of course this mistaken, it cames from Day Monitor ¿yes?.
I believe that this clarifies your doubt, I hope...
![]() Intente bajar de internet el mismo paquete pero el resultado para instalarlo es el
mismo error.
(Heather: oboy, my spanish is rustier than Mike's, but I'll try.)
I intend to go under the internet to packets (maybe: download the package ?) but the
result of installing is an error.
Intente bajar de internet el mismo paquete pero el resultado para instalarlo es el
mismo error.
(Heather: oboy, my spanish is rustier than Mike's, but I'll try.)
I intend to go under the internet to packets (maybe: download the package ?) but the
result of installing is an error.
Bye!
![]() Santy writes:
Santy writes:
of course this mistaken, it cames from Day Monitor ¿yes?.
:daemon: /day'mn/ or /dee'mn/ /n./ [from the mythological
meaning, later rationalized as the acronym `Disk And Execution MONitor'] A program that is not invoked explicitly, but lies dormant waiting for some condition(s) to occur. ....
"Many people equate the word 'daemon' with the word 'demon' implying some kind of Satanic connection between UNIX and the underworld. This is an egregious misunderstanding. 'Daemon' is actually a much older form of 'demon'; daemons have no particular bias towards good or evil, but rather serve to help define a person's character or personality.
There's an anecdote about a priest who's conducting a funeral service. As the casket is about to be buried, an earthquake erupts, pushing the casket into the earth. "Chyort voz'mi!" ("The devil take it!") mutters the priest and continues the service, not realizing the literal meaning of that common expression.
The word daemon was first used as a computer term by Mick Bailey, a British gentleman who was working on the CTSS programming staff at MIT during the early 1960's. (footnoted: This bit of history comes from Jerry Saltzer at MIT, via Dennis Ritchie, via Kirk McKusick.) Mick quoted the Oxford Dictionary in support of both the meaning and spelling of the word. Daemons made their way from CTSS to Multics to UNIX, where they are so popular they need a superdaemon to manage them. Daemons are featured on the cover of the BSD UNIX manuals.
These figures [defining the personality] also appear prominently in Tibeten (and Hindu if I'm not mistaken) drawings called mandalas. Many of the mandalas have these figures painted in a circular or horse shoe pattern surrounding a central figure. At the moment I forget the term that they use to name the entities, but they are representative of universal characteristics of the subconscious, which every person who follows "the path" must master / transcend.
starting services in "/etc/init.d"From Benjamin A. Okopnik
Answered By Jay R. Ashworth, Mike "Iron" Orr, John Karns, Jim Dennis
There are a number of services available in "/etc/init.d" that I use only occasionally - "pdnsd" and "ntpdate", for example - and so they're not auto-started in my "/etc/rc*.d". In order to save myself repeatedly typing
su -c '/etc/init.d/pdnsd start'
"stop", etc., I decided to make the command line a bit clearer via the following script:
See attached okopnik.usr-local-bin-start.bash.txt
After creating it, I made a number of symlinks to it:
cd /usr/local/bin for n in stop reload restart force-reload; do ln -s start $n; done
Now, all I have to do is type an action followed by the service name, like
reload pdnsd start fetchmail stop mysql
etc., as root (or invoke it via "su"). More obvious, less typing.
![]() <shrug> It's easy enough to modify for other "rc.d" variants. The
important thing here was the idea, and the, erm, "source" is available.
<shrug> It's easy enough to modify for other "rc.d" variants. The
important thing here was the idea, and the, erm, "source" is available.
![]()
function start () { /etc/init.d/$1 start ; }
function stop () { /etc/init.d/$1 stop ; }
function reload () { /etc/init.d/$1 reload ; }
function restart () { /etc/init.d/$1 restart ; }
function ctest () { /etc/init.d/$1 ctest ; }
Also easier to type than 'service start'....
(I assume bash works the same way?)
![]() You need to have semicolons on the ends...
You need to have semicolons on the ends...
which I added. -- Heather
{ echo }
... is that a complete command group (in the braces) or is it a fragment including the beginning of a command group (the opening brace) followed by an echo command (which will print out a close brace character, and a newline)?
Alternatively the command line:
{ echo ; }
... is unambiguous.
![]() It's an "sh"-ism, too. You need one because it terminates a group command. From the "bash" man page:
It's an "sh"-ism, too. You need one because it terminates a group command. From the "bash" man page:
{ list; }
list is simply executed in the current shell environment.
list must be terminated with a newline or semicolon. This is
known as a group command.
It doesn't work in .bashrc. Remember that you have to "su" to run them:
Baldur:~$ ztart() { /etc/init.d/$1 start; }
Baldur:~$ su -c 'ztart pdnsd'
Password:
bash: ztart: command not found
Baldur:~$ typeset +f | grep -A3 ztart
ztart ()
{
/etc/init.d/$1 start
}
![]() The point here is that doing it the way you suggest makes it more
complex (dependent on whether you did "su" or "su -", for example) and
more fragile. I suppose you could always put it in "/etc/profile"...
uh, nope, that would break for "csh", "tcsh", etc. users. This is one
of those cases where a script is simply better.
The point here is that doing it the way you suggest makes it more
complex (dependent on whether you did "su" or "su -", for example) and
more fragile. I suppose you could always put it in "/etc/profile"...
uh, nope, that would break for "csh", "tcsh", etc. users. This is one
of those cases where a script is simply better.
No idea what you mean by "convoluted syntax", but the same reasoning applies.
zsh$ echo {}
{}
zsh$ echo {
{
zsh$ echo }
zsh: parse error near `}'
(or something like that). This is probably a bug in zsh (with regards to Bourne and Korn shell compatibility. As I say, it was considered to be a bug in bash that was noted in a change log for 2.x.
All of that hairsplitting aside I must say that this is one of the most annoying changes in bash 2.x. Like many other shell scripters I'd gotten into the habit of using constructs like { ...; foo } and I still get bitten by it occasionally. (Note that in this example foo is being called with an argument of } (closing brace) and the group is incomplete. We must insert a semicolon or a newline (command separators) for it to parse correctly.
![]() I'd simply learned it as "this is the way it's done"; I guess I came to
it fairly late. One thing that I remember annoyed the hell out of me
early on: trying to launch two progs and background the first one;
seemed like an obvious thing to do
I'd simply learned it as "this is the way it's done"; I guess I came to
it fairly late. One thing that I remember annoyed the hell out of me
early on: trying to launch two progs and background the first one;
seemed like an obvious thing to do
prog1 &; prog2
- right? Wrong! Only later did I realize that '&' was a valid
terminator, just like ';' and newline. Oh, and trying to explain the order in
prog > /dev/log 2>&1 &
to my students involves removing their brains and installing them upside down...
![]() <snort> Indeed.
<snort> Indeed.
See attached karns.usr-local-sbin-start.sh.txt
but I put it all in /usr/local/sbin, since it has to run as root
lrwxrwxrwx 1 root root 9 Dec 7 2001 /usr/local/sbin/start -> initScrpt*
|
............... ............... |
This should chop off 5 fields worth of text, delimited by slashes. Any time you see fixed numbers while doing string handling, you should beware that it won't work for the general case. -- JimD
![]() Yikes! Highly breakable (try invoking it from its own directory, one
level above it, etc.) How about just "${0##*/}" instead? That'll work
every time.
Yikes! Highly breakable (try invoking it from its own directory, one
level above it, etc.) How about just "${0##*/}" instead? That'll work
every time.
This offers to chop everything up to the last slash, and leave the last part, whatever it is. Also it's a built-in. But that may be true only for bash... and probably ksh. The rest is left as an exercise in shell debugging, but those of you who prefer working code should just skip to the end. -- JimD
|
............... ............... |
![]() Has this ever worked for you? I'd be very surprised if so; $0 will never
equal just "stop" (it'll be "./stop" at the very least.)
Has this ever worked for you? I'd be very surprised if so; $0 will never
equal just "stop" (it'll be "./stop" at the very least.)
jkInsp8000:~ # stop nscd Shutting down Name Service Cache Daemon
![]() Doesn't work for me. Obviously, something in your script is tripping off
"stop", but I see no way that it can be the above "if" statement.
Doesn't work for me. Obviously, something in your script is tripping off
"stop", but I see no way that it can be the above "if" statement.
See attached okopnik.testing-karns.sh-transcript.txt
CMD=`echo $0 | cut -f5 -d/` echo "CMD = $CMD" exit 0
... then ran the tests
..from root's home dir:
jkInsp8000:~ # stop nscd CMD = stop
..from the scripts own dir:
jkInsp8000:~ # cd /usr/local/sbin/ jkInsp8000:/usr/local/sbin # stop nscd CMD = stop
..and from one level above:
jkInsp8000:/usr/local # stop nscd CMD = stop
![]() Mine acts completely differently
Mine acts completely differently
![]()
Baldur:~$ cat << ! > /usr/local/bin/tst1 > CMD=`echo $0 | cut -f5 -d/` > echo "CMD = $CMD" > exit 0 > Baldur:~$ chmod +x /usr/local/bin/tst1 Baldur:~$ tst1 CMD = Baldur:~$ cd /usr/local/bin Baldur:/usr/local/bin$ tst1 CMD =
Doesn't work for me, John. I can't see how it would work for you. If one of the other Gangsters wants to try it out, cool, but I don't see how it's even possible (unless you have another script, alias, or function called "stop".) Here is a simple test:
echo "./foo" | cut -f5 -d/
If you get "foo" out of that, then your "cut" is doing something magical. Or maybe it's "echo". Of course it could always be gremlins.
Just out of curiosity - you are copying and pasting (NOT retyping) the code, yes?
![]() I didn't think you had, but I was wondering about your gremlins. You
just never know.
I didn't think you had, but I was wondering about your gremlins. You
just never know.
jkarns@jkInsp8000:~ > grep gremlin /etc/passwd gremlin:x:0:666:i_gotz_r00t:/proc/bus/pci/...:/bin/bash
![]()
GNU bash, version 2.04.0(1)-release (i386-suse-linux) Copyright 1999 Free Software Foundation, Inc.
Running your test:
jkarns@jkInsp8000:~ > echo "./foo" | cut -f5 -d/ jkarns@jkInsp8000:~ >
![]() OK, in that case, here's a guaranteed way to break it:
OK, in that case, here's a guaranteed way to break it:
cd /wherever/the/script/is ./stop
I can promise you that it's going to fail.
![]() Same story if you ever
move it into a directory that's "deeper" or "shallower" than the current
one (*there's* a hell of a problem to troubleshoot!) If you use
"${0##*/}", or even "echo $0|sed 's#.*/##'", that fragility goes away.
Same story if you ever
move it into a directory that's "deeper" or "shallower" than the current
one (*there's* a hell of a problem to troubleshoot!) If you use
"${0##*/}", or even "echo $0|sed 's#.*/##'", that fragility goes away.
Or get really lazy and just use "basename" which is designed for this. -- JimD
See attached debugged.usr-local-sbin-start.sh.txt
A LAN QuestionFrom santyx
Answered By Ben Okopnik, Karl-Heinz Herrman, John Karns, Jim Dennis, Matthias Posseldt
Hello Gang!!! Thanks and congratulations for your good work!!!
I'm Santiago (santyx), from San Rafael-Mendoza-Argentina. I don't speak English very well, but I hope you understand my question. I'm working in a LAN in my University and I've installed a Red Hat Linux 7.1 in my work station (puesto17). The LAN looks like this:
See attached map-university-network.txt
Where SANRAFAEL is a WINDOWS NT server for the 192.168.2.X subnet and CHARLY
is a SuSE LINUX server for the 192.168.1.X subnet. SANRAFAEL is connected to the Internet, and allowing all the work stations in the network to connect to the Internet too, with a proxy software. As you see, I don't have a direct connection to the Internet from puesto17. I can do "ping" to 192.168.1.X or 192.168.2.X, but I can't do "ping", for example, to http://www.argentina.com if I want. I can do "traceroute" to 192.168.1.X or 192.168.2.X, but I can't do "traceroute", for example, to http://www.hotmail.com if I want. I can do "ftp" to 192.168.1.X or 192.168.2.X, but I can't do "ftp", for example, to my ISP to upload web pages if I want. I can't connect to the News Servers in the Internet and I can't use my pop3 mail server from my work station. I can't go out of my network!!!
Which is the best way to change this? Can I change this from my Linux box? Or the only way is changing the things in the SANRAFAEL Server?
I really need a solution, specially for the FTP, since I'm working in a web site for my University.
Thanks in advance!!!. Santyx.
It sounds like SANRAFAEL is running a firewall that's blocking (at least) ports 7 (echo), 21 (ftp), 110 (pop), and 119 (nntp). Your system administrator would have to open those for you.
Another possibility, depending on how your proxy is set up, is that you might also be able to get out through that proxy. To do that, you'd have to define some environment variables:
# Most programs want this in lowercase, but there are some that want it # capitalized! export http_proxy=http://x.x.x.x:y export HTTP_PROXY=http://x.x.x.x:y export ftp_proxy=http://x.x.x.x:y export FTP_PROXY=http://x.x.x.x:y
'x.x.x.x' is the IP address of the proxy; 'y' is the proxy port.
Note that the "http://" part of the proxy location stays the same even when you're defining an FTP proxy. Strange, but that's how it works.
Again, this is only a possibility; you'd have to discuss the setup with your system administrator to be sure.
What happens if you do all your tests from Charly? Charly probably also has no internet connection (besides the http proxy).
Also for ftp through firewall make sure you run ftp in "passive" mode. For ftp originally the server was opening a connection back to your client on a different port -- which usually fails for through firewalls (so might not fail with recent firewall port masquerading). On a "recent" *nix ftp client typing "passive" before trying to "ls" or get/put will do.
But I guess (like Ben) that the NT box is blocking you.
![]() Hello Gang!!!
Santyx again.
Thanks for your answers about "A LAN Question"
The net admin of my University made the changes in the sanrafael server,
and now I can do telnet from
my work station, but I can't do FTP.
When I connect to sanrafael doing FTP from Linux the proxy answer well,
the connection is done.
But the commands don't answer and I got to kill the connection from another
console.
It doesn't happens from windows.
Hello Gang!!!
Santyx again.
Thanks for your answers about "A LAN Question"
The net admin of my University made the changes in the sanrafael server,
and now I can do telnet from
my work station, but I can't do FTP.
When I connect to sanrafael doing FTP from Linux the proxy answer well,
the connection is done.
But the commands don't answer and I got to kill the connection from another
console.
It doesn't happens from windows.
If that works than you probably have a problem with your firewall (or packet filters) that rejects "active" mode FTP connections.
In FTP the session you establish is a control channel, it's used to send your FTP client's commands (you say "get" and your client changes that to RETR, you say "ls" and your client sends 'LIST' or 'NLIST', or whatever). The response codes (numeric and text) are also returned on this control channel (which is on destination port 21 on the server from some unprivileged port on your client host).
In active FTP the FTP server attempts to create a data connection for each stream of data that you get. That includes each file that you fetch, of course. However it also includes connections for directory listings. The problem is that most firewalls and packet filters block inbound connections (from the FTP server back towards your client) on low numbered (privileged) ports.
With passive FTP the client specifies a non-privileged port (greater than 1024) for the data channels. The back channel is still inbound from the server back to the client. The difference is that the client specificies an available port (by sending a PORT command over the control connection). That works with most packet filter configurations and firewalls. However, it won't necessarily work with all of them.
In most FTP clients you can set passive mode by typing a command like "quote pasv" (in ncftp you can use the command "set passive").
If a web browser works using an ftp://.... url, then passive mode from your FTP client should work as well. Most web browsers default to passive mode. If passive mode doesn't work, then you may need to use a proxy system. I won't go into details on those --- you'd be best checking with your local system/network administrator if you think you need that.
Occasionally I've found other causes for the situation you describe. However, they are much less likely. In one case I found that it was related to MTU (maximum transmission units). Web and other traffic would work, but FTP data connections would fail (apparently because it was more likely to use maximum sized packets --- due to its socket options).
