The Linux System Administrator's Guide
Version 0.9
Lars Wirzenius
Joanna Oja
Stephen Stafford
Alex Weeks
Copyright 1993--1998 Lars Wirzenius.
Copyright 1998--2001 Joanna Oja.
Copyright 2001--2003 Stephen Stafford.
Copyright 2003--2004 Stephen Stafford & Alex Weeks.
Copyright 2004--Present Alex Weeks.
Trademarks are owned by their owners.
Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled "GNU Free Documentation License".
- Table of Contents
- About This Book
- 1. Introduction
- 2. Overview of a Linux System
- 3. Overview of the Directory Tree
- 3.1. Background
- 3.2. The root filesystem
- 3.3. The /etc directory
- 3.4. The /dev directory
- 3.5. The /usr filesystem.
- 3.6. The /var filesystem
- 3.7. The /proc filesystem
- 4. Hardware, Devices, and Tools
- 4.1. Hardware Utilities
- 4.2. Kernel Modules
- 5. Using Disks and Other Storage Media
- 5.1. Two kinds of devices
- 5.2. Hard disks
- 5.3. Storage Area Networks - Draft
- 5.4. Network Attached Storage - Draft
- 5.5. Floppies
- 5.6. CD-ROMs
- 5.7. Tapes
- 5.8. Formatting
- 5.9. Partitions
- 5.10. Filesystems
- 5.11. Disks without filesystems
- 5.12. Allocating disk space
- 6. Memory Management
- 7. System Monitoring
- 7.1. System Resources
- 7.2. Filesystem Usage
- 7.3. Monitoring Users
- 8. Boots And Shutdowns
- 9. init
- 10. Logging In And Out
- 10.1. Logins via terminals
- 10.2. Logins via the network
- 10.3. What login does
- 10.4. X and xdm
- 10.5. Access control
- 10.6. Shell startup
- 11. Managing user accounts
- 11.1. What's an account?
- 11.2. Creating a user
- 11.3. Changing user properties
- 11.4. Removing a user
- 11.5. Disabling a user temporarily
- 12. Backups
- 12.1. On the importance of being backed up
- 12.2. Selecting the backup medium
- 12.3. Selecting the backup tool
- 12.4. Simple backups
- 12.5. Multilevel backups
- 12.6. What to back up
- 12.7. Compressed backups
- 13. Task Automation --To Be Added
- 14. Keeping Time
- 14.1. The concept of localtime
- 14.2. The hardware and software clocks
- 14.3. Showing and setting time
- 14.4. When the clock is wrong
- 14.5. NTP - Network Time Protocol
- 14.6. Basic NTP configuration
- 14.7. NTP Toolkit
- 14.8. Some known NTP servers
- 14.9. NTP Links
- 15. System Logs --To Be Added
- 16. System Updates --To Be Added
- 17. The Linux Kernel Source
- 18. Finding Help
- 18.1. Newsgroups and Mailing Lists
- 18.2. IRC
- A. GNU Free Documentation License
- A.1. PREAMBLE
- A.2. APPLICABILITY AND DEFINITIONS
- A.3. VERBATIM COPYING
- A.4. COPYING IN QUANTITY
- A.5. MODIFICATIONS
- A.6. COMBINING DOCUMENTS
- A.7. COLLECTIONS OF DOCUMENTS
- A.8. AGGREGATION WITH INDEPENDENT WORKS
- A.9. TRANSLATION
- A.10. TERMINATION
- A.11. FUTURE REVISIONS OF THIS LICENSE
- A.12. ADDENDUM: How to use this License for your documents
- Glossary (DRAFT, but not for long hopefully)
- Index-Draft
- List of Tables
- 5-1. Comparing Filesystem Features
- 5-2. Sizes
- 5-3. My Partitions
- 9-1. Run level numbers
- 12-1. Efficient backup scheme using many backup levels
- List of Figures
- 2-1. Some of the more important parts of the Linux kernel
- 3-1. Parts of a Unix directory tree. Dashed lines indicate partition limits.
- 5-1. A schematic picture of a hard disk.
- 5-2. A sample hard disk partitioning.
- 5-3. Three separate filesystems.
- 5-4. /home and /usr have been mounted.
- 10-1. Logins via terminals: the interaction of init, getty, login, and the shell.
- 12-1. A sample multilevel backup schedule.
About This Book
"Only two things are infinite, the universe and human stupidity, and I'm not sure about the former." Albert Einstein
1. Acknowledgments
1.1. Joanna's acknowledgments
Many people have helped me with this book, directly or indirectly. I would like to especially thank Matt Welsh for inspiration and LDP leadership, Andy Oram for getting me to work again with much-valued feedback, Olaf Kirch for showing me that it can be done, and Adam Richter at Yggdrasil and others for showing me that other people can find it interesting as well.
Stephen Tweedie, H. Peter Anvin, Remy Card, Theodore Ts'o, and Stephen Tweedie have let me borrow their work (and thus make the book look thicker and much more impressive): a comparison between the xia and ext2 filesystems, the device list and a description of the ext2 filesystem. These aren't part of the book any more. I am most grateful for this, and very apologetic for the earlier versions that sometimes lacked proper attribution.
In addition, I would like to thank Mark Komarinski for sending his material in 1993 and the many system administration columns in Linux Journal. They are quite informative and inspirational.
Many useful comments have been sent by a large number of people. My miniature black hole of an archive doesn't let me find all their names, but some of them are, in alphabetical order: Paul Caprioli, Ales Cepek, Marie-France Declerfayt, Dave Dobson, Olaf Flebbe, Helmut Geyer, Larry Greenfield and his father, Stephen Harris, Jyrki Havia, Jim Haynes, York Lam, Timothy Andrew Lister, Jim Lynch, Michael J. Micek, Jacob Navia, Dan Poirier, Daniel Quinlan, Jouni K Sepp�nen, Philippe Steindl, G.B. Stotte. My apologies to anyone I have forgotten.
1.2. Stephen's acknowledgments
I would like to thank Lars and Joanna for their hard work on the guide.
In a guide like this one there are likely to be at least some minor inaccuracies. And there are almost certainly going to be sections that become out of date from time to time. If you notice any of this then please let me know by sending me an email to: <bagpuss@debian.org.NOSPAM>. I will take virtually any form of input (diffs, just plain text, html, whatever), I am in no way above allowing others to help me maintain such a large text as this :)
Many thanks to Helen Topping Shaw for getting the red pen out and making the text far better than it would otherwise have been. Also thanks are due just for being wonderful.
1.3. Alex's Acknowledgments
I would like to thank Lars, Joanna, and Stephen for all the great work that they have done on this document over the years. I only hope that my contribution will be worthy of continuing the work they started.
Like the previous maintainers, I openly welcome any comments, suggestions, complains, corrections, or any other form of feedback you may have. This document can only benefit from the suggestions of those who use it.
There have been many people who have helped me on my journey through the "Windows-Free" world, the person I feel I need to thank the most is my first true UN*X mentor, Mike Velasco. Back in a time before SCO became a "dirty word", Mike helped me on the path of tar's, cpio's, and many, many man pages. Thanks Mike! You are the 'Sofa King'.
2. Revision History
3. Source and pre-formatted versions available
The source code and other machine readable formats of this book can be found on the Internet via anonymous FTP at the Linux Documentation Project home page http://www.tldp.org/, or at the home page of this book at http://www.draxeman/sag.html. This book is available in at least it's SGML source, as well as, HTML and PDF formats. Other formats may be available.
4. Typographical Conventions
Throughout this book, I have tried to use uniform typographical conventions. Hopefully they aid readability. If you can suggest any improvements please contact me.
Filenames are expressed as: /usr/share/doc/foo.
Command names are expressed as: fsck
Email addresses are expressed as: <user@domain.com>
URLs are expressed as: http://www.tldp.org
I will add to this section as things come up whilst editing. If you notice anything that should be added then please let me know.
Chapter 1. Introduction
"In the beginning, the file was without form, and void; and emptiness was upon the face of the bits. And the Fingers of the Author moved upon the face of the keyboard. And the Author said, Let there be words, and there were words."
The Linux System Administrator's Guide, describes the system administration aspects of using Linux. It is intended for people who know next to nothing about system administration (those saying ``what is it?''), but who have already mastered at least the basics of normal usage. This manual doesn't tell you how to install Linux; that is described in the Installation and Getting Started document. See below for more information about Linux manuals.
System administration covers all the things that you have to do to keep a computer system in usable order. It includes things like backing up files (and restoring them if necessary), installing new programs, creating accounts for users (and deleting them when no longer needed), making certain that the filesystem is not corrupted, and so on. If a computer were, say, a house, system administration would be called maintenance, and would include cleaning, fixing broken windows, and other such things.
The structure of this manual is such that many of the chapters should be usable independently, so if you need information about backups, for example, you can read just that chapter. However, this manual is first and foremost a tutorial and can be read sequentially or as a whole.
This manual is not intended to be used completely independently. Plenty of the rest of the Linux documentation is also important for system administrators. After all, a system administrator is just a user with special privileges and duties. Very useful resources are the manual pages, which should always be consulted when you are not familiar with a command. If you do not know which command you need, then the apropos command can be used. Consult its manual page for more details.
While this manual is targeted at Linux, a general principle has been that it should be useful with other UNIX based operating systems as well. Unfortunately, since there is so much variance between different versions of UNIX in general, and in system administration in particular, there is little hope to cover all variants. Even covering all possibilities for Linux is difficult, due to the nature of its development.
There is no one official Linux distribution, so different people have different setups and many people have a setup they have built up themselves. This book is not targeted at any one distribution. Distributions can and do vary considerably. When possible, differences have been noted and alternatives given. For a list of distributions and some of their differences see http://en.wikipedia.org/wiki/Comparison_of_Linux_distributions.
In trying to describe how things work, rather than just listing ``five easy steps'' for each task, there is much information here that is not necessary for everyone, but those parts are marked as such and can be skipped if you use a preconfigured system. Reading everything will, naturally, increase your understanding of the system and should make using and administering it more productive.
Understanding is the key to success with Linux. This book could just provide recipes, but what would you do when confronted by a problem this book had no recipe for? If the book can provide understanding, then recipes are not required. The answers will be self evident.