I doubt you'll encounter this sort of problem.
![]() I got another question.
It's about GNU Grub.
I've installed the 0.92 version to load win98 and Red Hat Linux 7.1
Everithing goes O.K, but I want to make a graphic menu and I can't.
I put the following line in the menu.lst to show a graphic file
I got another question.
It's about GNU Grub.
I've installed the 0.92 version to load win98 and Red Hat Linux 7.1
Everithing goes O.K, but I want to make a graphic menu and I can't.
I put the following line in the menu.lst to show a graphic file
splashimage=3D(hd0,1)/boot/grub/fun.xpm.gz
Where (hd0,1) is the Linux partition and /boot/grub/fun.xpm.gz is the path of the graphic file. The image is 640x480, 4 colors.
But nothig happens. How can I make my own menu for Grub?
Thanks again. santyx
Homework question: defining subnetsFrom Darren Collins
Answered By Faber Fedor, Frank Rodolf, Jim Dennis
How do you specify the first 6 & last 2 available subnets defined by the IP address and subnet mask (155.25.0.0/23) Any help on this would be greatly appreciated.
Sincerly, Darren
BTW, we don't do homework assignments around here, except for our own, of course.
This is a bit-aggregation (supernetting) over the traditional "class C" sized network. Normally people would go for a 4-bit aggregation --- giving them 16 networks of about 4000 hosts each (and possibly fanning those into class C sized networks through another hierarchical layer of routers).
thx for ur ncurses, u have networking howto?From deepak a.l
Answered By Pradeep Padala, Heather Stern
The original subject had been:
hi mr pradeep padala need help free source code for a networking project under linux topics like ppp -- Heather
hi pradeep padala
im deepak from bangalore , a very good lover of linux and its extra features ,me and my batch mate are doing a project on "networking using linux as a platform"" plese help me out regarding this regard,ur howto ncurses programming helped us a lot for building up the editor,thanks for the ncurses programming ,it was helpful ,
so i wanted to ask u whether u have "Networking Howto"
- Net-Howto:
- http://www.tldp.org/HOWTO/Net-HOWTO/index.html
- Networking-Howto:
- http://www.tldp.org/HOWTO/Networking-Overview-HOWTO.html
We have had other good messages on networking topics too. These are mentioned in the Answer Gang Knowledgbase: http://www.linuxgazette.com/tag/kb.html
While most of the questions asked of us are about configuring the network to be visible, certain kinds of questions lead to a discussion of how it works under the hood. Many are laden with additional URLs well worth reading into. But I'd say a fair number of them mention the HOWTOs that Pradeep listed above.
![]() plese help us out ,we want to do well in our project
with ur wishes, plese let me know as soon as possible
of networking projects sites offering free source code
or any thing tutorial written by u regarding
networking under linux, i mean the manpages which
display help for networking,
plese help us out ,we want to do well in our project
with ur wishes, plese let me know as soon as possible
of networking projects sites offering free source code
or any thing tutorial written by u regarding
networking under linux, i mean the manpages which
display help for networking,
For source code you can have a look at various projects at http://freshmeat.net and http://sourceforge.net
Good luck
![]() we would be really
thankful to u if u please help us in this regard
i mean if u have a documentation or example source
code which could help us in building the networking
project ,please suggest me some sites reagading
networking,pleaseeeee
we would be really
thankful to u if u please help us in this regard
i mean if u have a documentation or example source
code which could help us in building the networking
project ,please suggest me some sites reagading
networking,pleaseeeee
regards
deepak sanjay
from Bangalore
thank u!!!
|
............... Forwarded Message can u tell me how the data packets are sent from one pc to other in a LAN. in other words about the tcp ip in linux. lastly if u have any code in c or cpp to do this job. That's quite a broad question. Gurus like Richard Stevens, Douglas E Comer wrote atleast three volumes each on this topic. I suggest you read Richar Stevens' "UNIX Network Programming" book. If you want to know about socket programming(I guess that's what you mean by c code), there are plenty of articles on web. Google.com is the best place to search. This is one of the articles I found http://www.scit.wlv.ac.uk/~jphb/comms/sockets.html If you want to learn how TCP/IP implementation in Linux, best way to do is to look through source which can be browsed online at http://lxr.linux.no. Apart from that, the following document can give you some info http://www.cs.unh.edu/cnrg/gherrin ............... |
How to kill a process in uninterruptible sleep state?From Carlos Garada
Answered By John Karns, Ben Okopnik, Karl-Heinz Herrmann, Jay R. Ashworth, Robos, Jim Dennis, Ashwin N
Dear answer gang:
Sometimes when I mount a CD, mount hangs. ps shows it is
in an "uninterruptible sleep", and kill won't kill it. As a
result, I can not access my CD drive until I restart my computer.
Is there a way to kill a process in uninterruptible sleep?
Thanks!
C. Garada
![]() Sometimes the parent process is apt-get. I kill it, but the spawned
mount remains in state "D" and I can not kill it.
Sometimes the parent process is apt-get. I kill it, but the spawned
mount remains in state "D" and I can not kill it.
![]() Yes, I tried kill -9 and fuser -k /cdrom/... Nothing works.
Yes, I tried kill -9 and fuser -k /cdrom/... Nothing works.
![]() I suppose the mount(2) syscall is having a problem... but shouldn't I
be able to interrupt a system call in some way?
I suppose the mount(2) syscall is having a problem... but shouldn't I
be able to interrupt a system call in some way?
Thank you for your answers.
Tape drives are famous for this... they seem to be implemented as fast devices, even though they manifestly are not.
![]() So reboot is the
only answer? The almighty root can not do anything?
So reboot is the
only answer? The almighty root can not do anything?
![]()
Slow-device drivers -- for things like terminals, and such -- are usually split in two pieces, and can therefore be interrupted while they're in the middle of something.
Fast-device drivers -- which service things like hard drives and (I think) ethernet cards -- are designed to expect that when they call out to hardware, it will respond instantly (in human terms), and that they won't have to wait on anything. Such drivers have, as a rule, proven extremely intolerant of hardware trouble -- if your hard drive start having to do hardware retries to read a sector, your system perfromance is going int he toilet, even if you have more than one drive...
![]() Thank you for your explanation, Jay. So I suppose I should either resign
myself to rebooting every time it happens, or rewrite the driver...
Thank you for your explanation, Jay. So I suppose I should either resign
myself to rebooting every time it happens, or rewrite the driver...
Hope this helps.
![]() A day and a half... and then lost my patience
A day and a half... and then lost my patience
![]() .
.
Hunh. Robos may not be impressed, but I am. -- Heather
One thing we haven't mentioned here...
Occasionally, you'll get lucky, and rmmod will permit you to remove whichever module supports the device you're having trouble with... and then your stuck process will go away. I've had luck with this, particularly, on the SCSI CD-R attached to my laptop with an Adaptec APA-1460 PCMCIA card...
Now, that could be because PCMCIA busses are natively hot-pluggable, but...
Such a process cannot be killed --- it would risk leaving the kernel in an inconsistent state, leading to a panic. In general you can consider this to be a bug in the device driver that the process is accessing.
Once case that I can't consider to be a Linux bug occurs when one is attempting to access a hard mounted NFS exported share without the intr (mount(
When it comes to scsi and similarly local device drivers --- I would report cases of "D" state as bugs (after due diligence of checking for prior reports, updates, and perhaps trying to troubleshoot it a bit).
![]() Where? In the linux kernel mailing list?
Where? In the linux kernel mailing list?
![]() Sometimes, when I mount the cdrom, mount hangs and I can not kill
it; and I can not access the cdrom either. Ah, and the door remains
closed and I can not open it.
Sometimes, when I mount the cdrom, mount hangs and I can not kill
it; and I can not access the cdrom either. Ah, and the door remains
closed and I can not open it.
![]() How to reproduce it: I don't know
How to reproduce it: I don't know
![]() . I tried hard yesterday but this
bug won't show when I want it to.
. I tried hard yesterday but this
bug won't show when I want it to.
![]() Kernel 2.4.17.
Kernel 2.4.17.
Ah, and maybe important (I only thought of this now, sorry): I have a binary kernel module and a binary X server (not source available) for my nVidia graphics card. Maybe they are corrupting the memory and this affects the driver(?)? I know these binary components are not very good because the computer hangs on some GL screensavers... but I never thought they could make the ide/cdrom/whatever drive go wrong.
Could that be the problem?
If this problem happens only with the CDROM drive, then _maybe the drive is faulty. If you have 'the other OS' you could boot it up and put in a CD and check for similar symptoms.
I don't believe I've ever seen this sort of wedge on a CD-ROM drive but I have seen it happen to a PCMCIA card -- a NIC interface that was too new, and being spotted as the wrong card. Luckily I could ignore that until I felt inclined for a reboot for some other reason.
Oh yeah, since your troubles include a mountpoint -- walk through your shutdown sequence by hand. You'll find 'umount -a' is not going to behave itself-- Heather
![]() [John K.]
I have a related problem when resuming from APM suspend on my laptop.
Since I updated the BIOS it resumes without hanging as it used to do, but
the NIC (eepro100) doesn't get reset; and unloading / reloading the NIC
driver doesn't help, so I'm stuck with rebooting if I want to connect to a
LAN after suspending.
[John K.]
I have a related problem when resuming from APM suspend on my laptop.
Since I updated the BIOS it resumes without hanging as it used to do, but
the NIC (eepro100) doesn't get reset; and unloading / reloading the NIC
driver doesn't help, so I'm stuck with rebooting if I want to connect to a
LAN after suspending.
{{{ John, have you tried unplugging/reinserting the card (I'm assuming it's PCMCIA)? That's what used to work for me when this happened back in the 2.2 kernel. {{{{
A while ago someone told me that there was talk of the eepro100 reset problem on the kernel dev list, and that there may a patch or fix for it - maybe in the 2.4 kernel. I'm still using 2.2 kernel, mainly because of VMWare - will have to re-install the MSW I have setup in virtual partitions - something that I've been putting off until I have enough time to deal with it all.
http://volker.orcon.net.nz/linux/vmware/vmware2.0.4-SuSE7.3.txt
|
...making Linux just a little more fun! |
By Michael Conry |

|
Contents: |
Submitters, send your News Bytes items in PLAIN TEXT format. Other formats may be rejected without reading. You have been warned! A one- or two-paragraph summary plus URL gets you a better announcement than an entire press release. Submit items to gazette@ssc.com
 October 2002 Linux Journal
October 2002 Linux Journal
![[issue 102 cover image]](misc/bytes/lj-cover102.png) The October issue of Linux
Journal is on newsstands now.
This issue focuses on Security. Click
here
to view the table of contents, or
here
to subscribe.
The October issue of Linux
Journal is on newsstands now.
This issue focuses on Security. Click
here
to view the table of contents, or
here
to subscribe.
All articles older than three months are available for
public reading at
http://www.linuxjournal.com/magazine.php.
Recent articles are available on-line for subscribers only at
http://interactive.linuxjournal.com/.
Venezuela and Other Government News
The Register reported that Venezuela has adopted a pro-GPL policy for government software. All software developed for the government must be GPL, and GPL is preferred for off-the-shelf software. As described in LinuxToday's coverage, it would appear that Dr. Felipe Pérez-Martí, Venezuelan Planning and Development Minister is well acquainted with open-source, free software and the ideas behind these buzz words.
Use of Open Source has also been recommended by a South African Government Advisory body. The Ukrainian government is also considering expressing legal preferences for open source solutions.
On a third front, the UK Commission on Intellectual Property Rights, has concluded that open source and avoidance of restrictive licensing conditions is essential to developing countries future progress. This report was also covered by Linux Weekly News and by the Economist.
FSF changes focus
NewsForge has reported that The Free Software Foundation is changing its priorities to focus less on development, and to concentrate more on fighting digital rights management and enforcing the GPL. At the same time, Richard Stallman is planning to take a lower profile role in the organization.
Richard Stallman has recently written on the issues of open-source, free software, and security. The article takes the form of an open letter responding to an earlier contribution by SecurityFocus' Jon Lasser. He asserts the importance of being mindful of the very political underpinnings of free software, and the differences between what is meant by the terms free software and open source software. Now, if only we could all remember to say GNU/Linux!
Palladium
Two documents worth reading regarding Microsoft's Palladium project, and potential future ramifications are the guides written by Ross Anderson and by Seth Schoen.
Adobe Bitten by DMCA
Linux Weekly News have a commentary on an ironic development whereby Adobe is being attacked using the DMCA for a feature included in Acrobat which could be construed. Meanwhile, Wired report that Elcomsoft have not allowed their DMCA difficulties to cramp their style and are continuing to sail perilously close to the wind in their software development.
While on the topic of the DMCA, Robert Cringely has published an interview with Mark Ishikawa, a prominent enforcer of the DMCA. Also of interest is LawMeme's dissection of Cornell's DMCA Policy (courtesy NewsForge).
Some links of particular interest from the O'Reilly stable of websites:
Some links from Linux Weekly News:
Some links from Slashdot which might be of interest:
RPM PBone is a searchable index of RPMs, and an alternative to Rpmfind.
Salon report on how recycled PC's can be a tool of anti-globalization and empowerment.
Moblix.org have released a Linux Infrared-HOWTO, providing an introduction to Linux and infrared devices and to the software from the Linux/IrDA project.
OSNews article on Gentoo Linux.
Some links from Linux Journal
Some links from The Register:
Listings courtesy Linux Journal. See LJ's Events page for the latest goings-on.
|
O'Reilly Mac OS X Conference | September 30 - October 3, 2002 Santa Clara, CA http://conferences.oreillynet.com/macosx2002/ |
|
IBM eServer pSeries (RS/6000) and Linux Technical University | October 14-18, 2002 Dallas, TX http://www-3.ibm.com/services/learning/conf/us/pseries/ |
|
SANS Network Security | October 18-25, 2002 Washington, DC http://www.sans.org/ |
|
Strictly Business Solutions Expo | October 23-24, 2002 Houston, TX http://www.strictlyebusiness.net/ |
|
Third LCI International Conference on Linux Clusters: The
Linux HPC Revolution | October 23-25, 2002 St. Petersburg, FL http://www.linuxclustersinstitute.org |
|
USENIX 16th Systems Administration Conference (LISA) | November 3-8, 2002 Philadelphia, PA http://www.usenix.org/ |
|
SuperComputing 2002 | November 16-22, 2002 Baltimore, MD http://www.sc2002.org/ |
|
COMDEX | November 18-22, 2002 Las Vegas, NV http://www.comdex.com/fall/ |
|
SD East | November 18-22, 2002 Boston, MA http://www.sdexpo.com/ |
|
USENIX 5th Symposium on Operating Systems Design
and Implementation (OSDI) | December 9-11, 2002 Boston, MA http://www.usenix.org/ |
|
Consumer Electronics Show | January 9-12, 2003 Las Vegas, NV http://www.cesweb.org/ |
|
LinuxWorld Conference & Expo | January 21-24, 2003 New York, NY http://www.linuxworldexpo.com |
|
O'Reilly Bioinformatics Technology Conference | February 3-6, 2003 San Diego, CA http://conferences.oreilly.com/ |
|
Game Developers Conferenc | March 4-8, 2003 San Jose, CA http://www.gdconf.com/ |
|
SXSW | March 7-11, 2003 Austin, TX http://www.sxsw.com/interactive |
|
COMDEX Canada | March 11-13, 2003 Vancouver, BC http://www.comdex.com/vancouver/ |
|
CeBIT | March 12-19, 2003 Germany http://www.cebit.de/ |
|
4th USENIX Symposium on Internet Technologies and Systems | March 26-28, 2003 Seattle, WA http://www.usenix.org/events/ |
|
AIIM | April 7-9, 2003 New York, NY http://www.advanstar.com/ |
|
SD West | April 8-10, 2003 Santa Clara, CA http://www.sdexpo.com/ |
|
COMDEX Chicago | April 15-17, 2003 Chicago, IL http://www.comdex.com/chicago/ |
|
USENIX First International Conference on Mobile Systems,
Applications, and Services (MobiSys) | May 5-8, 2003 San Francisco, CA http://www.usenix.org/events/ |
|
USENIX Annual Technical Conference | June 9-14, 2003 San Antonio, TX http://www.usenix.org/events/ |
|
CeBIT America | June 18-20, 2003 New York, NY http://www.cebit-america.com/ |
|
O'Reilly Open Source Convention | July 7-11, 2003 Location: TBD http://conferences.oreilly.com/ |
|
12th USENIX Security Symposium | August 4-8, 2003 Washington, DC http://www.usenix.org/events/ |
|
LinuxWorld Conference & Expo | August 5-7, 2003 San Francisco, CA http://www.linuxworldexpo.com |
XVID and GPL
The XVID project scored a GPL win by persuading Sigma Designs to cease infringing on GPL'ed code developed by the group. 24 hours after the XVID team announced they would cease all future development of the project, Sigma Designs relented and made their sources available.
Slapper
Slashdot noted the emergence of two new Linux worms, Slapper.B and Slapper.C, which exploit a buffer overrun in OpenSSL. If you haven't upgraded to OpenSSL 0.9.6g (or at least e), now is a good time. A guy suspected of being the original Slapper author has been arrested.
Noel Davis at O'Reilly has recently looked at the Linux Slapper worm and other vulnerabilities.
Bruce Perens
As mentioned last month, Bruce Perens has left HP. As reported by The Register this split was quite amicable, but it stemmed from Bruce's policy of openly confronting and "baiting" Microsoft. Taking advantage of his new freedom, Perens has launched the Sincere Choice initiative, a reaction to Microsoft's Software Choice, which he earlier denounced as a sham. Newsforge have an interview with Perens where he expands on the ideas behind his new project.
Debian
Debian Weekly News reported on a Security Notification Script announced by Rob Bradford. The script compares locally installed packages with those on security.debian.org, and provides a description of the problem and the name of the Debian advisory if the package is mentioned in the DSA RDF file.
Those who own an X-Box, may want to try running Debian on it.
Linux From Scratch
The first test release of the upcoming LFS-4.0 book is uploaded and available for download now. Head over to http://www.linuxfromscratch.org to view and/or download it.
SuSE
the latest SuSE Linux version, SuSE Linux 8.1, will be available by the beginning of October.
UnitedLinux
UnitedLinux, founded by Linux industry leaders Conectiva S.A., The SCO Group, SuSE Linux AG, and Turbolinux, Inc., have announced the appointment of Paula Hunter, an experienced technology executive and consortium leader, as its worldwide general manager. Hunter's appointment is effective immediately. The group also announced the open availability of the beta version of its UnitedLinux product on Sept. 23. The open beta source code is available for download at no charge from download.unitedlinux.com.
Unfortunately, UnitedLinux has lost some goodwill among the open-source development community, and in particular the Free Software Foundation which published an open letter expressing concerns about UnitedLinux's closed beta and the manner in which it was distributed. UnitedLinux member Connective has responded to these concerns.
WinLinux
WinLinux 2003 is a major upgrade of the WinLinux system. WinLinux is claimed to be fully compatible with Windows 95/98/Millennium. WinLinux is also compatible with Red Hat Linux on the Linux side offering the benefits of both systems. WinLinux 2003 full version on CD with online support can be ordered from the website.
Xandros
Slashdot linked to the story on OSNews previewing beta 3b of Xandros Desktop. Xandros is the current custodian of what once was Corel Linux.
Linux Game Publishing News Mailing List
Linux Game Publishing has announced a partnership with Pyrogon Inc. to bring their latest games to the Linux market. This process will begin with Candy Cruncher, a fast paced puzzle game. Please see the press release for details.
TinyTERM 4.3
Century Software has announced the release of TinyTERM Version 4.3. TinyTERM lets you use your Windows PC to easily and accurately access character based data and applications hosted on UNIX, Linux and IBM servers. It includes 20 emulations, network utilities, secure file transfer and free technical support. TinyTERM is available for download
Kerio MailServer with integrated McAfee anti-virus program
Kerio Technologies are offering a Linux based mail server product, the Kerio MailServer 5.1.6. It has an integrated McAfee anti-virus program, and runs on Linux RedHat. KMS offers a broad range of features and a user-friendly interface in one package. Kerio claim that no other comparable solution has the McAfee Anti-Virus program integrated.
IBM alphaWorks posts porting manager
AlphaWorks has posted a free "porting manager" that enables the porting of C and C++ applications from Solaris to zSeries Linux, ensuring fast deployment of applications to the Linux platform.
Ximian Offers Customized Opera for Linux with Red Carpet
Opera has announced that its sales referral partner Ximian will include a customized version of the Opera Web browser as a download option in its Red Carpet software management program for Linux users. Red Carpet is a software management solution used by many Ximian Desktop users, which keeps Linux systems up to date efficiently and securely. The program allows users to install, update and maintain software over the Internet from Ximian, leading Linux distribution providers, and other independent software vendors.
ActiveState Unveils Komodo 2.0
ActiveState Corp., has announced a new IDE that provides a powerful workspace for cross-platform, open source language programming. Komodo 2.0 affords greater power, flexibility and automation, including the ActiveState GUI Builder, Visual Package Manager, Source Code Control, Project Manager, Macros, Web services generation, and more. The only unified open source programming language IDE, Komodo enables editing, debugging, and testing in a single workspace.
Komodo is optimized for Perl, Python, PHP, Tcl, XML, XSLT, and supports numerous other languages, including Ruby and JavaScript.
|
...making Linux just a little more fun! |
-or- Dealing with User Input in Python By Paul Evans |
You probably won't be using Python long before writing a program which needs user input. As a wide-eyed, innocent new Python programmer, you may naively expect that you can simply ask users for input and they will just give it to you....
WARNING: Showing the preceding sentence to veteran programmers may cause them to collapse on the floor giggling helplessly.
Users don't work that way.
For example, if you ask for a simple 'y or n' response, your user may cheerfully type in their name - or their lunch order, or nothing at all - and your program will break. They don't do this on purpose (well, mostly). It's just that the poor dears are easily distracted, totally ignore your carefully worded input prompts and often type complete gibberish as far as your program is concerned. Next, oddly enough, they will blame you, the programmer. Then you will look foolish and feel Unhappy.
To avoid this misery, the very first thing you need to do is make sure that whatever comes back from the user is checked to see if it's even vaguely close to what you expected. Python has heaps of functions to help you with this and we'll begin by going through some of them together below.
Another thing you can do is use validators on your input widgets. The way these work is they simply throw away any keystrokes that are not what you are after. As an example, if you set a numeric validator on a string widget, users can press 'ABC' etc. as much as they like and nothing will even show up in the widget. The only keys they can press that will have any effect are 0-9 and, perhaps, a decimal or dollar symbol. We'll play with these too later on.
Finally, even if you are lucky enough to find yourself in possession of a particularly well-trained and obedient user who always types what you ask, the input is unlikely to be formatted exactly the way you want it. Careless typing often produces strings like 'jOHN sMith' (caps lock) or phone numbers resembling '604555-1212'.
All kidding aside, it's actually your job as a programmer to make it as easy and fast as possible for the user to input data and that it be presented and stored in a consistent format. Plus, you can get a great deal of personal satisfaction and even, dare I say it? gratitude from users if you can save them from the hell of properly typing something like a Canadian postal code.
First your program will need to acquire some user input. From the console Python offers two methods for this 'raw_input("Prompt")' and 'input("Prompt")'. (Don't use 'input', see below.) You can also get input from good ol' command line arguments or environment variables.
Other, more graphical methods are available, without getting too carried away, such as Xdialog, Gdialog (part of gnome-utils) or Kaptain.
Access to full-blown GUI toolkits is available from Python using PyQT , TKinter, WxPython and PyGTK among others.
This is probably a good time to provide a few words of caution. Most users are contented, docile creatures who like to have their belly rubbed, but you will encounter rogue types bent on destruction.
For this reason you must never allow user input to leak into your command space:
O.K. Relax. The spooky part is over.
Open an xterm and type 'python' to enter the interpreter. Note: Many of these examples require that you be using a version of Python greater than or equal to version '2'. Redhat still ships with version 1.5x as default, so if you are a Redhat user you will need to type 'python2' instead (and possibly install the rpm first from 'add-ons'). For the record, version '1.5' was released in a year which began with the digits '1' and '9'.
Programming languages usually include methods for checking of this kind and Python is no exception. Consider one of our first challenges as stated above: making sure the user gives us a valid number when we ask for one.
It happens that all string objects in Python have built-in methods which make this quite painless. Type these lines in at the '>>>' prompt:
>>>input = '9' >>>input.isdigit() 1
This will return a '1' (true), so you can easily use it in an 'if' statement as a condition. Some other handy attributes of this kind are:
s.isalnum() returns true if all characters in s are alphanumeric, false otherwise. s.isalpha() returns true if all characters in s are alphabetic, false otherwise.
For a complete list of these and much more, I highly recommend the Python 2.1 Quick Reference. I use this all the time and even have an older text version stuffed into HNB for speed.
This will get us through simple cases like menu choices, but what if we wanted a float or a real number?
Consider:
input = '9.9' or input = '-9'
Both of these are valid numbers, but input.isdigit() will return '0' (false), because the negative sign and the decimal point are not 'digits'. Our poor user will be very confused when we spit back an error message if these entries are valid.
So, let's assume that they are what we want and try to convert them explicitly. For this we'll use the Python try/except construction. Python raises exceptions of different kinds on errors and we can trap these errors individually by name.
Say we wanted an integer like '-9', we can use the numeric operator 'int()' to explicitly attempt the conversion for us.
try:
someVar = int(input)
print 'Is an integer'
except (TypeError, ValueError):
print 'Not an integer'
Two things to notice here. The first is that we are checking for two different exceptions, Type and Value. This way we not only handle the user entering a float (like '9.9'), but we also allow for the possibility that they didn't even enter a number of any kind - perhaps they entered 'Ham on rye'. The second thing to notice is that we actually entered the kinds of exceptions we were interested in trapping. It's very easy to just type in open ended exceptions without bothering to look up which errors you are trapping like this:
try:
someVar = int(input)
print 'Is an integer'
except:
print 'Not an integer'
DO NOT DO THIS. Python will let you, but since you are now trapping all exceptions debugging will be a nightmare for you if anything breaks. Just trust me on this one; look up the errors you mean to trap and you'll save time in the long run.
Other operators you'll find useful are long() and float(). On the flip side, str() can convert anything to a string.
Don't forget to range check - it's no good congratulating yourself on ensuring your program always gets an integer from a user if it blithely accepts the integer '42' as a valid month day... Make sure the number falls into the expected range using the comparison operators '>, <, >=' etc.
As we've seen, we can validate input after we get it, but wouldn't it be nice if we could prevent the user from entering mistakes in the first place?
Enter widget validators.
These are things built into graphical user interface toolkits that prevent unwanted keystrokes from even appearing in the string widget. Toolkits usually come with some built-in validators for numeric, alpha, and alphanumeric etc. and are quite easy to use. I'm currently using mostly PyQT for gui's, but TKinter, WxPython and even Kaptain all have validators. I could be wrong, but PyGTK seems not to have them - yet. Perhaps you could hook up a signal and roll your own if you happen to use a toolkit that doesn't have them.
If the built-in validators don't suit you then PyQt, for example, allows you to specify your own, custom validators.
Clearly, I can't go into detail for every toolkit out there, but here's an example of how to attach a numeric validator to a widget in PyQT. The widget's name is 'self.rate', we're attaching the 'QDoubleValidator' and telling it to accept numbers between 0.0 and 999.0 up to 2 decimal places:
self.rate.setValidator(QDoubleValidator(0.0, 999.0, 2, self.rate) )
Nice eh? Notice it took care of range checking for us too!
Other ways to help users enter information include spinners, pick-lists and combo-boxes, but you already knew that.
Remember the 'jOHN sMith' example from the introduction? Here's the fix:
>>>'jOHN sMith'.title() 'John Smith'
Yes, yet another attribute of all string objects in Python is the 'title()' attribute which will helpfully capitalize each word for you. 'capitalize()' is similar, but only does the first character:
>>> 'jOHN sMith'.capitalize() 'John smith'
Go ahead and try 'upper()', 'lower()' and 'swapcase()' on your own if you like. I think you can guess their behaviour.
But how about 'rjust(n)'? This is only one of some really handy attributes you can use to layout reports. Watch:
>>> 'John Smith'.rjust(15) ' John Smith'
Our string has been right justified for us in a string 15 characters long. Sweet. As you've probably guessed, there are also 'center(n)' and 'ljust(n)'. Again, have a look at the Python 2.1 Quick Reference to see them all.
Another, very important operator in Python is the '%' (per cent) operator. The description of this in combination with list objects and printf-style formatting codes could easily consume several pages, so I'm just going to gloss over it with a few examples to pique your interest today.
In it's simplest form, the '%' operator lets you write, say, a proper sentence that includes variables which can change at runtime:
>>> 'This is a %s example of its %s.' % ('good', 'use')
'This is a good example of its use.'
At least, I hope it is. This is only the beginning of its power. In addition to just string object substitution with '%s' there is also '%r' and the printf friends from the 'C' language: c, d, i, u, o, x, X, e, E, f, g, G.
Here's an example from Python 2.1 Quick Reference:
>>> '%s has %03d quote types.' % ('Python', 2)
'Python has 002 quote types.'
The right hand side may also be a mapping, which allows you to refer to fields by name.
Let's move on to something a little more challenging, but common enough.
Phone numbers are variable in length. Sometimes they are only 2 or 3 digits long if you are behind a corporate PBX system. Other times they might stretch out to 15 digits or more for international calling. They might even contain '#' symbols or asterisks. Maybe even commas. Worse, the user may attempt to impose a format on it as they enter it. Or a partial format. Or not.
Now, it will only frustrate your user if you don't let them at least try to enter it properly, so your validator had better accept all of #, *, 'comma', -, ), ( as well as the digits 0-9. Of course, you could still end up with:
'250-(555)-12-12'
instead of the string:
'(250) 555-1212'
that we actually want (for a North American phone number anyhow). Don't worry, we'll make the solution generic enough to handle just about anything.
My first instinct when I need something like this is to copy someone else's work by mining Google - especially Google Groups. This turns out to be a good instinct for me to have since the code snippet I usually find will be far better than I could do on my own. Unfortunately, this time I turned up an email from Guido van Rossum (the inventor of Python) explaining to someone that Python did not have such a thing and perhaps they could use something like:
import string
def fmtstr(fmt, str):
res = [] i = 0
for c in fmt:
if c == '#':
res.append(str[i:i+1]) i = i+1
else:
res.append(c)
res.append(str[i:])
return string.join(res)
This is a darn good start of course and you can't argue with the credentials of its author, but it doesn't handle all the cases without a lot of 'if/then' constructs to count how many digits you were given in order to choose a format string of the correct length. Go ahead and paste it into your xterm and then call it like this:
>>> fmtstr('###-####', '5551212')
'5 5 5 - 1 2 1 2 '
In fact, I did copy and paste it into my editor and then constructed a long sequence of 'if/thens' for phone numbers, dates and other types of entries, but I still wasn't handling everything. Plus, I had dozens and dozens of lines doing self-similar things. They have since passed on to their reward.
O.K., here we go... First, let's filter any "extra" formatting characters we let the user type in:
def filter(inStr, allowed):
outStr = ''
for c in inStr:
if c in allowed:
outStr += c
return outStr
We could call it like this:
>>>filter('250-(555)-12-12', string.digits)
'2505551212'
Or we could define the second argument ourselves as '0123456789#*,' to include all the allowable characters possible.
Now we just take Guido's code snippet and (this is the good bit) reverse both the input arguments. This way we can specify just one long format string and it will be matched until we run out of input. Any extra input will just get tacked on, so we will never lose any characters.