Like all other Linux related development, the work to write this manual was done on a volunteer basis: I did it because I thought it might be fun and because I felt it should be done. However, like all volunteer work, there is a limit to how much time, knowledge and experience people have. This means that the manual is not necessarily as good as it would be if a wizard had been paid handsomely to write it and had spent millennia to perfect it. Be warned.
One particular point where corners have been cut is that many things that are already well documented in other freely available manuals are not always covered here. This applies especially to program specific documentation, such as all the details of using mkfs. Only the purpose of the program and as much of its usage as is necessary for the purposes of this manual is described. For further information, consult these other manuals. Usually, all of the referred to documentation is part of the full Linux documentation set.
1.1. Linux or GNU/Linux, that is the question.
Many people feel that Linux should really be called GNU/Linux. This is because Linux is only the kernel, not the applications that run on it. Most of the basic command line utilities were written by the Free Software Foundation while developing their GNU operating system. Among those utilities are some of the most basic commands like cp, mv lsof, and dd.
In a nutshell, what happened was, the FSF started developing GNU by writing things like compliers, C libraries, and basic command line utilities before the kernel. Linus Torvalds, started Linux by writing the Linux kernel first and using applications written for GNU.
I do not feel that this is the proper forum to debate what name people should use when referring to Linux. I mention it here, because I feel it is important to understand the relationship between GNU and Linux, and to also explain why some Linux is sometimes referred to as GNU/Linux. The document will be simply referring to it as Linux.
GNU's side of the issue is discussed on their website:
The relationship - http://www.gnu.org/gnu/linux-and-gnu.html
Why Linux should be GNU/Linux - http://www.gnu.org/gnu/why-gnu-linux.html
GNU/Linux FAQ's - http://www.gnu.org/gnu/gnu-linux-faq.html
Here are some Alternate views:
http://librenix.com/?inode=2312
1.2. Trademarks
Microsoft, Windows, Windows NT, Windows 2000, and Windows XP are trademarks and/or registered trademarks of Microsoft Corporation.
Red Hat is a trademark of Red Hat, Inc., in the United States and other countries.
SuSE is a trademark of Novell.
Linux is a registered trademark of Linus Torvalds.
UNIX is a registered trademark in the United States and other countries, licensed exclusively through X/Open Company Ltd.
GNU is a registered trademark of the Free Software Foundation.
Other product names mentioned herein may be trademarks and/or registered trademarks of their respective companies.
Chapter 2. Overview of a Linux System
"God saw everything that he had made, and saw that it was very good. " -- Bible King James Version. Genesis 1:31
This chapter gives an overview of a Linux system. First, the major services provided by the operating system are described. Then, the programs that implement these services are described with a considerable lack of detail. The purpose of this chapter is to give an understanding of the system as a whole, so that each part is described in detail elsewhere.
2.1. Various parts of an operating system
UNIX and 'UNIX-like' operating systems (such as Linux) consist of a kernel and some system programs. There are also some application programs for doing work. The kernel is the heart of the operating system. In fact, it is often mistakenly considered to be the operating system itself, but it is not. An operating system provides provides many more services than a plain kernel.
It keeps track of files on the disk, starts programs and runs them concurrently, assigns memory and other resources to various processes, receives packets from and sends packets to the network, and so on. The kernel does very little by itself, but it provides tools with which all services can be built. It also prevents anyone from accessing the hardware directly, forcing everyone to use the tools it provides. This way the kernel provides some protection for users from each other. The tools provided by the kernel are used via system calls. See manual page section 2 for more information on these.
The system programs use the tools provided by the kernel to implement the various services required from an operating system. System programs, and all other programs, run `on top of the kernel', in what is called the user mode. The difference between system and application programs is one of intent: applications are intended for getting useful things done (or for playing, if it happens to be a game), whereas system programs are needed to get the system working. A word processor is an application; mount is a system program. The difference is often somewhat blurry, however, and is important only to compulsive categorizers.
An operating system can also contain compilers and their corresponding libraries (GCC and the C library in particular under Linux), although not all programming languages need be part of the operating system. Documentation, and sometimes even games, can also be part of it. Traditionally, the operating system has been defined by the contents of the installation tape or disks; with Linux it is not as clear since it is spread all over the FTP sites of the world.
2.2. Important parts of the kernel
The Linux kernel consists of several important parts: process management, memory management, hardware device drivers, filesystem drivers, network management, and various other bits and pieces. Figure 2-1 shows some of them.
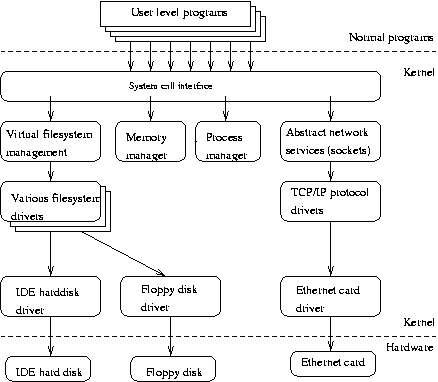
Probably the most important parts of the kernel (nothing else works without them) are memory management and process management. Memory management takes care of assigning memory areas and swap space areas to processes, parts of the kernel, and for the buffer cache. Process management creates processes, and implements multitasking by switching the active process on the processor.
At the lowest level, the kernel contains a hardware device driver for each kind of hardware it supports. Since the world is full of different kinds of hardware, the number of hardware device drivers is large. There are often many otherwise similar pieces of hardware that differ in how they are controlled by software. The similarities make it possible to have general classes of drivers that support similar operations; each member of the class has the same interface to the rest of the kernel but differs in what it needs to do to implement them. For example, all disk drivers look alike to the rest of the kernel, i.e., they all have operations like `initialize the drive', `read sector N', and `write sector N'.
Some software services provided by the kernel itself have similar properties, and can therefore be abstracted into classes. For example, the various network protocols have been abstracted into one programming interface, the BSD socket library. Another example is the virtual filesystem (VFS) layer that abstracts the filesystem operations away from their implementation. Each filesystem type provides an implementation of each filesystem operation. When some entity tries to use a filesystem, the request goes via the VFS, which routes the request to the proper filesystem driver.
A more in-depth discussion of kernel internals can be found at http://www.tldp.org/LDP/lki/index.html. This document was written for the 2.4 kernel. When I find one for the 2.6 kernel, I will list it here.
2.3. Major services in a UNIX system
This section describes some of the more important UNIX services, but without much detail. They are described more thoroughly in later chapters.
2.3.1. init
The single most important service in a UNIX system is provided by init init is started as the first process of every UNIX system, as the last thing the kernel does when it boots. When init starts, it continues the boot process by doing various startup chores (checking and mounting filesystems, starting daemons, etc).
The exact list of things that init does depends on which flavor it is; there are several to choose from. init usually provides the concept of single user mode, in which no one can log in and root uses a shell at the console; the usual mode is called multiuser mode. Some flavors generalize this as run levels; single and multiuser modes are considered to be two run levels, and there can be additional ones as well, for example, to run X on the console.
Linux allows for up to 10 runlevels, 0-9, but usually only some of these are defined by default. Runlevel 0 is defined as ``system halt''. Runlevel 1 is defined as ``single user mode''. Runlevel 3 is defined as "multi user" because it is the runlevel that the system boot into under normal day to day conditions. Runlevel 5 is typically the same as 3 except that a GUI gets started also. Runlevel 6 is defined as ``system reboot''. Other runlevels are dependent on how your particular distribution has defined them, and they vary significantly between distributions. Looking at the contents of /etc/inittab usually will give some hint what the predefined runlevels are and what they have been defined as.
In normal operation, init makes sure getty is working (to allow users to log in) and to adopt orphan processes (processes whose parent has died; in UNIX all processes must be in a single tree, so orphans must be adopted).
When the system is shut down, it is init that is in charge of killing all other processes, unmounting all filesystems and stopping the processor, along with anything else it has been configured to do.
2.3.2. Logins from terminals
Logins from terminals (via serial lines) and the console (when not running X) are provided by the getty program. init starts a separate instance of getty for each terminal upon which logins are to be allowed. getty reads the username and runs the loginprogram, which reads the password. If the username and password are correct, login runs the shell. When the shell terminates, i.e., the user logs out, or when login terminated because the username and password didn't match, init notices this and starts a new instance of getty. The kernel has no notion of logins, this is all handled by the system programs.
2.3.3. Syslog
The kernel and many system programs produce error, warning, and other messages. It is often important that these messages can be viewed later, even much later, so they should be written to a file. The program doing this is syslog . It can be configured to sort the messages to different files according to writer or degree of importance. For example, kernel messages are often directed to a separate file from the others, since kernel messages are often more important and need to be read regularly to spot problems.
Chapter 15 will provide more on this.
2.3.4. Periodic command execution: cron and at
Both users and system administrators often need to run commands periodically. For example, the system administrator might want to run a command to clean the directories with temporary files (/tmp and /var/tmp) from old files, to keep the disks from filling up, since not all programs clean up after themselves correctly.
The cron service is set up to do this. Each user can have a crontab file, where she lists the commands she wishes to execute and the times they should be executed. The cron daemon takes care of starting the commands when specified.
The at service is similar to cron, but it is once only: the command is executed at the given time, but it is not repeated.
We will go more into this later. See the manual pages cron(1), crontab(1), crontab(5), at(1) and atd(8) for more in depth information.
Chapter 13 will cover this.
2.3.5. Graphical user interface
UNIX and Linux don't incorporate the user interface into the kernel; instead, they let it be implemented by user level programs. This applies for both text mode and graphical environments.
This arrangement makes the system more flexible, but has the disadvantage that it is simple to implement a different user interface for each program, making the system harder to learn.
The graphical environment primarily used with Linux is called the X Window System (X for short). X also does not implement a user interface; it only implements a window system, i.e., tools with which a graphical user interface can be implemented. Some popular window managers are: fvwm , icewm , blackbox , and windowmaker . There are also two popular desktop managers, KDE and Gnome.
2.3.6. Networking
Networking is the act of connecting two or more computers so that they can communicate with each other. The actual methods of connecting and communicating are slightly complicated, but the end result is very useful.