# import the regular expression module
import re
def formatStr(inStr, fmtStr, p = '^'):
inList = [x for x in inStr] #list from strings..
fmtList = [x for x in fmtStr]
# the good bit
inList.reverse(); fmtList.reverse()
outList = []
i = 0
for c in fmtList:
if c == p:
try:
outList.append(inList[i])
i += 1
# break if fmtStr longer than inStr
except IndexError:
break
else:
outList.append(c)
# handle inStr longer than fmtStr
while i < len(inList):
outList.append(inList[i])
i += 1
# put it back the way we found it
outList.reverse()
outStr = ''.join(outList)
# remove stray parens/- etc
while re.match('[)|-| ]', outStr[0]):
outStr = outStr[1:]
# close any legit parens
while outStr.count(')') > outStr.count('('):
outStr = '(' + outStr
return outStr
[Text version of this listing.]
It's basically the same as Guido's except the default placeholder character is now a '^' (caret), because we may need to use the '#'. Alternatively, this may be specified as an, optional, third argument if we ever need real carets in the output.
Here's some sample output:
>>> formatStr('51212', ' ^^^ ^^ (^^^) ^^^-^^^^')
'5-1212'
>>> formatStr('045551212', ' ^^^ ^^ (^^^) ^^^-^^^^')
'(04) 555-1212'
>>> formatStr('16045551212', ' ^^^ ^^ (^^^) ^^^-^^^^')
'1 (604) 555-1212'
>>> formatStr('1011446045551212', ' ^^^ ^^ (^^^) ^^^-^^^^')
'1 011 44 (604) 555-1212'
In practice, you'll probably want to simply define your phone formatting string early on e.g.:
phone_format_str = ' ^^^ ^^ (^^^) ^^^-^^^^'
There's a space at the beginning of the string so that any additional characters won't get smooshed onto it. You'd likely call it thus:
formatStr(input, phone_format_str)
... after you clean up your 'input' with something like the 'filter()' function.
In case you are (blessedly) unfamiliar with Canadian postal codes, they look like this:
'V8G 4L2'
Which appears innocuous enough until you attempt to type it. Especially for non-typists (like me). You can turn on the caps lock - and then forget to turn it off - or you have to type [shift]+alpha, number, [shift]+alpha etc. and quite often end up with: 'v*g $l@' when you get out of sequence. Needless to say, users hate typing them in and they hardly ever look right. Mostly your application won't even capture postal codes, because users simply won't bother. Some other countries have similar post codes. Shame.
Now, with our new formatting function, they're a piece of cake. First, we either validate or filter whatever they give us, then we simply use Python's built-in string attribute 'upper()' to set the case of the alpha characters properly, finally:
>>>formatStr('V8G4L2', ' ^^^ ^^^')
'V8G 4L2'
If accurate postal codes are critical to your application, you will need to do more verification by way of counting the characters and verifying the pattern. For general use though, you need to allow for the postal codes of other countries. I think I normally format only if the number of characters == 6 after clean up.
How about Social Insurance Numbers? Same deal:
>>> formatStr('716555123', '^^^-^^^-^^^')
'716-555-123'
You should run a check digit routine over Social Insurance Numbers first to ensure they are valid. Ditto for credit cards.
I hope these examples will save you some time in coding user interfaces. I'd very much like to hear back with examples or improvements of your own. Particularly ways of dealing with dates1 with users. They're always fun.
By the way, it's very important that you not keep these formatting aids a secret from your users. Put it in the 'help', use 'tooltips' or 'whatis' to let them know the facility is there for them. If they find out after months of typing things the long way, they are liable to pout and you'll end up wasting afternoon coffee scratching them behind the ears (morning coffee is a given).
Have fun with it!
1 That's calendar dates...
 Paul Evans
Paul Evans|
...making Linux just a little more fun! |
By Tedi Heriyanto |
Imagine you are developing a program called foo, which consists of five headers, that is 1.h, 2.h, 3.h, 4.h, and 5.h, six C-language source code files named 1.cpp to 5.cpp, and a main.cpp file (Remember: we do not recommend to use such file naming scheme in the real life).
Suppose you find a bug in 2.cpp and has fix it. In order to get a new foo program, you have to recompile all files, header and source code, even though you just change one file. This is not a fun job, waiting for the computer to finished its process compiling your program. Particularly if you don't have fast computer.
What can you do then? Is there any solution for this problem ?
Please do not worry my friends. That kind of problem has already been experienced by our fellow computer hackers years ago. To tackle this problem, they have developed a program called make. Instead of build all of the source codes, this program will only build source code that has been changed. If you change file 2.cpp, then make will only build it. Isn't it fun?
The followings are several other reasons why we need make [2] :
Although make is very useful, it cannot do its job without the instructions given by us, the programmer. make instructions is stored in a text file. This file is usually called makefile and contains commands that must be processed by make.
This file is normally named makefile or Makefile. As a convention, GNU programs named their makefile, Makefile, because it is easy to see (if you do "ls" then this file is usually always on the top of the list). If you give it another name, just make sure you include option -f to make command in order to let it know that you use it.
For example, if we have a makefile named bejo, then the command we use to instruct make to process that file is :
make -f bejo
A makefile consists of target, dependencies and rules section. Dependecies are things or source code needed to make a target; target is usually an executable or object file name. Rules are commands needed to make the target.
Following is a simple description of a makefile :
target: dependencies command command ...
The following is a simple makefile example (line numbers added for the article):
1 client: conn.o 2 g++ client.cpp conn.o -o client 3 conn.o: conn.cpp conn.h 4 g++ -c conn.cpp -o conn.o
In the makefile above, dependencies is line contained client: conn.o, while rules is line contained g++ client.cpp conn.o -o client. Note that every rule line begins with a tab, not spaces. Forgetting to insert a tab at the beginning of the rule line is the most common mistakes in constructing makefiles. Fortunately, this kind of error is very easy to be spotted, because make program will complain about it.
Detail description of the makefile depicted above are as follows :
To give a comment in makefile, merely put '#' in the first column of each line to be commented.
Below is an example makefile that has already been commented :
# Create executable file "client" 1 client: conn.o 2 g++ client.cpp conn.o -o client # Create object file "conn.o" 3 conn.o: conn.cpp conn.h 4 g++ -c conn.cpp -o conn.o
A phony target is a fake filename. It is just a name for commands that will be executed when you give an explicit request. There are two reasons for using phony target : to avoid conflicts with a file with the same name, and to enhance the makefile performance.
If you write a rule whose command will not create a target file, those commands will be executed every time the target is remade. For example:
clean: rm *.o temp
Because the command rm will not create a file named clean, that file will never exist. Command rm will always be executed every time you called make clean, because make assume that the clean file is always new.
The above target will stop working if a file named clean exists in the current directory. Because it does not require dependencies, file clean will be considered up-to-date, and the command 'rm *.o temp' will not be executed. To resolve this problem, you can explicitly declare a target as phony, using special target command .PHONY. For example :
.PHONY : clean
In the makefile above, if we give instruction make clean from the command-line, the command 'rm *.o temp' will always be run, whether or not a file named clean exists in the current directory.
$VAR_NAME=value
As a convention, a variable name is given in uppercase, for example :
$OBJECTS=main.o test.o
To get a varible's value, put the symbol $ before the variable's name, such as :
$(VAR_NAME)
In makefile, there are two kinds of variables, recursively expanded variable and simply expanded variable.
In the recursively expanded variable, make will continue expanding that variable until it cannot be expanded anymore, for example :
TOPDIR=/home/tedi/project SRCDIR=$(TOPDIR)/src
SRCDIR variable will be expanded, first by expanding TOPDIR variable. The final result is /home/tedi/project/src
But, recursively expanded variable will not be suitable for the following command :
CC = gcc -o CC = $(CC) -O2
Using a recursively expanded variable, those command will go to endless loop. To overcome this problem, we use a simply expanded variable :
CC := gcc -o CC += $(CC) -O2The ':=' symbol creates the variable CC and given its value "gcc -o". The '+=' symbol appends "-O2" to CC's value.
I hope this short tutorial will give you enough knowledge to create makefile. Until then, happy hacking.
|
...making Linux just a little more fun! |
By Kamil Klimkiewicz |
About three or four months ago I switched from Windows to Linux. I had been using Linux before but it was only my second operating system. When it became my primary one I had to deal with several problems. Most of them I was able to fix quickly. There was one thing which caused many troubles - I had three e-mail accounts.
Windows user could say, "Download some e-mail client and configure it to use several accounts." But there is something called the 'Unix philosophy'. It says that programmers should write small applications which do only one thing but do it well. What does it mean for us? It means that there is no single tool which fetches your mail from remote server, allows you to read and write mail and sends it to its target.
In this short article I will only show you how to configure tools called fetchmail and mutt. If you want to go deeper into this topic you should read:
You can get them from http://www.linuxdoc.org.
Let's define our e-mail environment: we have three e-mail accounts, each placed on different server. We will call them 'First', 'Second' and 'Third.' Their addresses are: first@firstdomain.com, second@seconddomain.com, third@thirddomain.com. Moreover the first account uses IMAP protocol and the others POP3.
The local user who is going to receive all the messages is called 'john'. We need to set new value for $MAIL environment variable, since we won't use default '/var/spool/mail/john' (this is unsafe and less convenient.) To do this we add following lines to .bash_profile (of course if you use different shell you have to change different things):
MAIL=$HOME/Mail/Inbox export MAIL
(Don't forget to create directory '$HOME/Mail'!.) We will also use additional mailboxes for read messages (each account has its associated box.)
Before we can read our mail we have to fetch it from remote server. To do this we will use a tool called fetchmail. It should be already installed on your system.
Configuring fetchmail is quite easy task. Moreover we can use utility 'fetchmailconf' which makes the process even easier. Configuration file we should edit is $HOME/.fetchmailrc. Simple one, appropriate for our environment, looks like this:
set postmaster "john"
set bouncemail
set properties ""
set daemon 300
poll First via firstdomain.com
with proto IMAP
user first there with password this_is_password is john here warnings 3600
poll Second via seconddomain.com
with proto POP3
user second there with password this_is_password is john here warnings 3600
poll Second via thirddomain.com
with proto POP3
user third there with password this_is_password is john here warnings 3600
To run fetchmail you only need to type fetchmail. It will be started in daemon mode and will check whether there is new mail every 5 minutes.
Our messages are on local machine now, so we can read them using any Mail User Agent. I assume it is mutt because this article is intended to deal with mutt.
Mutt needs to be configured before it can work like we want. First of all we have to put some basic definitions in its configuration file (it is usually called $HOME/.muttrc.) They can look like this:
set mbox = "~/Mail/Inbox" set move = no set folder = "~/Mail" set record = +Sent mailboxes +Inbox +First +Second +Third
This actually allows us to read the messages but every outgoing message will have something like john@localhost in its From header field. We should be able to change the sender address so the message can look like it was sent from firstdomain.com or seconddomain.com or whatever machine you have account on.
To achieve this we use additional mailboxes (First, Second and Third) and mutt's so called hooks mechanism. The latter executes user defined commands when some action is being performed. There is folder-hook which is called when user changes mail folder (by pressing 'c' key.) To change the From field we need to modify from and realname mutt variables:
# Default action: folder-hook . set from = first@firstdomain.com folder-hook . set realname = First # First account: folder-hook First set from = first@firstdomain.com folder-hook First set realname = First # Second account: folder-hook Second set from = second@seconddomain.com folder-hook Second set realname = Second # Third account: folder-hook Third set from = third@thirddomain.com folder-hook Third set realname = Third
We should also define the alternates variable so mutt can recognize messages sent to and by us:
set alternates = "first@firstdomain\.com|second@seconddomain\.com|third@thirddomain\.com"
Note: There is a web tool called MuttrcBuilder at http://mutt.netliberte.org which you can use to configure your mutt.
|
...making Linux just a little more fun! |
By Ben Okopnik |
What makes replication a uniquely wonderful experience under Linux is the large number of options for doing so, which implies flexibility and the ability to adapt the method to your exact situation - just as I have here. Other OSes are generally confined to one rather restrictive method (in effect, "dd"ing the hard drive contents to an identical drive.) With Linux, you can pick whatever method suits your needs. However, there is a cost - the same one that applies to just about anything else in Linux. As the XFree folks say, "don't set policy - provide a mechanism." What you have to do, rather than blindly running a provided menu-driven application (what is that thing doing behind the scenes? Can you troubleshoot the process if it goes wrong?) is a) understand the process, and b) choose the tools that will make it happen. In the world of Unix, where "small sharp tools" is a major tenet of the underlying philosophy, this is the default way to work.
This is not the standard way to replicate a Linux system. What is described below was an experiment just to see if it could be done. Yes, you could probably repeat my results - you might even find it as convenient as I did to do it this way - but if you mess it up and end up causing clogged toilets in New Guinea, earthquakes in Abu Dhabi, and war between Earth and the intelligent cephalopods of Beta Cygni 4, don't blame me!It seems that for a number of people, myself most emphatically included, the best way to learn how something works is to take it apart and then put it back together (usually turning a five-dollar toy into a three-day-long project and seven gallons of sweat, but - oh well.) So... about a week ago, I was given a computer, somebody's "outdated" box. (Wind*ws is great. No, really. There's no way I'd run it, but I love the effect it has: it makes people think that a P3-400/64MB machine is "outdated". There are always going to be a lot of uninformed folks out there, so I can see a lifetime of free computers ahead of me! Somebody else here wants to give me a really nice 486 Gateway laptop, too...)
Of course, as far as I'm concerned, new computer = Linux installation. That's like ham and eggs, bread and butter, agua caliente para chocolate (yes, I'm getting a little hungry here, but you get the idea.) It's just natural. However, my install CDs are old enough that I have to wipe off the Tyrannosaurus footprints - I mean, they're almost a year old! - so I wasn't going to do that. Hmm. My Net access these days consists of walking over to the marina office (I live on a sailboat) and plugging into a phone jack - dragging over a desktop PC and leaving it plugged in for a week wasn't going to be looked on favorably. Scrap that scenario. I could order the latest CD set from CheapBytes.com, but I didn't feel like waiting for several days: I had a time slot now. This was going to take a little planning.
My laptop has a well-polished install of Debian on it - I've had quite a while to get it all set up exactly the way I want it. I could just "dd" everything over, and - oh. The laptop drive is 12GB; the drive I dug up was an old 6GB that had a 2GB partition with some historical data on it and a really ancient Debian install. I didn't want to just scrap the data, didn't feel like messing around with my backups and tape drives, and 12 won't fit into 6 anyway. Let's see. A fair chunk of that 12 is my music collection; heck, I'll just leave it on the 'top. Next, there's my "Data Dump": an FTP archive backup, a mirror of the Comprehensive Perl Archive Network (CPAN)... yeah, all that could stay there too. A little decision-making, and my entire kit of programs turned out to fit into about 2GB - just what the doctor ordered! All except one thing, that is - how would I get it from here to there, keeping all the permissions, etc. correct? And what other problems would I run into?
There are a number of standard methods for installing Linux: CD or other media, an archive or a loop-mounted image via a network, raw copying between same-sized drives with "dd", and - closest to what I wanted - a filesystem dump between identically laid-out systems (see Jim Dennis' tip in LG#68, "Bulk File Transfers from Wind*ws to ???".) However, I wasn't doing any of those, not even the last; instead, I was going to transfer bits and pieces to a different FS layout. Would it work? In a move strongly fueled by way too much machismo, entirely too little sense, and Mike Orr's column in this very magazine (see his "The Foolish Things We Do With Our Computers" [look in the Index of All Issues to find it] -- perhaps this whole article belongs in that category!), I said to myself: "Self... let's do it anyway. We can always restart from scratch."
I don't run any network services on my laptop by default - one of the first things I do in almost any install is disable "inetd" - but here, I wanted to use "sshd" for a specific reason. Therefore, Baldur (the laptop) got a command of "su -c '/etc/init.d/ssh start'", and Ymir (the desktop) got "rsync -e ssh -avz --exclude-from file.lst root@192.168.0.3:/ /". The exclude list, a file called "file.lst" (files and directories that "rsync" should ignore) was a fairly short one: "/proc/", not being a "real" filesystem, didn't need to be copied (in fact, doing so would be a bad idea); however, I did make an empty "/proc" directory on the new partition. I skipped "/lost+found/" as well - one was automatically created on Ymir when I ran "mke2fs" (besides, it's not just a simple directory; see "mklost+found" for more info). I also most carefully did not copy the journal-related files ("/.journal" and "/.memdump") from Baldur; they would have no relation to the disk state on Ymir, and could probably screw things up pretty badly. Last, I added the directories that I didn't want to copy to the new system.
Once done with the copying - which took a while, even at 100Mb/s - I did a "chroot /mnt/0 /bin/bash" on Ymir, which made this new filesystem the root ("/") and ran a shell in it. Success! I thought of this as the "three-quarter-way point"; most of the moving was done, and the only remaining critical thing was making the system bootable. Of course, I had to do a bit of system-specific setup: modifying "/etc/fstab" to reflect the correct partitions, fixing "/etc/modules" to load the right ones, adjusting "/etc/lilo.conf" and running "/sbin/lilo" to boot the right image... oh, whoops. Baldur boots via "initrd"; the "initrd" image includes information about which partition gets "pivoted to" as root, and that was different between Baldur and Ymir. OK, then - I jumped over to Baldur and ran "mkinitrd" with the "-r /dev/hda2" option, which built me a new "initrd" image with the correct partition as the root. I "rsync"ed it to Ymir, and life was lookin' good.
As a last step before rebooting, I ran "/sbin/lilo -v3", and... aaarrgh. I got a message about the boot sector being made by a previous version of LILO (remember that ancient Debian distro that had been on there?), and the new one simply refused to rewrite it! <sigh> Clearly, this would not normally be an issue, but this time, it was a pain. Ah - LILO's manual mentions the "QuickInst" script that is supposed to be used for initial installs only - perfect. (See LILO's "doc" directory.) "QuickInst" walked me through setting up some basics, and... <laugh> it didn't work - the "lilo.conf" that it wrote was too simple, and didn't match my setup. That was OK, because it did rewrite the boot sector; I simply copied the correct version of "lilo.conf" back into "/etc", re-ran "lilo -v3", and All Was Cool.
I then rebooted, swapped the BIOS settings back so that Ymir would boot from the HD rather than the CDROM, watched a few errors fly by... and was greeted with a login prompt. Hurrah! That was 90% of the way there; the rest was just more tweaking. For the record, the things that produced the errors were: "hdparm" disk tuning parameters had to be changed, and one old module was still loading from "/etc/default/hotplug.usb". Other than that, all that remained was much like setting up a new system, although a lot less work. Let's see:
Happy Linuxing to all!
|
...making Linux just a little more fun! |
By Pradeep Padala |
If you have read my previous article on GD, you might have noticed that creating charts with the GD module is cumbersome. (That article also contains some general information about loading Perl modules.) Martien Verbruggen has created the GD::Graph module that allows easy creation of charts. This module has useful functions to create various types of charts such as bar charts, pie charts, line charts etc... The module is very useful in creating dynamic charts depicting network statistics, web page access statistics etc...
In this article, I will describe a general way of using the module and also show a few examples of creating various charts.
A perl script using GD::Graph to create charts typically contains the following things:
$mygraph = GD::Graph::chart->new($width, $height);
where chart can be bars, lines, points, linespoints,
mixed or pie. For example, if you wanted a bar chart, you
would use
$mygraph = GD::Graph::bars->new($width, $height);
$myimage = $mygraph->plot(\@data);
Let's draw a simple chart following above steps. This script uses CGI to output
the image on to a web page.
[Text version of this listing.]
#!/usr/local/bin/perl -w
# Change above line to point to your perl binary
use CGI ':standard';
use GD::Graph::bars;
use strict;
# Both the arrays should same number of entries.
my @data = (["Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug",
"Sep", "Oct", "Nov", "Dec"],
[23, 5, 2, 20, 11, 33, 7, 31, 77, 18, 65, 52]);
my $mygraph = GD::Graph::bars->new(500, 300);
$mygraph->set(
x_label => 'Month',
y_label => 'Number of Hits',
title => 'Number of Hits in Each Month in 2002',
) or warn $mygraph->error;
my $myimage = $mygraph->plot(\@data) or die $mygraph->error;
print "Content-type: image/png\n\n";
print $myimage->png;
The output of the program can be seen here
The above program is pretty much self-explanatory. The @data
variable
is an array of arrays. The first array represents the labels on X-axis and all
the subsequent arrays present different datasets.
As you can see, the graph produced by above program is quite bland and simple. We can tweak various options to produce better looking and customized graphs. There are a multitude of options to control the various aspects of the graph. Options are divided into two types: the options common to all types of graphs, and the options specific to each type of graph.
Options can be set while creating the graph or with
$mygraph->set(attrib1 => value1, attrib2 => value2, ...);
Let us write a script setting legends, a grid and few options.
[Text version of this listing.]
#!/usr/local/bin/perl -w
# Change above line to point to your perl binary
use CGI ':standard';
use GD::Graph::bars;
use strict;
# Both the arrays should same number of entries.
my @data = (['Fall 01', 'Spr 01', 'Fall 02', 'Spr 02' ],
[80, 90, 85, 75],
[76, 55, 75, 95],
[66, 58, 92, 83]);
my $mygraph = GD::Graph::bars->new(500, 300);
$mygraph->set(
x_label => 'Semester',
y_label => 'Marks',
title => 'Grade report for a student',
# Draw bars with width 3 pixels
bar_width => 3,
# Sepearte the bars with 4 pixels
bar_spacing => 4,
# Show the grid
long_ticks => 1,
# Show values on top of each bar
show_values => 1,
) or warn $mygraph->error;
$mygraph->set_legend_font(GD::gdMediumBoldFont);
$mygraph->set_legend('Exam 1', 'Exam 2', 'Exam 3');
my $myimage = $mygraph->plot(\@data) or die $mygraph->error;
print "Content-type: image/png\n\n";
print $myimage->png;
The output of above program can be seen here
Again as you can see, GD::Graph provides a flexible to way to create customized graphs. Let's prepare another chart with a logo.
Text version of the file can be found here
#!/usr/local/bin/perl -w
# Change above line to point to your perl binary
use CGI ':standard';
use lib '/cise/homes/ppadala/mydepot/lib/perl5/site_perl';
use GD::Graph::bars;
use strict;
# Both the arrays should same number of entries.
my @data = (['Fall 01', 'Spr 01', 'Fall 02', 'Spr 02' ],
[80, 90, 85, 75],
[76, 55, 75, 95],
[66, 58, 92, 83]);
my $mygraph = GD::Graph::bars->new(500, 300);
$mygraph->set(
x_label => 'Semester',
y_label => 'Marks',
title => 'Grade report for a student',
# Draw bars with width 3 pixels
bar_width => 3,
# Sepearte the bars with 4 pixels
bar_spacing => 4,
# Show the grid
long_ticks => 1,
# Show values on top of each bar
show_values => 1,
) or warn $mygraph->error;
$mygraph->set(logo => 'lglogo.png');
$mygraph->set(logo_resize => 0.5);
$mygraph->set(logo_position => 'LL');
$mygraph->set_legend_font(GD::gdMediumBoldFont);
$mygraph->set_legend('Exam 1', 'Exam 2', 'Exam 3');
my $myimage = $mygraph->plot(\@data) or die $mygraph->error;
print "Content-type: image/png\n\n";
print $myimage->png;
Output of above program can be seen here
Here's the Linux Gazette logo I used. It's in PNG format. The current version of GD::Graph doesn't recognize any image types besides GIF (although it can write PNG, go figure). I submitted a patch to fix this. You can either apply the patch or use an older version of GD or GD::Graph.
Some information can be better presented with line graphs. Here's an
example showing a line graph.
[Text version of this listing.]
#!/usr/local/bin/perl -w
# Change above line to point to your perl binary
use CGI ':standard';
use GD::Graph::lines;
use strict;
# Both the arrays should same number of entries.
my @data = (['Fall 01', 'Spr 01', 'Fall 02', 'Spr 02' ],
[80, 90, 85, 75],
[76, 55, 75, 95],
[66, 58, 92, 83]);
my $mygraph = GD::Graph::lines->new(600, 300);
$mygraph->set(
x_label => 'Semester',
y_label => 'Marks',
title => 'Grade report for a student',
# Draw datasets in 'solid', 'dashed' and 'dotted-dashed' lines
line_types => [1, 2, 4],
# Set the thickness of line
line_width => 2,
# Set colors for datasets
dclrs => ['blue', 'green', 'cyan'],
) or warn $mygraph->error;
$mygraph->set_legend_font(GD::gdMediumBoldFont);
$mygraph->set_legend('Exam 1', 'Exam 2', 'Exam 3');
my $myimage = $mygraph->plot(\@data) or die $mygraph->error;
print "Content-type: image/png\n\n";
print $myimage->png;
Output of above program can be seen here
Here I have used GD::Graph::lines to create the graph handle. But for this change, the program follows the same pattern for creating graphs.
Similarly we can create a pie chart.
[Text version of this listing.]
#!/usr/local/bin/perl -w
# Change above line to point to your perl binary
use CGI ':standard';
use GD::Graph::pie;
use strict;
# Both the arrays should same number of entries.
my @data = (['Project', 'HW1', 'HW2', 'HW3', 'MidTerm', 'Final'],
[25, 6, 7, 2, 25, 35]);
my $mygraph = GD::Graph::pie->new(300, 300);
$mygraph->set(
title => 'Grading Policy for COP5555 course',
'3d' => 1,
) or warn $mygraph->error;
$mygraph->set_value_font(GD::gdMediumBoldFont);
my $myimage = $mygraph->plot(\@data) or die $mygraph->error;
print "Content-type: image/png\n\n";
print $myimage->png;
The output pie chart can be seen here
The '3d' option draws the pie chart in 3d.
An area graph shows the data as area under a line.
[Text version of this listing.]
#!/usr/local/bin/perl -w
# Change above line to point to your perl binary
use CGI ':standard';
use GD::Graph::area;
use strict;
# Both the arrays should same number of entries.
my @data = (["Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug",
"Sep", "Oct", "Nov", "Dec"],
[23, 5, 2, 20, 11, 33, 7, 31, 77, 18, 65, 52]);
my $mygraph = GD::Graph::area->new(500, 300);
$mygraph->set(
x_label => 'Month',
y_label => 'Number of Hits',
title => 'Number of Hits in Each Month in 2002',
) or warn $mygraph->error;
my $myimage = $mygraph->plot(\@data) or die $mygraph->error;
print "Content-type: image/png\n\n";
print $myimage->png;
Output image can be seen here
The GD::Graph module provides a powerful and flexible way to create charts. It's very useful for creating graphs dynamically for serving on web.
I hope you have enjoyed reading this article. Next month, we will have a look at the PerlMagic Module.
|
...making Linux just a little more fun! |
By A B Prasad |
Refer the following if you are new to SNMP
Various tools relating to the Simple Network Management Protocol including:
See the NET-SNMP site.
Snmptrapd is an SNMP application that receives and logs snmp trap messages sent to the SNMP-TRAP port (162) on the local machine. It can be configured to run a specific program on receiving a snmp trap.
snmptrapd.conf is the configuration file(s) which define how the ucd-snmp SNMP trap receiving demon operates when it receives a trap.
RFC1628 document defines the managed objects for Uninterruptible Power Supplies which are to be manageable via the Simple Network Management Protocol (SNMP).
Please Note: I renamed 'powerd' as 'powerh' as here it is not a daemon but only a trap handling routine
We had the powerh to handle the Power Status of the system. powerh communicates with the UPS through the serial port. However, in a networked system where a number of machines are using the same UPS it is not possible for each system to directly communicate with the UPS. Most modern high capacity UPS support the SNMP Protocol either directly or through a proxy. To handle various power status follow these steps
1. To your snmptrapd.conf add the following lines
traphandle 33.2.3 powerh b traphandle 33.2.4 powerh p
2. Compile the following C code by entering cc powerh.c -o powerhand
copy powerh to a directory in path like /usr/local/sbin/.
[Text version of this listing.]
#include <string.h>
#include <unistd.h>
#include <stdio.h>
#include <fcntl.h>
#include <signal.h>
#define PWRSTAT "/etc/powerstatus"
void powerfail(int);
main(int argc, char* argv[]) {
char s[1000];
int i=0;
while(i<7) {
scanf("%s",s);
i++;
}
scanf("%s",s);
if (!strcmp("b",argv[1]))
if ((!strcmp(s,"33.1.6.3.3"))||(!strcmp(s,"upsMIB.upsObjects.upsAlarm.upsWellKnownAlarms.upsAlarmLowBattery")))
powerfail(1);
if (!strcmp("p",argv[1]))
if ((!strcmp(s,"33.1.6.3.3"))||(!strcmp(s,"upsMIB.upsObjects.upsAlarm.upsWellKnownAlarms.upsAlarmLowBattery")))
powerfail(0);
}
/* As the program may be activated in the event of other alarms as well, the inner 'if' are necessary */
void powerfail(int event) {
int fd;
unlink(PWRSTAT);
if ((fd = open(PWRSTAT, O_CREAT|O_WRONLY, 0644)) >= 0) {
switch (event)
{
case 0:
write(fd, "OKWAIT\n", 7);
break;
case 1:
write(fd, "FAIL\n", 5);
break;
}
close(fd);
}
kill(1, SIGPWR);
}
3. Run snmptrapd on your system (you can configure it in the init scripts)
The system will shutdown 2 minutes after receiving a 'battery low alarm' from the UPS. Then if power is OK before the shutdown it will cancel shutdown or as configured in the powerfail and powerokwait lines in /etc/inittab
When received a trap 33.2.3 (upsMIB.upsTraps.upsTrapAlarmEntryAdded) the program is executed with a 'b' option. Program checks for the 'upsAlarmId' send by the trap and if it is 33.1.6.3.3 (upsMIB.upsObjects.upsAlarm.upsWellKnownAlarms.upsAlarmLowBattery) it notfies init that a power failure occurred. This alarm is added to the alarm table by the UPS agent if the remaining battery run-time is less than or equal to upsConfigLowBattTime. It is removed when the power is back and is acknowledged by trap 33.2.4. The program then sends init a powerokwait message.
snmptrap -v 2c localhost public '' 33.2.3 33.2.3.0 s "33.1.6.3.3" snmptrap -v 2c localhost public '' 33.2.4 33.2.4.0 s "33.1.6.3.3"I am not sure whether this is correct.
I would like to see this few lines of code grow into a complete general purpose UPS managing software capable of:
All Suggestions, Criticisms,Contibutions (code and idea only - no cash please ;) ) etc. are welcome. You can contact me at prasad_ab@yahoo.com. See also my home page .
|
...making Linux just a little more fun! |
By Jon "Sir Flakey" Harsem |
These cartoons are scaled down to fit into LG. To see a panel in all its clarity, click on it.
![[cartoon]](misc/qubism/qb-lordof.jpg)
![[cartoon]](misc/qubism/qb-wireless.jpg)
All Qubism cartoons are here at the CORE web site.
|
...making Linux just a little more fun! |
By Hiran Ramankutty |
A wide variety of applications from different domains need different levels of organization. We have seen the fundamentals of Ruby in Part 1, and now we jump on to the next level of organization.
In Ruby, a regular expression is quoted by '/' as in Perl and awk rather than by quotation marks. Regular expressions have an efficient expressive power, whenever you deal with patterns (as in pattern matching). Also some methods convert a string into a regular expression.
print "abcdef" =~ /de/,"\n" print "aaaaaa" =~ /d/,"\n" ^D 3 FALSE
The operator `=~' is a matching operator with respect to regular expressions. It returns the position in a string where a match was found, or nil if the pattern did not match. It is interesting to see that regular expressions share a particular kind of vocabulary as shown below:
[ ] range specification. (e.g., [a-z] means a letter in range of from a to z)
\w letter or digit. same as [0-9A-Za-z_]
\W neither letter nor digit
\s blank character. same as [ \t\n\r\f]
\S non-space character.