UNIX operating systems have many networking features. Most basic services (filesystems, printing, backups, etc) can be done over the network. This can make system administration easier, since it allows centralized administration, while still reaping in the benefits of microcomputing and distributed computing, such as lower costs and better fault tolerance.
However, this book merely glances at networking; see the Linux Network Administrators' Guide http://www.tldp.org/LDP/nag2/index.html for more information, including a basic description of how networks operate.
2.3.7. Network logins
Network logins work a little differently than normal logins. For each person logging in via the network there is a separate virtual network connection, and there can be any number of these depending on the available bandwidth. It is therefore not possible to run a separate getty for each possible virtual connection. There are also several different ways to log in via a network, telnet and ssh being the major ones in TCP/IP networks.
These days many Linux system administrators consider telnet and rlogin to be insecure and prefer ssh, the ``secure shell'', which encrypts traffic going over the network, thereby making it far less likely that the malicious can ``sniff'' your connection and gain sensitive data like usernames and passwords. It is highly recommended you use ssh rather than telnet or rlogin.
Network logins have, instead of a herd of gettys, a single daemon per way of logging in (telnet and ssh have separate daemons) that listens for all incoming login attempts. When it notices one, it starts a new instance of itself to handle that single attempt; the original instance continues to listen for other attempts. The new instance works similarly to getty.
2.3.8. Network file systems
One of the more useful things that can be done with networking services is sharing files via a network file system. Depending on your network this could be done over the Network File System (NFS), or over the Common Internet File System (CIFS). NFS is typically a 'UNIX' based service. In Linux, NFS is supported by the kernel. CIFS however is not. In Linux, CIFS is supported by Samba http://www.samba.org.
With a network file system any file operations done by a program on one machine are sent over the network to another computer. This fools the program to think that all the files on the other computer are actually on the computer the program is running on. This makes information sharing extremely simple, since it requires no modifications to programs.
This will be covered in more detail in Section 5.4.
2.3.9. Mail
Electronic mail is the most popularly used method for communicating via computer. An electronic letter is stored in a file using a special format, and special mail programs are used to send and read the letters.
Each user has an incoming mailbox (a file in the special format), where all new mail is stored. When someone sends mail, the mail program locates the receiver's mailbox and appends the letter to the mailbox file. If the receiver's mailbox is in another machine, the letter is sent to the other machine, which delivers it to the mailbox as it best sees fit.
The mail system consists of many programs. The delivery of mail to local or remote mailboxes is done by one program (the mail transfer agent (MTA) , e.g., sendmail or postfix ), while the programs users use are many and varied (mail user agent (MUA) , e.g., pine , or evolution . The mailboxes are usually stored in /var/spool/mail until the user's MUA retrieves them.
For more information on setting up and running mail services you can read the Mail Administrator HOWTO at http://www.tldp.org/HOWTO/Mail-Administrator-HOWTO.html, or visit the sendmail or postfix's website. http://www.sendmail.org/, or http://www.postfix.org/ .
2.3.10. Printing
Only one person can use a printer at one time, but it is uneconomical not to share printers between users. The printer is therefore managed by software that implements a print queue: all print jobs are put into a queue and whenever the printer is done with one job, the next one is sent to it automatically. This relieves the users from organizing the print queue and fighting over control of the printer. Instead, they form a new queue at the printer, waiting for their printouts, since no one ever seems to be able to get the queue software to know exactly when anyone's printout is really finished. This is a great boost to intra-office social relations.
The print queue software also spools the printouts on disk, i.e., the text is kept in a file while the job is in the queue. This allows an application program to spit out the print jobs quickly to the print queue software; the application does not have to wait until the job is actually printed to continue. This is really convenient, since it allows one to print out one version, and not have to wait for it to be printed before one can make a completely revised new version.
You can refer to the Printing-HOWTO located at http://www.tldp.org/HOWTO/Printing-HOWTO/index.html for more help in setting up printers.
2.3.11. The filesystem layout
The filesystem is divided into many parts; usually along the lines of a root filesystem with /bin , /lib , /etc , /dev , and a few others; a /usr filesystem with programs and unchanging data; /var filesystem with changing data (such as log files); and a /home for everyone's personal files. Depending on the hardware configuration and the decisions of the system administrator, the division can be different; it can even be all in one filesystem.
Chapter 3 describes the filesystem layout in some little detail; the Filesystem Hierarchy Standard . covers it in somewhat more detail. This can be found on the web at: http://www.pathname.com/fhs/
Chapter 3. Overview of the Directory Tree
" Two days later, there was Pooh, sitting on his branch, dangling his legs, and there, beside him, were four pots of honey..." (A.A. Milne)
This chapter describes the important parts of a standard Linux directory tree, based on the Filesystem Hierarchy Standard . It outlines the normal way of breaking the directory tree into separate filesystems with different purposes and gives the motivation behind this particular split. Not all Linux distributions follow this standard slavishly, but it is generic enough to give you an overview.
3.1. Background
This chapter is loosely based on the Filesystems Hierarchy Standard (FHS). version 2.1, which attempts to set a standard for how the directory tree in a Linux system is organized. Such a standard has the advantage that it will be easier to write or port software for Linux, and to administer Linux machines, since everything should be in standardized places. There is no authority behind the standard that forces anyone to comply with it, but it has gained the support of many Linux distributions. It is not a good idea to break with the FHS without very compelling reasons. The FHS attempts to follow Unix tradition and current trends, making Linux systems familiar to those with experience with other Unix systems, and vice versa.
This chapter is not as detailed as the FHS. A system administrator should also read the full FHS for a complete understanding.
This chapter does not explain all files in detail. The intention is not to describe every file, but to give an overview of the system from a filesystem point of view. Further information on each file is available elsewhere in this manual or in the Linux manual pages.
The full directory tree is intended to be breakable into smaller parts, each capable of being on its own disk or partition, to accommodate to disk size limits and to ease backup and other system administration tasks. The major parts are the root (/ ), /usr , /var , and /home filesystems (see Figure 3-1). Each part has a different purpose. The directory tree has been designed so that it works well in a network of Linux machines which may share some parts of the filesystems over a read-only device (e.g., a CD-ROM), or over the network with NFS.
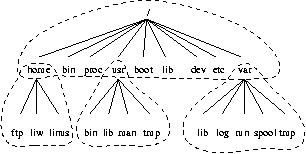
The roles of the different parts of the directory tree are described below.
The root filesystem is specific for each machine (it is generally stored on a local disk, although it could be a ramdisk or network drive as well) and contains the files that are necessary for booting the system up, and to bring it up to such a state that the other filesystems may be mounted. The contents of the root filesystem will therefore be sufficient for the single user state. It will also contain tools for fixing a broken system, and for recovering lost files from backups.
The /usr filesystem contains all commands, libraries, manual pages, and other unchanging files needed during normal operation. No files in /usr should be specific for any given machine, nor should they be modified during normal use. This allows the files to be shared over the network, which can be cost-effective since it saves disk space (there can easily be hundreds of megabytes, increasingly multiple gigabytes in /usr). It can make administration easier (only the master /usr needs to be changed when updating an application, not each machine separately) to have /usr network mounted. Even if the filesystem is on a local disk, it could be mounted read-only, to lessen the chance of filesystem corruption during a crash.
The /var filesystem contains files that change, such as spool directories (for mail, news, printers, etc), log files, formatted manual pages, and temporary files. Traditionally everything in /var has been somewhere below /usr , but that made it impossible to mount /usr read-only.
The /home filesystem contains the users' home directories, i.e., all the real data on the system. Separating home directories to their own directory tree or filesystem makes backups easier; the other parts often do not have to be backed up, or at least not as often as they seldom change. A big /home might have to be broken across several filesystems, which requires adding an extra naming level below /home, for example /home/students and /home/staff.
Although the different parts have been called filesystems above, there is no requirement that they actually be on separate filesystems. They could easily be kept in a single one if the system is a small single-user system and the user wants to keep things simple. The directory tree might also be divided into filesystems differently, depending on how large the disks are, and how space is allocated for various purposes. The important part, though, is that all the standard names work; even if, say, /var and /usr are actually on the same partition, the names /usr/lib/libc.a and /var/log/messages must work, for example by moving files below /var into /usr/var, and making /var a symlink to /usr/var.
The Unix filesystem structure groups files according to purpose, i.e., all commands are in one place, all data files in another, documentation in a third, and so on. An alternative would be to group files files according to the program they belong to, i.e., all Emacs files would be in one directory, all TeX in another, and so on. The problem with the latter approach is that it makes it difficult to share files (the program directory often contains both static and sharable and changing and non-sharable files), and sometimes to even find the files (e.g., manual pages in a huge number of places, and making the manual page programs find all of them is a maintenance nightmare).
3.2. The root filesystem
The root filesystem should generally be small, since it contains very critical files and a small, infrequently modified filesystem has a better chance of not getting corrupted. A corrupted root filesystem will generally mean that the system becomes unbootable except with special measures (e.g., from a floppy), so you don't want to risk it.
The root directory generally doesn't contain any files, except perhaps on older systems where the standard boot image for the system, usually called /vmlinuz was kept there. (Most distributions have moved those files the the /boot directory. Otherwise, all files are kept in subdirectories under the root filesystem:
- /bin
Commands needed during bootup that might be used by normal users (probably after bootup).
- /sbin
Like /bin, but the commands are not intended for normal users, although they may use them if necessary and allowed. /sbin is not usually in the default path of normal users, but will be in root's default path.
- /etc
Configuration files specific to the machine.
- /root
The home directory for user root. This is usually not accessible to other users on the system
- /lib
Shared libraries needed by the programs on the root filesystem.
- /lib/modules
Loadable kernel modules, especially those that are needed to boot the system when recovering from disasters (e.g., network and filesystem drivers).
- /dev
Device files. These are special files that help the user interface with the various devices on the system.
- /tmp
Temporary files. As the name suggests, programs running often store temporary files in here.