\d digit character. same as [0-9].
\D non digit character.
\b word boundary (outside of range specification).
\B non word boundary.
\b back space (0x08) (inside of range specification)
* zero or more times repetition of followed expression
+ one or more times repetition of followed expression
{m,n} at least n times, but not more than m times repetition
of followed expression
? at least 0 times, but not more than 1 times repetition
of followed expression
| either preceding or next expression may match
( ) grouping
For example, `^f[a-z]+' means "f followed by repetition of letters in range from `a' to `z'. Now what if we want check whether a string fits a given description say for example: "Starts with lower case `f', which is immediately followed by exactly one upper case letter, and optionally more junk after that, as long as there are no more lower case characters. You will have to write a dozen lines in C, right? Admit it; you can hardly help yourself. In Ruby you just have to request the string to be matched with the regular expression /^f[A-Z](^[a-z])*$/. This ability of regular expressions in string matching is often used in UNIX environment, typical example is `grep'. Let us get acquainted with regular expressions. Consider the program given below:
#Store this as regx.rb
st = "\033[7m"
en = "\033[m"
while TRUE
print "str> "
STDOUT.flush
str = gets
break if not str
str.chop!
print "pat> "
STDOUT.flush
re = gets
break if not re
re.chop!
str.gsub! re, "#{st}\\&#{en}"
print str, "\n"
end
print "\n"
# Now run ruby regx.rb
The program requires inputs twice, once for a string and once for a regular expression. The test is performed for the string against the regular expression, and matched parts are highlighted in reverse video. Note that this requires an ANSI terminal since it uses reverse video escape sequences. Do not mind the details of the program.
str>foobar pat>^fo+ foobar ~~~
We see that foo is reversed. Note that ``~~~'' is just for text-based browsers. We shall experiment with different inputs.
str>asd987wonew06521 pat>\d asd987wonew06521 ~~~ ~~~~~ str>foozboozer pat>f.*z foozboozer ~~~~~~~~
Note that foozbooz is matched and not fooz. This is because here the regular expression matches the longest possible substring. First glance interpretation is difficult. Try this:
str> Wed Feb 7 08:58:04 JST 1996
pat> [0-9]+:[0-9]+(:[0-9]+)?
Wed Feb 7 08:58:04 JST 1996
~~~~~~~~
Now try to represent a hexadecimal number using regular expressions. (for example: 0x123af00c as well as 0Xbc13590ae are hexadecimal numbers)
def chab(s) # "contains hex in angle brackets"
(s =~ /<0(x|X)(\d|[a-f]|[A-F])+>/) != nil
end
print chab "Not this one."
print "\n",chab "Maybe this? {0x35}" # use of wrong kind of brackets
print "\n",chab "Or this? <0x38z7e>" # Is this a HEX number
print "\n",chab "Okay, this: <0xfc0004>."
print "\n"
^D
false
false
false
true
Iterator means "one which does the same thing many times". Consider the C code given below:
char *str;
for (str = "abcdefg"; *str != '\0'; str++) {
/* process a character here */
}
Note the abstraction provided by C's for(...) syntax to create loops, but in fact, the programmer has to know the internal structure of a string to test *str with the null character.
Flexible support for iteration is one of the few features that mark a high-level language. Consider the following shell script (/bin/sh):
for i in *.[ch]; do # ... something to do for each file done
All the C source and header files in the current directory are, processed, and the command shell handles the details of picking up and substituting file names one by one. Isn't this working at a higher level than C? What do you think ?
Considering the fact that, it is fine to provide iterators in a programming language for built-in data types, but it is a disappointment if we have to write low-level loops to iterate our dat types. In OOP, this can be a serious problem, since users often define one data type after another.
To solve above matters, every OOP language has elaborate ways to make iterations easy, for example some languages provide class controlling iteration, etc. On the other hand, ruby allows us to define control structures directly. In term of ruby, such user-defined control structures are called iterators.
Let us see few examples:
"abc".each_byte{|c| printf "%c\n", c}
^D
a
b
c
Here, each_byte is an iterator for each character in the string. A local variable `c' is being used here, and each character is being substituted into it. This can be translated into something that looks a lot like C code ...
s="abc" i=0 while i < s.length printf "%c\n",s[i] i+=1 end ^D a b c
... however, the each_byte iterator is simpler conceptually and is more likely to continuously work even if the string class happens to be radically modified in the near future. One benefit of the iterators is their tendency of robustness in the face of such changes, and I think that is a characteristic of a good code.
Another iterator of string is each_line."a\nb\nc\n".each_line{|l| print l}
^D
a
b
c
Every irksome task like finding delimiters for lines, generating sub strings etc. are undertaken by iterators.
Now, let's rewrite this example with for statement.
for l in "a\nb\nc\n"
print l
end
^D
a
b
c
The for statement does iteration by way of an each iterator. String's each works the same as each_line as seen in the previous example.
Current iteration can be done or retried again from the top, by using a control structure `retry' in conjunction with an iterated loop. See below:
c = 0
for i in 0..4
print i
if i==2 and c==0
c = 1
print "\n"
retry
end
end
^D
012
01234
The definition of an iterator may have an occurrence of `yield', which moves control to the block of code that is passed to the iterator (we will see more of this later). The example below defines the iterator repeat, which repeats a block of code the number of times specified in an argument.
def repeat(num)
while num < num
yield
num-=1
end
end
repeat(4) {print "hello world\n"}
^D
hello world
hello world
hello world
If it is not clear, then, print the value of num before and after the occurrence of `yield'.
With `retry' one can define an iterator which works the same as `while', but it is not practical due to slowness.
def MYWHILE(cond)
return if not cond
yield
retry
end
i = 0
MYWHILE(i<3) {print i,"\n" ;i+=1}
^D
0
1
2
By now, I hope you must have got an idea about iterators. There are a few restrictions, but you can write your original iterators; and in fact, whenever you define a new data type, it is often convenient to define suitable iterators to go with it. In this sense this, the above examples `repeat() and `MYWHILE()' are not very useful. We will talk about practical iterators after we have a better understanding of what classes are.
`Object Oriented' is indeed a very catchy phrase. Ruby claims to be an object oriented scripting language; but what does 'object oriented' exactly mean?
There have been a variety of answers to that question, all of which probably boil down to about the same thing. Before arguing and summing our definitions too quickly, let's think for a moment about the traditional programming paradigm.
Traditionally, a programming problem is attacked by coming up with some kinds of data representations, and procedures that operate on that data. We can associate terms inert, passive,and helpless with `data' under this model and that the data sits completely at the mercy of a large procedural body with which we associate terms active, logical, and all-powerful.
The problem with this approach is that programs are written by programmers, who are only human and can only keep so much detail clear in their heads at any one time. As a project gets larger, its procedural core grows to the point where it is difficult to remember how the whole thing works. Minor lapses of thinking and typographical errors become more likely to result in well-concealed bugs. Complex and unintended interactions begin to emerge within the procedural core, and maintaining it becomes like trying to carry around an angry squid without letting any tentacles touch your face. There are guidelines for programming that can help to minimize and localize bugs within this traditional paradigm, but there is a better solution that involves fundamentally changing the way we work.
What object-oriented does is to let us delegate most of he mundane and repetitive logical work to the data itself; we can then change our concept of data from passive to active. Put another way,
What is described above as a "machine" may be very simple or complex on the inside; we can't tell from the outside, and we don't allow ourselves to open up the machine (except when we are absolutely sure something is wrong with its design), so we are required to do things like flip the switches and read the dials to interact with the data. Once the machine is built, we don't want to have to think about how it operates.
You might think we are just making more work for ourselves,but this approach tends to do a nice job of preventing all kinds of things from going wrong.
Let's start with an example that is to simple to be of practical value, but should illustrate at least part of the concept. My 2-wheeler has a trip meter. Its job is to keep track of the distance it has travelled since the last time its reset button was pushed. How would we model this in a programming language? In C, the trip meter would just be a numeric variable, possibly of type float. The program would manipulate the variable by increasing its value in small increments, with occasional resets to zero when appropriate. What's wrong with that? A bug in the program would assign a bogus value to the variable, for any number of unexpected reasons. Anyone who has programmed in C knows what it is like to spend hours or days tracking down such a bug whose cause seems absurdly simple once it has been found. (The moment of finding the bug is commonly indicated by the sound of a loud slap to the forehead.)
In object-oriented context, the same problem can be attacked in a different manner. A programmer designing a trip meter is supposed not to ask "which of the familiar data-types comes closest to resembling the thing" but instead be interested in "how exactly is this thing supposed to act?" The difference winds up being a profound one. It is necessary to spend a little bit of time deciding exactly what an odometer is for, and how the outside world expects to interact with it. We decide to build a little machine with controls that allows us to increment it, reset it, read its value, and nothing else.
We don't provide a way for a trip meter to be assigned arbitrary values; why? because we all know trip meters don't work that way. There are only a few things you should be able to do with a trip meter, and those are all we allow. Thus, if something else in the program mistakenly tries to place some other value (say, the target temperature of the vehicle's climate control) into the trip meter, there is an immediate indication of what went wrong. We are told when running the program (or possibly while compiling, depending on the nature of the language) that we are not allowed to assign arbitrary values to Trip meter objects. The message might not be exactly that clear, but it will be reasonably close to that. It doesn't prevent the error, does it? But it quickly points us in the direction of the cause. This is only one of several ways in which OO programming can save a lot of wasted time.
We commonly take one step of abstraction above this, because it turns out to be as easy to build a factory that makes machines as it is to make an individual machine. We aren't likely to build a single trip meter directly; rather, we arrange for any number of trip meters to be built from a single pattern. The pattern (or if you like, the trip meter factory) corresponds to what we call a class, and an factory) corresponds to an object. Most OO languages require a class to be defined before we can have a new kind of object, but ruby does not.
I would like to emphasize on the fact that the use of an OO language will not enforce proper OO design. Indeed it is possible in any language to write code that is unclear, sloppy, ill-conceived, buggy, and wobbly all over. What ruby does for you (as opposed, especially, to C++) is to make the practice of OO programming feel natural enough that even when you are working on a small scale you don't feel a necessity to resort to ugly code to save effort. We will be discussing the ways in which ruby accomplishes that admirable goal as this guide progresses; the next topic will be the "switches and dials" (object methods) and from there we'll move on to the "factories" (classes). Are you still with us?
|
...making Linux just a little more fun! |
By Sandeep S |
Note: Please don't get confused. Definitely this is an article about ptrace, not about ELF. But a basic knowledge of ELF is required for accessing the core images of processes. So it should be explained first.
ELF stands for Executable and Linking Format. It defines the format of executable binaries used on Linux - and also for relocatable, shared object and core dump files too. ELF is used by both linkers and loaders. They view ELF from two sides, so both should have a common interface.
The structure of ELF is such that it has many sections and segments. Relocatable files have section header tables, executable files have program header tables, and shared object files have both. In the coming sections I shall explain what these headers are.
Every ELF file has an ELF header. It always starts at offset 0 in the file. It contains the details of the binary file - should it be interpreted, what data structures are related to the file, etc.
The format of the header is given below (taken from /usr/src/include/linux/elf.h)
#define EI_NIDENT 16
typedef struct elf32_hdr{
unsigned char e_ident[EI_NIDENT];
Elf32_Half e_type;
Elf32_Half e_machine;
Elf32_Word e_version;
Elf32_Addr e_entry; /* Entry point */
Elf32_Off e_phoff;
Elf32_Off e_shoff;
Elf32_Word e_flags;
Elf32_Half e_ehsize;
Elf32_Half e_phentsize;
Elf32_Half e_phnum;
Elf32_Half e_shentsize;
Elf32_Half e_shnum;
Elf32_Half e_shstrndx;
} Elf32_Ehdr;
A small description on the fields is as follows
e_ident : Contains information about how to treat the binary. Platform dependent.
e_type : Contains information on the type and how to use the binary. Types are relocatable, executable, shared object and core file.
e_machine : As you have guessed, this field specifies the architecture - Intel 386, Alpha, Sparc etc.
e_version : Gives the version of the object file.
e_phoff : Offset from start to the first program header.
e_shoff : Offset from start to the first section header.
e_flags : Processor specific flags. Not used in i386
e_ehsize : Size of the ELF header.
e_phentsize & e_shentsize : Size of program header and section header respectively.
e_phnum & e_shnum : Number of program headers and section headers. Program header table will be an array of program headers (e_phnum elements). Similar is the case of section header table.
e_shstrndx : In the section header table a section contains the name of sections. This is the index to that section in the table. (see below)
As said above, linkers treat the file as a set of logical sections described by a section header table, and loaders treat the file as a set of segments described by a program header table. The following section gives details on sections and segments/program headers.
The binary file is viewed as a collection of sections which are arrays of bytes of which no bytes are duplicated. Even though there will be helper information to correctly interpret the contents of the section, the applications may interpret in its own way.
There will be a section header table which is an array of section headers. The zeroth entry of the table is always NULL and describe no part of the binary. Each section header has the following format: (taken from /usr/src/include/linux/elf.h)
typedef struct elf32_shdr {
Elf32_Word sh_name; /* Section name, index in string tbl (yes Elf32) */
Elf32_Word sh_type; /* Type of section (yes Elf32) */
Elf32_Word sh_flags; /* Miscellaneous section attributes */
Elf32_Addr sh_addr; /* Section virtual addr at execution */
Elf32_Off sh_offset; /* Section file offset */
Elf32_Word sh_size; /* Size of section in bytes */
Elf32_Word sh_link; /* Index of another section (yes Elf32) */
Elf32_Word sh_info; /* Additional section information (yes Elf32) */
Elf32_Word sh_addralign; /* Section alignment */
Elf32_Word sh_entsize; /* Entry size if section holds table */
} Elf32_Shdr;
Now the fields in detail.
sh_name : This contains an index into the section contents of the e_shstrndx string table. This index is the start of a null terminated string to be used as the name of the section. There are many, a few are given.
sh_type : Section type such as program data, symbol table, string table etc..
sh_flags : Contains information such as how to treat the contents of the section.
sh_addralign : Contains the alignment requirement of section contents, typically 0/1 (both meaning no alignment) or 4.
The remaining fields seem to be self explaining.
The ELF segments are used during loading ie, when the image of the process is made in the core. Each segment is described by a program header. There will be a program header table in the file (usually near the ELF header). The table is an array of program headers. The format of the program header is as follows.
typedef struct
{
Elf32_Word p_type; /* Segment type */
Elf32_Off p_offset; /* Segment file offset */
Elf32_Addr p_vaddr; /* Segment virtual address */
Elf32_Addr p_paddr; /* Segment physical address */
Elf32_Word p_filesz; /* Segment size in file */
Elf32_Word p_memsz; /* Segment size in memory */
Elf32_Word p_flags; /* Segment flags */
Elf32_Word p_align; /* Segment alignment */
} Elf32_Phdr;
p_type : Gives information on how to treat the contents. It gives the type of program header such as
etc ..
p_vaddr : relative virtual address the segment expects to be loaded.
p_paddr : physical address of the segment expects to be loaded into the memory.
p_flags : Contains protection flags - read/write/execute permissions
p_align : Contains the alignment for the segment in memory. If the segment is of type loadable, then the alignment will be the expected page size.
Remaining fields appear to be self explaining.
We have got some idea about the structure of ELF object files. Now we have to know how and where these files are loaded for execution. Usually we just type program name at the shell prompt. In fact a lot of interesting things happen after the return key is hit.
First the shell calls the standard libc function which in turn calls the kernel routine. Now the ball is in kernel's court. The kernel opens the file and finds out the type/format of the executable. Then loads ELF and needed libraries, initializes the program's stack, and finally passes control to the program code.
The program gets loaded to 0x08048000 (you can see this in /proc/pid/maps) and the stack starts from 0xBFFFFFFF (stack grows to numerically small addresses).