- /boot
Files used by the bootstrap loader, e.g., LILO or GRUB. Kernel images are often kept here instead of in the root directory. If there are many kernel images, the directory can easily grow rather big, and it might be better to keep it in a separate filesystem. Another reason would be to make sure the kernel images are within the first 1024 cylinders of an IDE disk. This 1024 cylinder limit is no longer true in most cases. With modern BIOSes and later versions of LILO (the LInux LOader) the 1024 cylinder limit can be passed with logical block addressing (LBA). See the lilo manual page for more details.
- /mnt
Mount point for temporary mounts by the system administrator. Programs aren't supposed to mount on /mnt automatically. /mnt might be divided into subdirectories (e.g., /mnt/dosa might be the floppy drive using an MS-DOS filesystem, and /mnt/exta might be the same with an ext2 filesystem).
- /proc, /usr, /var, /home
Mount points for the other filesystems. Although /proc does not reside on any disk in reality it is still mentioned here. See the section about /proc later in the chapter.
3.3. The /etc directory
The /etc maintains a lot of files. Some of them are described below. For others, you should determine which program they belong to and read the manual page for that program. Many networking configuration files are in /etc as well, and are described in the Networking Administrators' Guide.
- /etc/rc or /etc/rc.d or /etc/rc?.d
Scripts or directories of scripts to run at startup or when changing the run level. See Section 2.3.1 for further information.
- /etc/passwd
The user database, with fields giving the username, real name, home directory, and other information about each user. The format is documented in the passwd manual page.
- /etc/shadow
/etc/shadow is an encrypted file the holds user passwords.
- /etc/fdprm
Floppy disk parameter table. Describes what different floppy disk formats look like. Used by setfdprm . See the setfdprm manual page for more information.
- /etc/fstab
Lists the filesystems mounted automatically at startup by the mount -a command (in /etc/rc or equivalent startup file). Under Linux, also contains information about swap areas used automatically by swapon -a . See Section 5.10.7 and the mount manual page for more information. Also fstab usually has its own manual page in section 5.
- /etc/group
Similar to /etc/passwd, but describes groups instead of users. See the group manual page in section 5 for more information.
- /etc/inittab
Configuration file for init.
- /etc/issue
Output by getty before the login prompt. Usually contains a short description or welcoming message to the system. The contents are up to the system administrator.
- /etc/magic
The configuration file for file. Contains the descriptions of various file formats based on which file guesses the type of the file. See the magic and file manual pages for more information.
- /etc/motd
The message of the day, automatically output after a successful login. Contents are up to the system administrator. Often used for getting information to every user, such as warnings about planned downtimes.
- /etc/mtab
List of currently mounted filesystems. Initially set up by the bootup scripts, and updated automatically by the mount command. Used when a list of mounted filesystems is needed, e.g., by the df command.
- /etc/login.defs
Configuration file for the login command. The login.defs file usually has a manual page in section 5.
- /etc/printcap
Like /etc/termcap /etc/printcap , but intended for printers. However it uses different syntax. The printcap has a manual page in section 5.
- /etc/profile, /etc/bash.rc, /etc/csh.cshrc
Files executed at login or startup time by the Bourne, BASH , or C shells. These allow the system administrator to set global defaults for all users. Users can also create individual copies of these in their home directory to personalize their environment. See the manual pages for the respective shells.
- /etc/securetty
Identifies secure terminals, i.e., the terminals from which root is allowed to log in. Typically only the virtual consoles are listed, so that it becomes impossible (or at least harder) to gain superuser privileges by breaking into a system over a modem or a network. Do not allow root logins over a network. Prefer to log in as an unprivileged user and use su or sudo to gain root privileges.
- /etc/shells
Lists trusted shells. The chsh command allows users to change their login shell only to shells listed in this file. ftpd, is the server process that provides FTP services for a machine, will check that the user's shell is listed in /etc/shells and will not let people log in unless the shell is listed there.
- /etc/termcap
The terminal capability database. Describes by what ``escape sequences'' various terminals can be controlled. Programs are written so that instead of directly outputting an escape sequence that only works on a particular brand of terminal, they look up the correct sequence to do whatever it is they want to do in /etc/termcap. As a result most programs work with most kinds of terminals. See the termcap, curs_termcap, and terminfo manual pages for more information.
3.4. The /dev directory
The /dev directory contains the special device files for all the devices. The device files are created during installation, and later with the /dev/MAKEDEV script. The /dev/MAKEDEV.local is a script written by the system administrator that creates local-only device files or links (i.e. those that are not part of the standard MAKEDEV, such as device files for some non-standard device driver).
This list which follows is by no means exhaustive or as detailed as it could be. Many of these device files will need support compiled into your kernel for the hardware. Read the kernel documentation to find details of any particular device.
If you think there are other devices which should be included here but aren't then let me know. I will try to include them in the next revision.
- /dev/dsp
Digital Signal Processor. Basically this forms the interface between software which produces sound and your soundcard. It is a character device on major node 14 and minor 3.
- /dev/fd0
The first floppy drive. If you are lucky enough to have several drives then they will be numbered sequentially. It is a character device on major node 2 and minor 0.
- /dev/fb0
The first framebuffer device. A framebuffer is an abstraction layer between software and graphics hardware. This means that applications do not need to know about what kind of hardware you have but merely how to communicate with the framebuffer driver's API (Application Programming Interface) which is well defined and standardized. The framebuffer is a character device and is on major node 29 and minor 0.
- /dev/hda
/dev/hda is the master IDE drive on the primary IDE controller. /dev/hdb the slave drive on the primary controller. /dev/hdc , and /dev/hdd are the master and slave devices on the secondary controller respectively. Each disk is divided into partitions. Partitions 1-4 are primary partitions and partitions 5 and above are logical partitions inside extended partitions. Therefore the device file which references each partition is made up of several parts. For example /dev/hdc9 references partition 9 (a logical partition inside an extended partition type) on the master IDE drive on the secondary IDE controller. The major and minor node numbers are somewhat complex. For the first IDE controller all partitions are block devices on major node 3. The master drive hda is at minor 0 and the slave drive hdb is at minor 64. For each partition inside the drive add the partition number to the minor minor node number for the drive. For example /dev/hdb5 is major 3, minor 69 (64 + 5 = 69). Drives on the secondary interface are handled the same way, but with major node 22.
- /dev/ht0
The first IDE tape drive. Subsequent drives are numbered ht1 etc. They are character devices on major node 37 and start at minor node 0 for ht0 1 for ht1 etc.
- /dev/js0
The first analogue joystick. Subsequent joysticks are numbered js1, js2 etc. Digital joysticks are called djs0, djs1 and so on. They are character devices on major node 15. The analogue joysticks start at minor node 0 and go up to 127 (more than enough for even the most fanatic gamer). Digital joysticks start at minor node 128.
- /dev/lp0
The first parallel printer device. Subsequent printers are numbered lp1, lp2 etc. They are character devices on major mode 6 and minor nodes starting at 0 and numbered sequentially.
- /dev/loop0
The first loopback device. Loopback devices are used for mounting filesystems which are not located on other block devices such as disks. For example if you wish to mount an iso9660 CD ROM image without burning it to CD then you need to use a loopback device to do so. This is usually transparent to the user and is handled by the mount command. Refer to the manual pages for mount and losetup. The loopback devices are block devices on major node 7 and with minor nodes starting at 0 and numbered sequentially.
- /dev/md0
First metadisk group. Metadisks are related to RAID (Redundant Array of Independent Disks) devices. Please refer to the most current RAID HOWTO at the LDP for more details. This can be found at http://www.tldp.org/HOWTO/Software-RAID-HOWTO.html. Metadisk devices are block devices on major node 9 with minor nodes starting at 0 and numbered sequentially.
- /dev/mixer
This is part of the OSS (Open Sound System) driver. Refer to the OSS documentation at http://www.opensound.com for more details. It is a character device on major node 14, minor node 0.
- /dev/null
The bit bucket. A black hole where you can send data for it never to be seen again. Anything sent to /dev/null will disappear. This can be useful if, for example, you wish to run a command but not have any feedback appear on the terminal. It is a character device on major node 1 and minor node 3.
- /dev/psaux
The PS/2 mouse port. This is a character device on major node 10, minor node 1.
- /dev/pda
Parallel port IDE disks. These are named similarly to disks on the internal IDE controllers (/dev/hd*). They are block devices on major node 45. Minor nodes need slightly more explanation here. The first device is /dev/pda and it is on minor node 0. Partitions on this device are found by adding the partition number to the minor number for the device. Each device is limited to 15 partitions each rather than 63 (the limit for internal IDE disks). /dev/pdb minor nodes start at 16, /dev/pdc at 32 and /dev/pdd at 48. So for example the minor node number for /dev/pdc6 would be 38 (32 + 6 = 38). This scheme limits you to 4 parallel disks of 15 partitions each.
- /dev/pcd0
Parallel port CD ROM drives. These are numbered from 0 onwards. All are block devices on major node 46. /dev/pcd0 is on minor node 0 with subsequent drives being on minor nodes 1, 2, 3 etc.
- /dev/pt0
Parallel port tape devices. Tapes do not have partitions so these are just numbered sequentially. They are character devices on major node 96. The minor node numbers start from 0 for /dev/pt0, 1 for /dev/pt1, and so on.
- /dev/parport0
The raw parallel ports. Most devices which are attached to parallel ports have their own drivers. This is a device to access the port directly. It is a character device on major node 99 with minor node 0. Subsequent devices after the first are numbered sequentially incrementing the minor node.
- /dev/random or /dev/urandom
These are kernel random number generators. /dev/random is a non-deterministic generator which means that the value of the next number cannot be guessed from the preceding ones. It uses the entropy of the system hardware to generate numbers. When it has no more entropy to use then it must wait until it has collected more before it will allow any more numbers to be read from it. /dev/urandom works similarly. Initially it also uses the entropy of the system hardware, but when there is no more entropy to use it will continue to return numbers using a pseudo random number generating formula. This is considered to be less secure for vital purposes such as cryptographic key pair generation. If security is your overriding concern then use /dev/random, if speed is more important then /dev/urandom works fine. They are character devices on major node 1 with minor nodes 8 for /dev/random and 9 for /dev/urandom.
- /dev/sda
The first SCSI drive on the first SCSI bus. The following drives are named similar to IDE drives. /dev/sdb is the second SCSI drive, /dev/sdc is the third SCSI drive, and so forth.
- /dev/ttyS0
The first serial port. Many times this it the port used to connect an external modem to your system.
- /dev/zero
This is a simple way of getting many 0s. Every time you read from this device it will return 0. This can be useful sometimes, for example when you want a file of fixed length but don't really care what it contains. It is a character device on major node 1 and minor node 5.
3.5. The /usr filesystem.
The /usr filesystem is often large, since all programs are installed there. All files in /usr usually come from a Linux distribution; locally installed programs and other stuff goes below /usr/local. This makes it possible to update the system from a new version of the distribution, or even a completely new distribution, without having to install all programs again. Some of the subdirectories of /usr are listed below (some of the less important directories have been dropped; see the FSSTND for more information).
- /usr/X11R6.
The X Window System, all files. To simplify the development and installation of X, the X files have not been integrated into the rest of the system. There is a directory tree below /usr/X11R6 similar to that below /usr itself.
- /usr/bin.
Almost all user commands. Some commands are in /bin or in /usr/local/bin.
- /usr/sbin
System administration commands that are not needed on the root filesystem, e.g., most server programs.
- /usr/share/man, /usr/share/info, /usr/share/doc
Manual pages, GNU Info documents, and miscellaneous other documentation files, respectively.
- /usr/include
Header files for the C programming language. This should actually be below /usr/lib for consistency, but the tradition is overwhelmingly in support for this name.
- /usr/lib
Unchanging data files for programs and subsystems, including some site-wide configuration files. The name lib comes from library; originally libraries of programming subroutines were stored in /usr/lib.
- /usr/local
The place for locally installed software and other files. Distributions may not install anything in here. It is reserved solely for the use of the local administrator. This way he can be absolutely certain that no updates or upgrades to his distribution will overwrite any extra software he has installed locally.
3.6. The /var filesystem
The /var contains data that is changed when the system is running normally. It is specific for each system, i.e., not shared over the network with other computers.
- /var/cache/man
A cache for man pages that are formatted on demand. The source for manual pages is usually stored in /usr/share/man/man?/ (where ? is the manual section. See the manual page for man in section 7); some manual pages might come with a pre-formatted version, which might be stored in /usr/share/man/cat* . Other manual pages need to be formatted when they are first viewed; the formatted version is then stored in /var/cache/man so that the next person to view the same page won't have to wait for it to be formatted.
- /var/games
Any variable data belonging to games in /usr should be placed here. This is in case /usr is mounted read only.
- /var/lib
Files that change while the system is running normally.
- /var/local
Variable data for programs that are installed in /usr/local (i.e., programs that have been installed by the system administrator). Note that even locally installed programs should use the other /var directories if they are appropriate, e.g., /var/lock.
- /var/lock
Lock files. Many programs follow a convention to create a lock file in /var/lock to indicate that they are using a particular device or file. Other programs will notice the lock file and won't attempt to use the device or file.
- /var/log
Log files from various programs, especially login(/var/log/wtmp, which logs all logins and logouts into the system) and syslog(/var/log/messages, where all kernel and system program message are usually stored). Files in /var/log can often grow indefinitely, and may require cleaning at regular intervals.
- /var/mail
This is the FHS approved location for user mailbox files. Depending on how far your distribution has gone towards FHS compliance, these files may still be held in /var/spool/mail.
- /var/run
Files that contain information about the system that is valid until the system is next booted. For example, /var/run/utmp contains information about people currently logged in.
- /var/spool
Directories for news, printer queues, and other queued work. Each different spool has its own subdirectory below /var/spool, e.g., the news spool is in /var/spool/news . Note that some installations which are not fully compliant with the latest version of the FHS may have user mailboxes under /var/spool/mail.
- /var/tmp
Temporary files that are large or that need to exist for a longer time than what is allowed for /tmp . (Although the system administrator might not allow very old files in /var/tmp either.)
3.7. The /proc filesystem
The /proc filesystem contains a illusionary filesystem. It does not exist on a disk. Instead, the kernel creates it in memory. It is used to provide information about the system (originally about processes, hence the name). Some of the more important files and directories are explained below. The /proc filesystem is described in more detail in the proc manual page.
- /proc/1
A directory with information about process number 1. Each process has a directory below /proc with the name being its process identification number.
- /proc/cpuinfo
Information about the processor, such as its type, make, model, and performance.
- /proc/devices
List of device drivers configured into the currently running kernel.
- /proc/dma
Shows which DMA channels are being used at the moment.
- /proc/filesystems
Filesystems configured into the kernel.
- /proc/interrupts
Shows which interrupts are in use, and how many of each there have been.
- /proc/ioports
Which I/O ports are in use at the moment.
- /proc/kcore
An image of the physical memory of the system. This is exactly the same size as your physical memory, but does not really take up that much memory; it is generated on the fly as programs access it. (Remember: unless you copy it elsewhere, nothing under /proc takes up any disk space at all.)
- /proc/kmsg
Messages output by the kernel. These are also routed to syslog.
- /proc/ksyms
Symbol table for the kernel.
- /proc/loadavg
The `load average' of the system; three meaningless indicators of how much work the system has to do at the moment.
- /proc/meminfo
Information about memory usage, both physical and swap.
- /proc/modules
Which kernel modules are loaded at the moment.
- /proc/net
Status information about network protocols.
- /proc/self
A symbolic link to the process directory of the program that is looking at /proc. When two processes look at /proc, they get different links. This is mainly a convenience to make it easier for programs to get at their process directory.
- /proc/stat
Various statistics about the system, such as the number of page faults since the system was booted.
- /proc/uptime
The time the system has been up.
- /proc/version
The kernel version.
Note that while the above files tend to be easily readable text files, they can sometimes be formatted in a way that is not easily digestible. There are many commands that do little more than read the above files and format them for easier understanding. For example, the freeprogram reads /proc/meminfo converts the amounts given in bytes to kilobytes (and adds a little more information, as well).
Chapter 4. Hardware, Devices, and Tools
"Knowledge speaks, but wisdom listens." Jimi Hendrix
This chapter gives an overview of what a device file is, and how to create one. The canonical list of device files is /usr/src/linux/Documentation/devices.txt if you have the Linux kernel source code installed on your system. The devices listed here are correct as of kernel version 2.6.8.
4.1. Hardware Utilities
4.1.1. The MAKEDEV Script
Most device files will already be created and will be there ready to use after you install your Linux system. If by some chance you need to create one which is not provided then you should first try to use the MAKEDEV script. This script is usually located in /dev/MAKEDEV but might also have a copy (or a symbolic link) in /sbin/MAKEDEV. If it turns out not to be in your path then you will need to specify the path to it explicitly.
In general the command is used as:
# /dev/MAKEDEV -v ttyS0 create ttyS0 c 4 64 root:dialout 0660 |
ttyS0 is a serial port. The major and minor node numbers are numbers understood by the kernel. The kernel refers to hardware devices as numbers, this would be very difficult for us to remember, so we use filenames. Access permissions of 0660 means read and write permission for the owner (root in this case) and read and write permission for members of the group (dialout in this case) with no access for anyone else.
4.1.2. The mknod command
MAKEDEV is the preferred way of creating device files which are not present. However sometimes the MAKEDEV script will not know about the device file you wish to create. This is where the mknod command comes in. In order to use mknod you need to know the major and minor node numbers for the device you wish to create. The devices.txt file in the kernel source documentation is the canonical source of this information.
To take an example, let us suppose that our version of the MAKEDEV script does not know how to create the /dev/ttyS0 device file. We need to use mknod to create it. We know from looking at the devices.txt that it should be a character device with major number 4 and minor number 64. So we now know all we need to create the file.
# mknod /dev/ttyS0 c 4 64 # chown root.dialout /dev/ttyS0 # chmod 0644 /dev/ttyS0 # ls -l /dev/ttyS0 crw-rw---- 1 root dialout 4, 64 Oct 23 18:23 /dev/ttyS0 |
4.1.8. More Hardware Resources
More information on what hardware resources the kernel is using can be found in the /proc directory. Refer to Section 3.7 in chapter 3.
Chapter 5. Using Disks and Other Storage Media
"On a clear disk you can seek forever. "
When you install or upgrade your system, you need to do a fair amount of work on your disks. You have to make filesystems on your disks so that files can be stored on them and reserve space for the different parts of your system.
This chapter explains all these initial activities. Usually, once you get your system set up, you won't have to go through the work again, except for using floppies. You'll need to come back to this chapter if you add a new disk or want to fine-tune your disk usage.
The basic tasks in administering disks are:
Format your disk. This does various things to prepare it for use, such as checking for bad sectors. (Formatting is nowadays not necessary for most hard disks.)
Partition a hard disk, if you want to use it for several activities that aren't supposed to interfere with one another. One reason for partitioning is to store different operating systems on the same disk. Another reason is to keep user files separate from system files, which simplifies back-ups and helps protect the system files from corruption.
Make a filesystem (of a suitable type) on each disk or partition. The disk means nothing to Linux until you make a filesystem; then files can be created and accessed on it.
Mount different filesystems to form a single tree structure, either automatically, or manually as needed. (Manually mounted filesystems usually need to be unmounted manually as well.)
Chapter 6 contains information about virtual memory and disk caching, of which you also need to be aware when using disks.
5.1. Two kinds of devices
UNIX, and therefore Linux, recognizes two different kinds of device: random-access block devices (such as disks), and character devices (such as tapes and serial lines) , some of which may be serial, and some random-access. Each supported device is represented in the filesystem as a device file. When you read or write a device file, the data comes from or goes to the device it represents. This way no special programs (and no special application programming methodology, such as catching interrupts or polling a serial port) are necessary to access devices; for example, to send a file to the printer, one could just say
$ cat filename > /dev/lp1 $ |
Since devices show up as files in the filesystem (in the /dev directory), it is easy to see just what device files exist, using ls or another suitable command. In the output of ls -l, the first column contains the type of the file and its permissions. For example, inspecting a serial device might give
$ ls -l /dev/ttyS0 crw-rw-r-- 1 root dialout 4, 64 Aug 19 18:56 /dev/ttyS0 $ |
Note that usually all device files exist even though the device itself might be not be installed. So just because you have a file /dev/sda, it doesn't mean that you really do have an SCSI hard disk. Having all the device files makes the installation programs simpler, and makes it easier to add new hardware (there is no need to find out the correct parameters for and create the device files for the new device).