We have seen the details of the programs being loaded in the memory. So when a process is given and its memory space known, we can trace it (if we have permission) and access the private data structures of the process. It is very easy to say this, but not that easy to do it. Why not make a try?
First of all, let's write a program to access the registers of another
program and
modify it. Here we use the following values of request.
Note : Do not forget to call this, otherwise the process will stay in stopped mode and is hard to recover.
struct user_regs_struct defined as this, in asm/user.h.
struct user_regs_struct {
long ebx, ecx, edx, esi, edi, ebp, eax;
unsigned short ds, __ds, es, __es;
unsigned short fs, __fs, gs, __gs;
long orig_eax, eip;
unsigned short cs, __cs;
long eflags, esp;
unsigned short ss, __ss;
};
Now we are going to inject a small piece of our code to image of the process being traced and force the process to execute our code by changing its instruction pointer.
What we do is very simple. First we attach the process, and then read the register contents of the process. Now insert the code which we want to get executed in some location of the stack and the instruction pointer of the process is changed to that location. Finally we detach the process. Now the process starts to execute and will be executing the injected code.
We have two source files, one is the assembly code to be injected and other is the one which traces the process. I shall provide a small program which we may trace.
The source files
Now compile the files.
#cc Sample.c -o loop
#cc Tracer.c Code.S -o catch
Go to another console and run the sample program by typing
#./loop
Come back and execute the tracer to catch the looping process and change its output. Type
#./catch `ps ax | grep "loop" | cut -f 3 -d ' '`
Now go to where the sample program 'loop' runs and watch what happens. Definitely your play with ptrace has begun.
In the first part we traced a process and counted its number of instructions. In this part we studied the ELF file structure and injected a small piece of code into some process. In next part I would expect to access the memory space of some process. Till then, bye from Sandeep S.
|
...making Linux just a little more fun! |
By Chris Stoddard |
This document provides the steps necessary to make a DVD which will play in a stand alone DVD player, using Linux and a DVD+RW or DVD-RW drive.
I am constantly amazed at how easy it is to accomplish things in Linux once someone works out the process. DVD Authoring is a good example of this, all the parts are in place, all the information is available and it is a relatively easy thing to do, but no where is there a single document showing how to accomplish it. Authoring DVD under Linux is still in its infancy, there are no tools for menus or any advanced features, for now all we can do is single straight DVD stream, which is enough for home videos and saving TV shows. I will not be discussing video editing here, I assume you will either be recording from TV or have a video tape you wish to transfer to a DVD.
I'm not going into much detail about installing the hardware, if you don't know how to install your hardware, I have provided links to articles for help.
Each of these packages has their own install process, please follow the instructions for each individual package.
dvd+rw tools has no Makefile. You can build the binaries doing this:
gcc dvd+rw-format.c
mv a.out dvd+rw-format
cp dvd+rw-format /usr/local/bin
gcc growisofs.c
mv a.out growisofs
cp growisofs /usr/local/bin
Recording the video is the most important step, the size of the video and the frame rate must be right. The following command uses streamer, which comes with xawtv to record the video:
streamer -n ntsc -t 60:00 -s 720x480 -r 30 -o stream.avi -f mjpeg -F stereo -c /dev/video0
The -n switch is for format, if you use PAL, change ntsc to pal. The -t switch is record time in minutes. -s is the size of the video, in the USA, we use NTSC which requires the video to be 720x480 if you use PAL, change this to 720x576. -r is the frame rate, for NTSC use 30, for PAL use 24, -c is the video device, change it if need be. The rest of the switches should remain unchanged.
The next thing to do is to properly encode the audio and video into something a DVD player can read. The tools we need for this are from mjpeg-tools. This command line strips the audio out of our avi file and encodes it to mp2 audio. The -V switch actually is for VCD compatibility, but works for us here:
lav2wav +p stream.avi | mp2enc -V -o audio.mp2
Next we strip out the video and encode it to mpeg video. This part is what takes the longest, the faster your system is the better. The important switches here are -f 8, which ensures the video will be DVD compatible and -n n, which is for NTSC, if you are using PAL change it to -n p:
lav2yuv +p stream.avi | mpeg2enc -n n -f 8 -s -r 16 -o video.m1v
Now we need to join the two encoded files. Be sure to use the -f 8 switch for DVD compatible video:
mplex -f 8 audio.mp2 video.m1v -o complete.mpg
In order for our disc to be played in a stand alone DVD player, the directory structure HAS to be perfect, so please make sure you type the next several commands exactly as shown, in the order shown:
mkdir dvd mkdir dvd/VIDEO_TS
Next we need an Table of Content IFO file, type:
tocgen > dvd/VIDEO_TS/VIDEO_TS.IFO
Now we want to copy our encoded video file into the structure and give it the correct permissions, type:
cp complete.mpg dvd/VIDEO_TS/VTS_01_1.VOB chmod u+w dvd/VIDEO_TS/*.VOB
IFO and BUP files provide DVD players with information specific to the video file it is trying to play, ifogen looks at the video and extracts the information needed. To generate the needed files use this command line:
ifogen -f dvd/VIDEO_TS/VTS_01_1.VOB > dvd/VIDEO_TS/VTS_01_0.IFO (cd dvd/VIDEO_TS; for i in *.IFO; do cp $i `basename $i .IFO`.BUP; done)
Now we need to generate an iso image which can be burned to a DVD disc. Be sure you are using mkisofs version from dvdrtools, which supports the DVD files system:
mkisofs -dvd-video -udf -o dvd.iso dvd/
And, finally, we can burn our disc. If you are using an older first generation DVD+RW drive, the disc will need to be formated before the image can be burned, use the following commands, replacing srcd0 with the device name of your drive:
dvd+rw-format -f /dev/srcd0 growisofs -Z /dev/srcd0=dvd.iso
If you are using a newer DVD-RW, no formating is necessary, dvdrecord will do the job:
dvdrecord -dao speed=2 dev=0,0,0 dvd.iso
The most common problem with this process is audio sync. The first thing you should try is optimizing your hard drive with hdparm, turn on 32 bit I/O and DMA, it looks something like this:
hdparm -c 1 -d 1 /dev/hdaNext, load the bttv driver with the gbuffers=10 option:
modprobe bttv gbuffers=10
This should fix any audio sync problems, if it does not, you may need to use the -O n option when running mplex. This delays the video by n mSeconds. The problem with this is it is a trial and error process and often leaves the joined video file in a state that causes ifogen to segfault. It may also be possible to record the video at a lower size, say 352x240, then use yuvscaler from the mpjeg-tools to resize it to 720x480, but I have not tried this.
This process will not give you "Buy in the Store" DVD quality video, the quality will depend largely on the quality of your capture source, so you should use the best quality settings you can when recording anything on video tape you intend to burn to DVD. This process takes several hours, I use the shell script below to do the work for me, while I am at work or in bed sleeping. 100 minutes of video will require about 11 GB to record, 2 GB to encode and 1 GB for the iso image. Your mileage will vary.
Text version of make-dvd.sh-----make-dvd.sh----- #!/bin/sh # Cleans out any left over files and makes the necessary directories rm -r -f dvd video dvd.iso mkdir dvd mkdir dvd/VIDEO_TS mkdir video # Changes the channel on the TV tuner card v4lctl setstation 3 # Records the video stream streamer -n ntsc -t 60:00 -s 720x480 -r 30 -o video/stream.avi -f mjpeg -F stereo -c /dev/video0 # Encodes the video stream lav2wav +p video/stream.avi | mp2enc -V -o video/audio.mp2 lav2yuv +p video/stream.avi | mpeg2enc -n n -f 8 -s -r 16 -o video/video.m1v mplex -f 8 video/audio.mp2 video/video.m1v -o video/complete.mpg # Builds DVD image from the encoded video # This portion of the script was lifted directly from # the writedvd script which comes with the dvdauthor tools tocgen > dvd/VIDEO_TS/VIDEO_TS.IFO cp video/complete.mpg dvd/VIDEO_TS/VTS_01_1.VOB chmod u+w dvd/VIDEO_TS/*.VOB ifogen -f dvd/VIDEO_TS/VTS_01_1.VOB > dvd/VIDEO_TS/VTS_01_0.IFO (cd dvd/VIDEO_TS; for i in *.IFO; do cp $i `basename $i .IFO`.BUP; done) mkisofs -dvd-video -udf -o dvd.iso dvd/ # Burns the DVD for 1st Generation DVD+RW # Comment out the dvd+rw-format line if the disc is already formated and # contains no data. # Comment these two lines out if you are using a newer drive dvd+rw-format -f /dev/srcd0 growisofs -Z /dev/srcd0=dvd.iso # Burns DVD for more modern DVD formats like DVD-RW # Uncomment this line if you are using a newer drive #dvdrecord -dao speed=2 dev=0,0,0 dvd.iso -----make-dvd.sh-----
|
...making Linux just a little more fun! |
By Dr B Thangaraju |
Abstract
A device driver is an entry point to access a device. Developing a device driver is not as simple a task as writing application programs. Since any dynamically-loaded driver module is attached to the existing kernel, any error in the driver will crash the entire system. Resource allocation for a device is one of the main concerns for device driver developers. The device resources are I/O memory, IRQs and ports. This article presents a risk-free way of allocating resource for an I/O memory mapped device for a dynamically loaded Linux device driver, and is written so that less experienced Linux users can follow along.
In the rapidly developing IT field, new devices are constantly being developed and we see an increasingly wide variety of Input and Output devices. The I/O subsystem allows a process to communicate with peripheral devices such as disks, floppies, CD-ROMs, terminals, printers and networks. Kernel modules that control devices are known as device drivers. The I/O subsystem handles the movement of data between memory and peripheral devices. The type of the devices can be classified into character and block depending on the way the system accesses the device. In general, the character devices like keyboard, mouse, console and modem are accessed as a stream of bytes. However, the block devices like Hard disk, floppy and CD-ROM move blocks of data to and from the system.
The kernel interacts with these devices through device drivers. A device driver is a collection of functions used to access any particular device. One of the important features of Linux is that the device driver module can be inserted dynamically into the existing kernel. Then the driver module will become part of the kernel and can access the kernel functions. In the same way, the loaded driver can be removed dynamically. If the driver is not explicitly removed, it will be persistent in the system until we reboot the machine.
The most frequent job of any driver is transferring data between the computer and its external environment. The external environment consists of a variety of external devices, including secondary memory devices, communications equipment and terminals. Three techniques are possible for I/O operations: programmed I/O, Interrupt - driver I/O and Direct Memory Access (DMA). The programmed I/O devices pass the data from system to device or vice versa in two different ways: I/O port and I/O memory mapped. This article explains the basic concept of I/O memory mapped devices and the macros used by the device driver for allocating I/O memory regions for the device and expounds the concept with well tested device driver code. Since the driver module is part of the kernel, any attempt to allocate existing address to your device will crash the system. So the sample driver will first probe whether the address range is free or not, if it is already in use by other device it will return immediately with an error, otherwise it will allocate the given address range to your device.
Device drivers are extremely device dependent. The driver framework should take responsibility of how the CPU interacts with the device. PIO and DMA are the two ways of moving data between the kernel and the device. PIO requires the CPU to move data to or from the device as each byte is ready, by responding to an interrupt or polling. For DMA devices, the kernel gives the source address, the destination address and the size of the data in memory. The device can transfer the data without CPU intervention, and when the data is moved it will send an interrupt to notify the kernel of the completion. Typically, slow devices like modem and line printers are PIO devices, while disks and graphics terminals are DMA devices.
For PIO devices, there are two ways to pass data from the device to system memory. Which way a system uses depends on its architecture. For instance, Intel x86 architectures supports I/O port, and Motorola 680x0 maintains memory mapped device I/O. Moreover, most of the ISA (Industry Standard Architecture) devices belong to the I/O support allocation and PCI (Peripheral Component Interconnect) devices uphold I/O memory mapped allocation. Several parameters that a driver must know are, for example, the hardware's actual I/O addresses or memory range. Sometimes you need to pass parameters to a driver to help it in finding its own device or to enable/disable specific features. In my previous article in Linux Focus ( http://linuxfocus.org/English/November2002/article264.meta.shtml), I explained the fundamentals of device controllers and intricacies of the fail safe port allocation for Linux device drivers From the driver developer perspective, the allocation of I/O memory for a device has some similarity with allocation of I/O ports because both are based on similar internal mechanisms. So it is redundant to explain again the basics of device controller and the functions of status and control registers for transferring data from or to device to system memory.
To probe whether the address range is already in use or not, use the following macro in driver.
Here, the first argument start is the starting address of the I/O memory and length is the size of the address range. The function returns zero if the address range is available otherwise returns less than zero. To register the given I/O memory regions, the macro is
The string argument char *device_name is the name of device, which will own the I/O memory regions from start address to length size. Before the device is unregistered, the allocated I/O memory regions should be released for other devices.
The above function will de-allocate the I/O memory regions.
|
#include <linux/module.h>
static int Major, result;
unsigned long start = 0, length = 0; MODULE_PARM (start, "l");
int Wipro_init (void) {
result = check_mem_region (start, length);
request_mem_region (start,
length, "Wipro_device");
void Wipro_cleanup (void) {
unregister_chrdev (Major, "Wipro_device");
module_init (Wipro_init);
|
The above program is saved as io_mem.c. First four lines are the headers, which are included to access kernel macros and functions. Next is the variable and file_operations structure declaration. The macro MODULE_PARM is the driver modules parameter for assigning value of any variable during the module loading. It will accept two arguments, first one is the variable name and the second one is data type of the variable. In this code, "l" means long int.
In Wipro_init and Wipro_cleanup functions are explicit initialization and cleanup for this driver module. The modern mechanism recommends this approach for marking init_module and cleanup_module. The Wipro_init function first registers the Wipro_device and allocates major number dynamically. Then it will probe the given address, if the address is already in use, the function will return an error, otherwise it will allocate the address range for the device. The Wipro_cleanup function deallocate the I/O memory region before unregistering the device name and major number.
The file is compiled with 2.4 kernel and has been created io_mem.o object file. The following device and iomem file contains part of the existing data in my computer shown below.
|
$cat /proc/devices
$cat /proc/iomem
|
The module is loaded by a command, $insmod ./io_mem.o start=0xeeee0000 length=0xeeee. After loading successfully, it is evident that the device is registered with the existing devices list with major number 254 and the given memory range is allocated and shown in devices and iomem file respectively as shown below.
|
$cat /proc/devices
$cat /proc/iomem
|
We discussed the importance of the risk-free resource allocation for I/O memory mapped devices for Linux device drivers. We examined the basics of I/O memory mapped devices, the macros for I/O memory address allocation. We explained the practical approach of how to allocate resource for I/O memory mapped devices with the well tested device driver code. We verified the code is explained and the device register and memory range address allocation.
|
...making Linux just a little more fun! |
By Rob Tougher |
I use the Apache HTTP Server to run my web site. When a visitor requests a page from the site, Apache records the following information in a file named "access_log":
Until recently I used a combination of command line utilities (grep, tail, sort, wc, less, awk) to extract this information from the access log. But some complex calculations were difficult and time-consuming to perform using these tools. I needed a more powerful solution - a programming language to crunch the data.
Enter Python. Python is fast becoming my favorite language, and was the perfect tool for solving this problem. I created a framework in Python for performing generic text file analysis, and then utilized this framework to glean information from my Apache access log.
This article first explains the framework, and then describes two examples that use it. My hope is that by the end of this article you will be able to use this framework for analyzing your own text files.
When trying to solve this problem I initially turned to Gawk, an implementation of the Awk language. Awk is primarily used to search text files for certain pieces of data. The following is a basic Awk script:
Listing 1: count_lines.awk
#!/usr/bin/awk -f
BEGIN {
count = 0
}
{ count++ }
END {
print count
}
This script prints the number of lines in a file. You can run it by typing the following at a command prompt:
prompt$ ./count_lines.awk access_log
Awk reads in the script, and does the following:
I liked this processing model. It made sense to me - first run some initialization code, next process the file line by line, and finally run some cleanup code. It seemed perfectly suited to the task of analyzing text files.