5.2. Hard disks
This subsection introduces terminology related to hard disks. If you already know the terms and concepts, you can skip this subsection.
See Figure 5-1 for a schematic picture of the important parts in a hard disk. A hard disk consists of one or more circular aluminum platters\ , of which either or both surfaces are coated with a magnetic substance used for recording the data. For each surface, there is a read-write head that examines or alters the recorded data. The platters rotate on a common axis; typical rotation speed is 5400 or 7200 rotations per minute, although high-performance hard disks have higher speeds and older disks may have lower speeds. The heads move along the radius of the platters; this movement combined with the rotation of the platters allows the head to access all parts of the surfaces.
The processor (CPU) and the actual disk communicate through a disk controller . This relieves the rest of the computer from knowing how to use the drive, since the controllers for different types of disks can be made to use the same interface towards the rest of the computer. Therefore, the computer can say just ``hey disk, give me what I want'', instead of a long and complex series of electric signals to move the head to the proper location and waiting for the correct position to come under the head and doing all the other unpleasant stuff necessary. (In reality, the interface to the controller is still complex, but much less so than it would otherwise be.) The controller may also do other things, such as caching, or automatic bad sector replacement.
The above is usually all one needs to understand about the hardware. There are also other things, such as the motor that rotates the platters and moves the heads, and the electronics that control the operation of the mechanical parts, but they are mostly not relevant for understanding the working principles of a hard disk.
The surfaces are usually divided into concentric rings, called tracks, and these in turn are divided into sectors. This division is used to specify locations on the hard disk and to allocate disk space to files. To find a given place on the hard disk, one might say ``surface 3, track 5, sector 7''. Usually the number of sectors is the same for all tracks, but some hard disks put more sectors in outer tracks (all sectors are of the same physical size, so more of them fit in the longer outer tracks). Typically, a sector will hold 512 bytes of data. The disk itself can't handle smaller amounts of data than one sector.
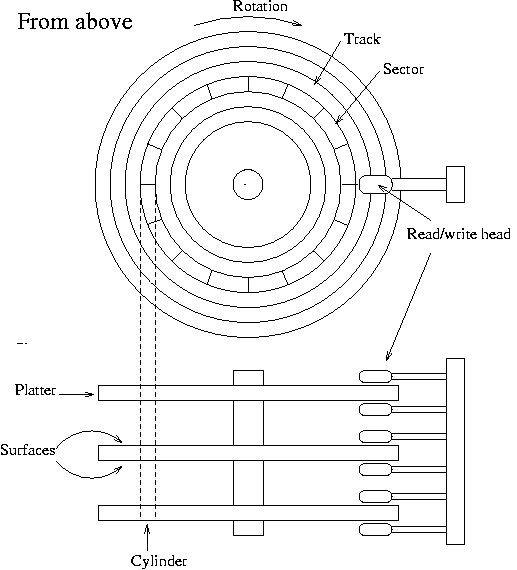
Each surface is divided into tracks (and sectors) in the same way. This means that when the head for one surface is on a track, the heads for the other surfaces are also on the corresponding tracks. All the corresponding tracks taken together are called a cylinder. It takes time to move the heads from one track (cylinder) to another, so by placing the data that is often accessed together (say, a file) so that it is within one cylinder, it is not necessary to move the heads to read all of it. This improves performance. It is not always possible to place files like this; files that are stored in several places on the disk are called fragmented.
The number of surfaces (or heads, which is the same thing), cylinders, and sectors vary a lot; the specification of the number of each is called the geometry of a hard disk. The geometry is usually stored in a special, battery-powered memory location called the CMOS RAM , from where the operating system can fetch it during bootup or driver initialization.
Unfortunately, the BIOS has a design limitation, which makes it impossible to specify a track number that is larger than 1024 in the CMOS RAM, which is too little for a large hard disk. To overcome this, the hard disk controller lies about the geometry, and translates the addresses given by the computer into something that fits reality. For example, a hard disk might have 8 heads, 2048 tracks, and 35 sectors per track. Its controller could lie to the computer and claim that it has 16 heads, 1024 tracks, and 35 sectors per track, thus not exceeding the limit on tracks, and translates the address that the computer gives it by halving the head number, and doubling the track number. The mathematics can be more complicated in reality, because the numbers are not as nice as here (but again, the details are not relevant for understanding the principle). This translation distorts the operating system's view of how the disk is organized, thus making it impractical to use the all-data-on-one-cylinder trick to boost performance.
The translation is only a problem for IDE disks. SCSI disks use a sequential sector number (i.e., the controller translates a sequential sector number to a head, cylinder, and sector triplet), and a completely different method for the CPU to talk with the controller, so they are insulated from the problem. Note, however, that the computer might not know the real geometry of an SCSI disk either.
Since Linux often will not know the real geometry of a disk, its filesystems don't even try to keep files within a single cylinder. Instead, it tries to assign sequentially numbered sectors to files, which almost always gives similar performance. The issue is further complicated by on-controller caches, and automatic prefetches done by the controller.
Each hard disk is represented by a separate device file. There can (usually) be only two or four IDE hard disks. These are known as /dev/hda, /dev/hdb, /dev/hdc, and /dev/hdd, respectively. SCSI hard disks are known as /dev/sda, /dev/sdb, and so on. Similar naming conventions exist for other hard disk types; see Chapter 4 for more information. Note that the device files for the hard disks give access to the entire disk, with no regard to partitions (which will be discussed below), and it's easy to mess up the partitions or the data in them if you aren't careful. The disks' device files are usually used only to get access to the master boot record (which will also be discussed below).
5.3. Storage Area Networks - Draft
A SAN is a dedicated storage network that provides block level access to LUNs. A LUN, or logical unit number, is a virtual disk provided by the SAN. The system administrator the same access and rights to the LUN as if it were a disk directly attached to it. The administrator can partition, and format the disk in any means he or she chooses.
Two networking protocols commonly used in a SAN are fibre channel and iSCSI . A fibre channel network is very fast and is not burdened by the other network traffic in a company's LAN. However, it's very expensive. Fibre channel cards cost around $1000.00 USD each. They also require special fibre channel switches.
iSCSI is a newer technology that sends SCSI commands over a TCP/IP network. While this method may not be as fast as a Fibre Channel network, it does save money by using less expensive network hardware.
More To Be Added
5.4. Network Attached Storage - Draft
A NAS uses your companies existing Ethernet network to allow access to shared disks. This is filesystem level access. The system administrator does not have the ability to partition or format the disks since they are potentially shared by multiple computers. This technology is commonly used to provide multiple workstations access to the same data.
Similar to a SAN, a NAS need to make use of a protocol to allow access to it's disks. With a NAS this is either CIFS/Samba , or NFS.
Traditionally CIFS was used with Microsoft Windows networks, and NFS was used with UNIX & Linux networks. However, with Samba, Linux machines can also make use of CIFS shares.
Does this mean that your Windows 2003 server or your Linux box are NAS servers because they provide access to shared drives over your network? Yes, they are. You could also purchase a NAS device from a number of manufacturers. These devices are specifically designed to provide high speed access to data.
More To Be Added
5.5. Floppies
A floppy disk consists of a flexible membrane covered on one or both sides with similar magnetic substance as a hard disk. The floppy disk itself doesn't have a read-write head, that is included in the drive. A floppy corresponds to one platter in a hard disk, but is removable and one drive can be used to access different floppies, and the same floppy can be read by many drives, whereas the hard disk is one indivisible unit.
Like a hard disk, a floppy is divided into tracks and sectors (and the two corresponding tracks on either side of a floppy form a cylinder), but there are many fewer of them than on a hard disk.
A floppy drive can usually use several different types of disks; for example, a 3.5 inch drive can use both 720 KB and 1.44 MB disks. Since the drive has to operate a bit differently and the operating system must know how big the disk is, there are many device files for floppy drives, one per combination of drive and disk type. Therefore, /dev/fd0H1440 is the first floppy drive (fd0), which must be a 3.5 inch drive, using a 3.5 inch, high density disk (H) of size 1440 KB (1440), i.e., a normal 3.5 inch HD floppy.
The names for floppy drives are complex, however, and Linux therefore has a special floppy device type that automatically detects the type of the disk in the drive. It works by trying to read the first sector of a newly inserted floppy using different floppy types until it finds the correct one. This naturally requires that the floppy is formatted first. The automatic devices are called /dev/fd0, /dev/fd1, and so on.
The parameters the automatic device uses to access a disk can also be set using the program setfdprm . This can be useful if you need to use disks that do not follow any usual floppy sizes, e.g., if they have an unusual number of sectors, or if the autodetecting for some reason fails and the proper device file is missing.
Linux can handle many nonstandard floppy disk formats in addition to all the standard ones. Some of these require using special formatting programs. We'll skip these disk types for now, but in the mean time you can examine the /etc/fdprm file. It specifies the settings that setfdprm recognizes.
The operating system must know when a disk has been changed in a floppy drive, for example, in order to avoid using cached data from the previous disk. Unfortunately, the signal line that is used for this is sometimes broken, and worse, this won't always be noticeable when using the drive from within MS-DOS. If you are experiencing weird problems using floppies, this might be the reason. The only way to correct it is to repair the floppy drive.
5.6. CD-ROMs
A CD-ROM drive uses an optically read, plastic coated disk. The information is recorded on the surface of the disk in small `holes' aligned along a spiral from the center to the edge. The drive directs a laser beam along the spiral to read the disk. When the laser hits a hole, the laser is reflected in one way; when it hits smooth surface, it is reflected in another way. This makes it easy to code bits, and therefore information. The rest is easy, mere mechanics.
CD-ROM drives are slow compared to hard disks. Whereas a typical hard disk will have an average seek time less than 15 milliseconds, a fast CD-ROM drive can use tenths of a second for seeks. The actual data transfer rate is fairly high at hundreds of kilobytes per second. The slowness means that CD-ROM drives are not as pleasant to use as hard disks (some Linux distributions provide `live' filesystems on CD-ROMs, making it unnecessary to copy the files to the hard disk, making installation easier and saving a lot of hard disk space), although it is still possible. For installing new software, CD-ROMs are very good, since maximum speed is not essential during installation.
There are several ways to arrange data on a CD-ROM. The most popular one is specified by the international standard ISO 9660 . This standard specifies a very minimal filesystem, which is even more crude than the one MS-DOS uses. On the other hand, it is so minimal that every operating system should be able to map it to its native system.
For normal UNIX use, the ISO 9660 filesystem is not usable, so an extension to the standard has been developed, called the Rock Ridge extension. Rock Ridge allows longer filenames, symbolic links, and a lot of other goodies, making a CD-ROM look more or less like any contemporary UNIX filesystem. Even better, a Rock Ridge filesystem is still a valid ISO 9660 filesystem, making it usable by non-UNIX systems as well. Linux supports both ISO 9660 and the Rock Ridge extensions; the extensions are recognized and used automatically.
The filesystem is only half the battle, however. Most CD-ROMs contain data that requires a special program to access, and most of these programs do not run under Linux (except, possibly, under dosemu, the Linux MS-DOS emulator, or wine, the Windows emulator.
Ironically perhaps, wine actually stands for ``Wine Is Not an Emulator''. Wine, more strictly, is an API (Application Program Interface) replacement. Please see the wine documentation at http://www.winehq.com for more information.
There is also VMWare, a commercial product, which emulates an entire x86 machine in software. See the VMWare website, http://www.vmware.com for more information.
A CD-ROM drive is accessed via the corresponding device file. There are several ways to connect a CD-ROM drive to the computer: via SCSI, via a sound card, or via EIDE. The hardware hacking needed to do this is outside the scope of this book, but the type of connection decides the device file.
5.7. Tapes
A tape drive uses a tape, similar to cassettes used for music. A tape is serial in nature, which means that in order to get to any given part of it, you first have to go through all the parts in between. A disk can be accessed randomly, i.e., you can jump directly to any place on the disk. The serial access of tapes makes them slow.
On the other hand, tapes are relatively cheap to make, since they do not need to be fast. They can also easily be made quite long, and can therefore contain a large amount of data. This makes tapes very suitable for things like archiving and backups, which do not require large speeds, but benefit from low costs and large storage capacities.
5.8. Formatting
Formatting is the process of writing marks on the magnetic media that are used to mark tracks and sectors. Before a disk is formatted, its magnetic surface is a complete mess of magnetic signals. When it is formatted, some order is brought into the chaos by essentially drawing lines where the tracks go, and where they are divided into sectors. The actual details are not quite exactly like this, but that is irrelevant. What is important is that a disk cannot be used unless it has been formatted.
The terminology is a bit confusing here: in MS-DOS and MS Windows, the word formatting is used to cover also the process of creating a filesystem (which will be discussed below). There, the two processes are often combined, especially for floppies. When the distinction needs to be made, the real formatting is called low-level formatting, while making the filesystem is called high-level formatting . In UNIX circles, the two are called formatting and making a filesystem, so that's what is used in this book as well.
For IDE and some SCSI disks the formatting is actually done at the factory and doesn't need to be repeated; hence most people rarely need to worry about it. In fact, formatting a hard disk can cause it to work less well, for example because a disk might need to be formatted in some very special way to allow automatic bad sector replacement to work.
Disks that need to be or can be formatted often require a special program anyway, because the interface to the formatting logic inside the drive is different from drive to drive. The formatting program is often either on the controller BIOS, or is supplied as an MS-DOS program; neither of these can easily be used from within Linux.
During formatting one might encounter bad spots on the disk, called bad blocks or bad sectors. These are sometimes handled by the drive itself, but even then, if more of them develop, something needs to be done to avoid using those parts of the disk. The logic to do this is built into the filesystem; how to add the information into the filesystem is described below. Alternatively, one might create a small partition that covers just the bad part of the disk; this approach might be a good idea if the bad spot is very large, since filesystems can sometimes have trouble with very large bad areas.
Floppies are formatted with fdformat . The floppy device file to use is given as the parameter. For example, the following command would format a high density, 3.5 inch floppy in the first floppy drive:
$ fdformat /dev/fd0H1440 Double-sided, 80 tracks, 18 sec/track. Total capacity 1440 kB. Formatting ... done Verifying ... done $ |
$ setfdprm /dev/fd0 1440/1440 $ fdformat /dev/fd0 Double-sided, 80 tracks, 18 sec/track. Total capacity 1440 KB. Formatting ... done Verifying ... done $ |
fdformatalso validate the floppy, i.e., check it for bad blocks. It will try a bad block several times (you can usually hear this, the drive noise changes dramatically). If the floppy is only marginally bad (due to dirt on the read/write head, some errors are false signals), fdformat won't complain, but a real error will abort the validation process. The kernel will print log messages for each I/O error it finds; these will go to the console or, if syslog is being used, to the file /var/log/messages. fdformat itself won't tell where the error is (one usually doesn't care, floppies are cheap enough that a bad one is automatically thrown away).
$ fdformat /dev/fd0H1440 Double-sided, 80 tracks, 18 sec/track. Total capacity 1440 KB. Formatting ... done Verifying ... read: Unknown error $ |
$ badblocks /dev/fd0H1440 1440 718 719 $ |
Many modern disks automatically notice bad blocks, and attempt to fix them by using a special, reserved good block instead. This is invisible to the operating system. This feature should be documented in the disk's manual, if you're curious if it is happening. Even such disks can fail, if the number of bad blocks grows too large, although chances are that by then the disk will be so rotten as to be unusable.
5.9. Partitions
A hard disk can be divided into several partitions. Each partition functions as if it were a separate hard disk. The idea is that if you have one hard disk, and want to have, say, two operating systems on it, you can divide the disk into two partitions. Each operating system uses its partition as it wishes and doesn't touch the other ones. This way the two operating systems can co-exist peacefully on the same hard disk. Without partitions one would have to buy a hard disk for each operating system.
Floppies are not usually partitioned. There is no technical reason against this, but since they're so small, partitions would be useful only very rarely. CD-ROMs are usually also not partitioned, since it's easier to use them as one big disk, and there is seldom a need to have several operating systems on one.
5.9.1. The MBR, boot sectors and partition table
The information about how a hard disk has been partitioned is stored in its first sector (that is, the first sector of the first track on the first disk surface). The first sector is the master boot record (MBR) of the disk; this is the sector that the BIOS reads in and starts when the machine is first booted. The master boot record contains a small program that reads the partition table, checks which partition is active (that is, marked bootable), and reads the first sector of that partition, the partition's boot sector (the MBR is also a boot sector, but it has a special status and therefore a special name). This boot sector contains another small program that reads the first part of the operating system stored on that partition (assuming it is bootable), and then starts it.
The partitioning scheme is not built into the hardware, or even into the BIOS. It is only a convention that many operating systems follow. Not all operating systems do follow it, but they are the exceptions. Some operating systems support partitions, but they occupy one partition on the hard disk, and use their internal partitioning method within that partition. The latter type exists peacefully with other operating systems (including Linux), and does not require any special measures, but an operating system that doesn't support partitions cannot co-exist on the same disk with any other operating system.
As a safety precaution, it is a good idea to write down the partition table on a piece of paper, so that if it ever corrupts you don't have to lose all your files. (A bad partition table can be fixed with fdisk). The relevant information is given by the fdisk -l command:
$ fdisk -l /dev/hda Disk /dev/hda: 15 heads, 57 sectors, 790 cylinders Units = cylinders of 855 * 512 bytes Device Boot Begin Start End Blocks Id System /dev/hda1 1 1 24 10231+ 82 Linux swap /dev/hda2 25 25 48 10260 83 Linux native /dev/hda3 49 49 408 153900 83 Linux native /dev/hda4 409 409 790 163305 5 Extended /dev/hda5 409 409 744 143611+ 83 Linux native /dev/hda6 745 745 790 19636+ 83 Linux native $ |
5.9.2. Extended and logical partitions
The original partitioning scheme for PC hard disks allowed only four partitions. This quickly turned out to be too little in real life, partly because some people want more than four operating systems (Linux, MS-DOS, OS/2, Minix, FreeBSD, NetBSD, or Windows/NT, to name a few), but primarily because sometimes it is a good idea to have several partitions for one operating system. For example, swap space is usually best put in its own partition for Linux instead of in the main Linux partition for reasons of speed (see below).
To overcome this design problem, extended partitions were invented. This trick allows partitioning a primary partition into sub-partitions. The primary partition thus subdivided is the extended partition; the sub-partitions are logical partitions. They behave like primary partitions, but are created differently. There is no speed difference between them. By using an extended partition you can now have up to 15 partitions per disk.
The partition structure of a hard disk might look like that in Figure 5-2. The disk is divided into three primary partitions, the second of which is divided into two logical partitions. Part of the disk is not partitioned at all. The disk as a whole and each primary partition has a boot sector.
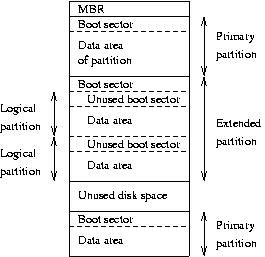
5.9.3. Partition types
The partition tables (the one in the MBR, and the ones for extended partitions) contain one byte per partition that identifies the type of that partition. This attempts to identify the operating system that uses the partition, or what it uses it for. The purpose is to make it possible to avoid having two operating systems accidentally using the same partition. However, in reality, operating systems do not really care about the partition type byte; e.g., Linux doesn't care at all what it is. Worse, some of them use it incorrectly; e.g., at least some versions of DR-DOS ignore the most significant bit of the byte, while others don't.
There is no standardization agency to specify what each byte value means, but as far as Linux is concerned, here is a list of partition types as per the fdisk program.