Awk gave me trouble, though. It was very difficult to create complex data structures - I was jumping through hoops for tasks that should have been much more straightforward. So after some time I started looking for an alternative.
My situation was this: I liked the Awk processing model, but I didn't like the language itself. And I liked Python, but it didn't have Awk's processing model. So I decided to combine the two, and came up with the current framework.
The framework resides in
awk.py.
This module contains one class, controller, which
implements the following methods:
__init__(file) - the constructor, which takes a
file object to process.
subscribe(handler) - subscribes a handler to the controller.
run() - processes the file.
print_results() - prints the results of the process.
A handler is a class that implements a defined set of methods. Multiple handlers can be subscribed to the controller at any given time. Every handler must implement the following methods:
begin() - gets called once before the file is processed.
process_line(line) - gets called for each line of the file.
end() - gets called after the file is processed.
description() - gets called from
controller.print_results(). It should
return a description of the handler.
result() - also called from
controller.print_results().
It should return the results of the class' calculations.
You create handlers, subscribe them to the controller, and then run the controller. The following is a simple example with one handler:
Listing 2: count_lines.py
# Standard sys module import sys # Custom awk.py module import awk class count_lines: def begin(self): self.m_count = 0 def process_line(self, s): self.m_count += 1 def end(self): pass def description(self): return "# of lines in the file" def result(self): return self.m_count # # Step 1: Create the Awk controller # ac = awk.controller(sys.stdin) # # Step 2: Subscribe the handler # ac.subscribe(count_lines()) # # Step 3: Run # ac.run() # # Step 4: Print the results # ac.print_results()
You can run this script using the following command:
prompt$ cat access_log | python count_lines.py
The results of the script should be printed to the console.
Now that the framework was in place, I had to figure out how I was going to use it. I came up with many ideas, but the following two were the top priorities.
The first question that I wanted to answer using my new framework was the following:
My thinking was this: if people return often, they must enjoy the site, right? The following script answers the above question:
Listing 3: return_visitors (can be found in handlers.py)
class return_visitors:
def __init__(self, n):
self.m_n = n
self.m_ip_days = {}
def begin(self):
pass
def process_line(self, s):
try:
array = s.split()
ip = array[0]
day = array[3][1:7]
if self.m_ip_days.has_key(ip):
if day not in self.m_ip_days[ip]:
self.m_ip_days[ip].append(day)
else:
self.m_ip_days[ip] = []
self.m_ip_days[ip].append(day)
except IndexError:
pass
def end(self):
ips = self.m_ip_days.keys()
count = 0
for ip in ips:
if len(self.m_ip_days[ip]) > self.m_n:
count += 1
self.m_count = count
def description(self):
return "# of IP addresses that visited more than %s days" % self.m_n
def result(self):
return self.m_count
The script stores the number of days that each IP address has visited the site. When the file is finished processing, it returns how many IP addresses have visited more than N times.
Another thing I wanted to know was how people found out about the site. I was getting a decent amount of traffic, and I wasn't sure why. I kept asking myself:
I guess you shouldn't argue with a site that's popular. But I was curious to know how people were learning about my site. So I wrote the following script:
Listing 4: referring_domains (can be found in handlers.py)
class referring_domains:
def __init__(self):
self.m_domains = {}
def begin(self):
pass
def process_line(self, line):
try:
array = line.split()
referrer = array[10]
m = re.search('//[a-zA-Z0-9\-\.]*\.[a-zA-z]{2,3}/',
referrer)
length = len(m.group(0))
domain = m.group(0)[2:length-1]
if self.m_domains.has_key(domain):
self.m_domains[domain] += 1
else:
self.m_domains[domain] = 1
except AttributeError:
pass
except IndexError:
pass
def end(self):
pass
def description(self):
return "Referring domains"
def sort(self, key1, key2):
if self.m_domains[key1] > self.m_domains[key2]:
return -1
elif self.m_domains[key1] == self.m_domains[key2]:
return 0
else:
return 1
def result(self):
s = ""
keys = self.m_domains.keys()
keys.sort(self.sort)
for domain in keys:
s += domain
s += " "
s += str(self.m_domains[domain])
s += "\n"
s += "\n\n"
return s
This script stores the referral information for each request, and generates a list of referring domains, sorted by frequency.
I ran the script and found that most of the referrals came from my own site. This makes sense - when a visitor moves from one page to another on the site, the referring domain for the page is my web site's domain. But I did find some interesting entries in the referral list, and my question about site traffic was answered.
The following files contain the code from this article:
controller class
count_lines handler
return_visitors and referring_domains handlers
In this article I described how I use Python to process my Apache HTTP Server access log. Hopefully I explained my techniques clearly enough so that you can use them for your text files.
|
...making Linux just a little more fun! |
By Alan Ward |
Why subnet?
As hardware prices go down and local networks grow larger, a new size of local network is becoming common: the size in between the small office (5-10 hosts) and the large corporate building-sized LAN (more than 50 hosts).
With less than 10 hosts, it is generally easy to manage the network: all hosts get on to the same Ethernet segment, and security -- if necessary -- is implemented at host level: passwords and such. With more than 50 hosts, you can generally obtain funding for managed switches than can define virtual networks (VLANs). The Accounting Department will go on one VLAN, Production on another and so forth. Every host will have access to other hosts in its VLAN and to the company servers, but not across VLANs. Security is managed at both host and network levels.
On middlish-sized local networks however, we often must put all hosts on the same segment once more. Recent cheap LAN switches are capable of handling traffic between up to 50 hosts easily. However, switches with VLAN capability are much more expensive. Well-known brands are selling for upwards of US $1200 for a 24-port switch, which may be worth it -- but is completely out of many budgets. Mine for one.
DHCP and subnetworks
One of the local networks I administer in the school I work in is a long string of non-managed Ethernet switches. This is basically because of how the building was initially drawn up. On this, I must handle traffic from several different types of host; to simplify let's say I have teacher-level traffic (group A) and student-level traffic (group B). These must not mix: I do not want people from each group accessing the other group's files or printers (passwords tend to be weaker than I would like).
The simplest way to separate the groups at logical level is to give each group a different IP network address. For example, group A gets addresses on network 192.168.10.0 (e.g. 192.168.10.12), while group B get addresses on network 192.168.20.0 (e.g. 192.168.20.34). Servers that are present on both must have an address on each network.
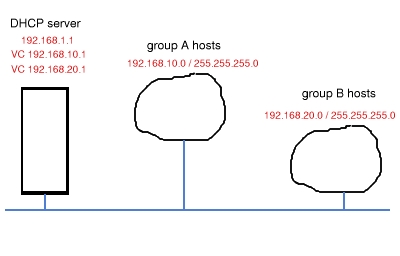
Our network topology
A DHCP server is a good way of doing this. This is the service you access when using a dial-up Internet connection: you connect to your ISP, who assigns you a temporary public IP address. Most Linux distributions include a DHCP server, which can also be used on a local network.
Initially, you can give the DHCP server a range of IP addresses to distribute: for example 192.168.1.100 to 192.168.1.199. Any host that starts up and asks for an address will get one of these. After the host is switched back off, the address will be liberated and can be re-used on another host if needed.
But Ethernet cards all carry a unique identification number, called a MAC address. This is a 12-digit hexadecimal number that is assigned by the manufacturer, and that is guaranteed to be different from any other Ethernet card, anywhere in the world. A DHCP server can be configured to use this MAC address to always assign the same IP address to the host.
Using this, we can make a list of the MAC addresses of the hosts in our group A, and make DHCP serve them fixed IP addresses on the 192.168.10.0 subnet. The MAC addresses of hosts in group B are served addresses on the 192.168.20.0 subnet, and hosts that are not on either list (visitors' laptops, for example) get an address on subnet 192.168.1.0 .
DHCP has an advantage over VLANs in this respect: VLANs are defined for physical network ports, while DHCP uses card addresses. With a VLAN, if you physically change your computer's network connection -- as in moving from one room to another -- you may also change its VLAN. With DHCP however, its subnet assignation will remain the same.
Setting up DHCP
On most Linux distributions, the DHCP server is called dhcpd, and is started with the standard scripts (the same as httpd, postfix, ...). It can be found in RPM form, as for example in dhcp-3.0-3mdk.i386.rpm. If you already have it installed on your system, try the dhcpd and dhcpd.conf man pages.
To begin, I used the webmin utility to set up a basic subnet DHCP service. Notice that this service has to be on network 192.168.0.0 with netmask 255.255.0.0 . This is because it must be accessible from al subnets.
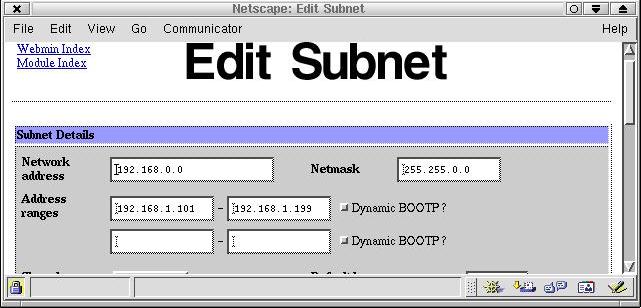
I then set up each specific host, specifying it's name, hardware MAC address and the IP address I want to serve to it. Note the IP address, now on subnet 192.168.10.0 .
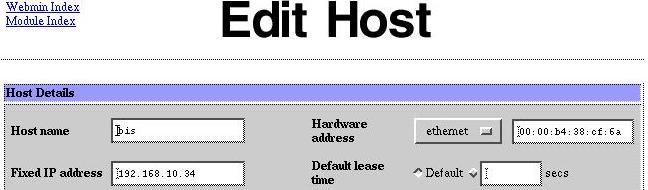
To obtain the Ethernet MAC address, most cards have it printed on a label sticking to the card. It yours does not, you can skip this step for the moment. Finish setting up the DHCP service and fire up the hosts one by one. As each host obtains an IP address (on subnet 192.168.1.0 for the time being), you will see it appear in file /var/lib/dhcp/dhcpd.leases. For example:
lease 192.168.1.198 {
hardware ethernet 00:00:b4:38:cf:6a;
client-hostname "bis";
}
Please note that only addresses obtained from the general subnet will appear here; not when you have given a host a fixed address.
Finish setting up the fixed addresses for hosts on the DHCP server.
Start or restart the DHCP server. Hosts should now be obtaining their assigned IP addresses. You can see this on a Linux host with the ifconfig utility. On a Windows box, you can use winipcfg under Win95/98/ME, or ipconfig (in a terminal window) under WinNT/2k.
But network masks should now still be the default 255.255.0.0 . This is not good, as hosts on subnets 192.168.10.0 and 192.168.20.0 can see each others (try a ping). We should now go to each host definition for dhcpd, and in the "edit client options" set its subnet mask as 255.255.255.0 and its default router to 192.168.X.1 for subnet 192.168.X.0 . For example, on subnet 192.168.10.0:
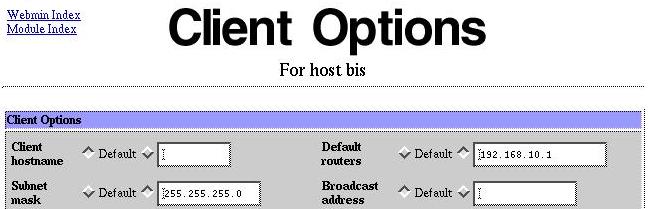
Remember to also set the network mask to 255.255.255.0 for the general 192.168.0.0 subnet client options.
You can edit the /etc/dhcpd.conf file by hand. It may even be more clear than the webmin interface. This is what you could have:
#
# main subnet, accessed by default by hosts we do not know
#
subnet 192.168.0.0 netmask 255.255.0.0 {
option subnet-mask 255.255.255.0;
option routers 192.168.1.1;
range 192.168.1.101 192.168.1.199;
}
#
# host definition, one for each known host on our LAN
#
host bis {
option subnet-mask 255.255.255.0;
option routers 192.168.10.1;
hardware ethernet 00:00:b4:38:cf:6a; # 12-digit hex MAC address
fixed-address 192.168.10.34;
}
Making the server accessible
In the above example, we made 192.168.X.1 the default router for each
subnet 192.168.X.0 . But for the time being, our server has IP address
192.168.1.1 -- which means that:
This is why our server must have an extra IP address for each subnet: 192.168.10.1, 192.168.20.1, etc. This can easily be set up by creating virtual network cards eth0:1, eth0:2, etc. with webmin:

You can also create this by hand. On a Mandrake or Red Hat distribution, the files are in /etc/sysconfig/network-scripts. You should already have a file called ifcfg-eth0. Copy this as ifcfg-eth0:1, ifcfg-eth0:2, ... changing the addresses and netmasks as appropriate. For example, for eth0:1 :
BROADCAST=192.168.10.0 DEVICE=eth0:1 NETMASK=255.255.255.0 IPADDR=192.168.10.1 NETWORK=192.168.10.0 ONBOOT=yes BOOTPROTO=none
This is basically all you need. You may now have to enable routing on the server, for example if you are using it to access Internet. But be careful to disable routing between local subnets; 192.168.X.0 should not be able to see 192.168.Y.0 . Use a firewalling package such as iptables to block this. You can also use this to block or allow Internet access from any or all subnets if you wish.
PS. Should anybody want to translate this article: I wrote it in the spirit of the GPL software licence. i.e. you are free (and indeed encouraged) to copy, post and translate it -- but please, PLEASE, send me notice by email! I like to keep track of translations -- it's good for the curriculum :-)
|
...making Linux just a little more SCARY!!! |
By Mike ("Iron") Orr |
LG now has Author pages. Starting this issue, every author gets a page with his or her contact information, bio, and links to all the articles s/he has written. The "By <author>" link at the top of each article will now go to the Author's page. There's also an author index if you want to browse. The former TAG Bios have also turned into Author pages, and the TAG Bios index page has been turned into a set of links.
Over time, we will gradually clean up the links in the back isues and try to eliminate symlinks from LG. Some people read LG offline on systems without symbolic links, and find it difficult when the files don't exist. However, we will maintain the "current/" link at least, pointing to the current issue.
The Register reports that if you type "go to hell" into Google, the first result is "Microsoft Corporation, Where do you want to go today?" Number two is hell.com, "which seems to be a very weird site we do not understand".
Hell.com has now regained the #1 slot, and Microsoft is not to be seen. Cynics might wonder if Bill Gates did a backroom deal with Google to get their entry off the results.
Kitchen chemistryAnswered By Ben Okopnik, Iron, Dan Wilder and Heather Stern
What hapens when bicarb is added to a week acid?
![]() [Ben]
Takes two weeks to come down off the trip, dude. It's like, unreal.
[Ben]
Takes two weeks to come down off the trip, dude. It's like, unreal.
(Yes, I just got back from California. Why do you ask?)
![]() [Iron]
Like totally, dude.
[Iron]
Like totally, dude.
![]() [Dan]
Same thing as when it is added to a month acid, but faster.
[Dan]
Same thing as when it is added to a month acid, but faster.
![]() [Heather]
You wanted "Cecil Adams, The Straight Dope" -- he does stuff like that.
"Women's Day" could probably answer you too.
[Heather]
You wanted "Cecil Adams, The Straight Dope" -- he does stuff like that.
"Women's Day" could probably answer you too.
We're "The Linux Gazette Answer Gang" -- we answer Linux questions, not chemistry matters.
Please advise us where you encountered the "linux-questions-only@ssc.com" address and what implied to you that it addressed general questions. We're trying to chase down old references and get them updated.
Police found seven rounds in the house, Jorgensen said.
Although they did not give a motive, police said they do not believe the shooting was random.
Only the woman and her husband, who are both in their 40s, live at the home, Jorgensen said.
-- http://seattlepi.nwsource.com/local/89150_filler30.shtml
Happy Linuxing!
Mike ("Iron") Orr
Editor, Linux Gazette, gazette@ssc.com
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}