0 Empty 1c Hidden Win95 FA 70 DiskSecure Mult bb Boot Wizard hid 1 FAT12 1e Hidden Win95 FA 75 PC/IX be Solaris boot 2 XENIX root 24 NEC DOS 80 Old Minix c1 DRDOS/sec (FAT- 3 XENIX usr 39 Plan 9 81 Minix / old Lin c4 DRDOS/sec (FAT- 4 FAT16 <32M 3c PartitionMagic 82 Linux swap c6 DRDOS/sec (FAT- 5 Extended 40 Venix 80286 83 Linux c7 Syrinx 6 FAT16 41 PPC PReP Boot 84 OS/2 hidden C: da Non-FS data 7 HPFS/NTFS 42 SFS 85 Linux extended db CP/M / CTOS / . 8 AIX 4d QNX4.x 86 NTFS volume set de Dell Utility 9 AIX bootable 4e QNX4.x 2nd part 87 NTFS volume set df BootIt a OS/2 Boot Manag 4f QNX4.x 3rd part 8e Linux LVM e1 DOS access b Win95 FAT32 50 OnTrack DM 93 Amoeba e3 DOS R/O c Win95 FAT32 (LB 51 OnTrack DM6 Aux 94 Amoeba BBT e4 SpeedStor e Win95 FAT16 (LB 52 CP/M 9f BSD/OS eb BeOS fs f Win95 Ext'd (LB 53 OnTrack DM6 Aux a0 IBM Thinkpad hi ee EFI GPT 10 OPUS 54 OnTrackDM6 a5 FreeBSD ef EFI (FAT-12/16/ 11 Hidden FAT12 55 EZ-Drive a6 OpenBSD f0 Linux/PA-RISC b 12 Compaq diagnost 56 Golden Bow a7 NeXTSTEP f1 SpeedStor 14 Hidden FAT16 <3 5c Priam Edisk a8 Darwin UFS f4 SpeedStor 16 Hidden FAT16 61 SpeedStor a9 NetBSD f2 DOS secondary 17 Hidden HPFS/NTF 63 GNU HURD or Sys ab Darwin boot fd Linux raid auto 18 AST SmartSleep 64 Novell Netware b7 BSDI fs fe LANstep 1b Hidden Win95 FA 65 Novell Netware b8 BSDI swap ff BBT |
5.9.4. Partitioning a hard disk
There are many programs for creating and removing partitions. Most operating systems have their own, and it can be a good idea to use each operating system's own, just in case it does something unusual that the others can't. Many of the programs are called fdisk, including the Linux one, or variations thereof. Details on using the Linux fdisk given on its man page. The cfdisk command is similar to fdisk, but has a nicer (full screen) user interface.
When using IDE disks, the boot partition (the partition with the bootable kernel image files) must be completely within the first 1024 cylinders. This is because the disk is used via the BIOS during boot (before the system goes into protected mode), and BIOS can't handle more than 1024 cylinders. It is sometimes possible to use a boot partition that is only partly within the first 1024 cylinders. This works as long as all the files that are read with the BIOS are within the first 1024 cylinders. Since this is difficult to arrange, it is a very bad idea to do it; you never know when a kernel update or disk defragmentation will result in an unbootable system. Therefore, make sure your boot partition is completely within the first 1024 cylinders.
However, this may no longer be true with newer versions of LILO that support LBA (Logical Block Addressing). Consult the documentation for your distribution to see if it has a version of LILO where LBA is supported.
Some newer versions of the BIOS and IDE disks can, in fact, handle disks with more than 1024 cylinders. If you have such a system, you can forget about the problem; if you aren't quite sure of it, put it within the first 1024 cylinders.
Each partition should have an even number of sectors, since the Linux filesystems use a 1 kilobyte block size, i.e., two sectors. An odd number of sectors will result in the last sector being unused. This won't result in any problems, but it is ugly, and some versions of fdisk will warn about it.
Changing a partition's size usually requires first backing up everything you want to save from that partition (preferably the whole disk, just in case), deleting the partition, creating new partition, then restoring everything to the new partition. If the partition is growing, you may need to adjust the sizes (and backup and restore) of the adjoining partitions as well.
Since changing partition sizes is painful, it is preferable to get the partitions right the first time, or have an effective and easy to use backup system. If you're installing from a media that does not require much human intervention (say, from CD-ROM, as opposed to floppies), it is often easy to play with different configuration at first. Since you don't already have data to back up, it is not so painful to modify partition sizes several times.
There is a program for MS-DOS, called fips , which resizes an MS-DOS partition without requiring the backup and restore, but for other filesystems it is still necessary.
The fips program is included in most Linux distributions. The commercial partition manager ``Partition Magic'' also has a similar facility but with a nicer interface. Please do remember that partitioning is dangerous. Make sure you have a recent backup of any important data before you try changing partition sizes ``on the fly''. The program parted can resize other types of partitions as well as MS-DOS, but sometimes in a limited manner. Consult the parted documentation before using it, better safe than sorry.
5.9.5. Device files and partitions
Each partition and extended partition has its own device file. The naming convention for these files is that a partition's number is appended after the name of the whole disk, with the convention that 1-4 are primary partitions (regardless of how many primary partitions there are) and number greater than 5 are logical partitions (regardless of within which primary partition they reside). For example, /dev/hda1 is the first primary partition on the first IDE hard disk, and /dev/sdb7 is the third extended partition on the second SCSI hard disk.
5.10. Filesystems
5.10.1. What are filesystems?
A filesystem is the methods and data structures that an operating system uses to keep track of files on a disk or partition; that is, the way the files are organized on the disk. The word is also used to refer to a partition or disk that is used to store the files or the type of the filesystem. Thus, one might say ``I have two filesystems'' meaning one has two partitions on which one stores files, or that one is using the ``extended filesystem'', meaning the type of the filesystem.
The difference between a disk or partition and the filesystem it contains is important. A few programs (including, reasonably enough, programs that create filesystems) operate directly on the raw sectors of a disk or partition; if there is an existing file system there it will be destroyed or seriously corrupted. Most programs operate on a filesystem, and therefore won't work on a partition that doesn't contain one (or that contains one of the wrong type).
Before a partition or disk can be used as a filesystem, it needs to be initialized, and the bookkeeping data structures need to be written to the disk. This process is called making a filesystem.
Most UNIX filesystem types have a similar general structure, although the exact details vary quite a bit. The central concepts are superblock, inode , data block, directory block , and indirection block. The superblock contains information about the filesystem as a whole, such as its size (the exact information here depends on the filesystem). An inode contains all information about a file, except its name. The name is stored in the directory, together with the number of the inode. A directory entry consists of a filename and the number of the inode which represents the file. The inode contains the numbers of several data blocks, which are used to store the data in the file. There is space only for a few data block numbers in the inode, however, and if more are needed, more space for pointers to the data blocks is allocated dynamically. These dynamically allocated blocks are indirect blocks; the name indicates that in order to find the data block, one has to find its number in the indirect block first.
UNIX filesystems usually allow one to create a hole in a file (this is done with the lseek() system call; check the manual page), which means that the filesystem just pretends that at a particular place in the file there is just zero bytes, but no actual disk sectors are reserved for that place in the file (this means that the file will use a bit less disk space). This happens especially often for small binaries, Linux shared libraries, some databases, and a few other special cases. (Holes are implemented by storing a special value as the address of the data block in the indirect block or inode. This special address means that no data block is allocated for that part of the file, ergo, there is a hole in the file.)
5.10.2. Filesystems galore
Linux supports several types of filesystems. As of this writing the most important ones are:
- minix
The oldest, presumed to be the most reliable, but quite limited in features (some time stamps are missing, at most 30 character filenames) and restricted in capabilities (at most 64 MB per filesystem).
- xia
A modified version of the minix filesystem that lifts the limits on the filenames and filesystem sizes, but does not otherwise introduce new features. It is not very popular, but is reported to work very well.
- ext3
The ext3 filesystem has all the features of the ext2 filesystem. The difference is, journaling has been added. This improves performance and recovery time in case of a system crash. This has become more popular than ext2.
- ext2
The most featureful of the native Linux filesystems. It is designed to be easily upwards compatible, so that new versions of the filesystem code do not require re-making the existing filesystems.
- ext
An older version of ext2 that wasn't upwards compatible. It is hardly ever used in new installations any more, and most people have converted to ext2.
- reiserfs
A more robust filesystem. Journaling is used which makes data loss less likely. Journaling is a mechanism whereby a record is kept of transaction which are to be performed, or which have been performed. This allows the filesystem to reconstruct itself fairly easily after damage caused by, for example, improper shutdowns.
- jfs
JFS is a journaled filesystem designed by IBM to to work in high performance environments>
- xfs
XFS was originally designed by Silicon Graphics to work as a 64-bit journaled filesystem. XFS was also designed to maintain high performance with large files and filesystems.
In addition, support for several foreign filesystems exists, to make it easier to exchange files with other operating systems. These foreign filesystems work just like native ones, except that they may be lacking in some usual UNIX features, or have curious limitations, or other oddities.
- msdos
Compatibility with MS-DOS (and OS/2 and Windows NT) FAT filesystems.
- umsdos
Extends the msdos filesystem driver under Linux to get long filenames, owners, permissions, links, and device files. This allows a normal msdos filesystem to be used as if it were a Linux one, thus removing the need for a separate partition for Linux.
- vfat
This is an extension of the FAT filesystem known as FAT32. It supports larger disk sizes than FAT. Most MS Windows disks are vfat.
- iso9660
The standard CD-ROM filesystem; the popular Rock Ridge extension to the CD-ROM standard that allows longer file names is supported automatically.
- nfs
A networked filesystem that allows sharing a filesystem between many computers to allow easy access to the files from all of them.
- smbfs
A networks filesystem which allows sharing of a filesystem with an MS Windows computer. It is compatible with the Windows file sharing protocols.
- hpfs
The OS/2 filesystem.
- sysv
SystemV/386, Coherent, and Xenix filesystems.
- NTFS
The most advanced Microsoft journaled filesystem providing faster file access and stability over previous Microsoft filesystems.
The choice of filesystem to use depends on the situation. If compatibility or other reasons make one of the non-native filesystems necessary, then that one must be used. If one can choose freely, then it is probably wisest to use ext3, since it has all the features of ext2, and is a journaled filesystem. For more information on filesystems, see Section 5.10.6. You can also read the Filesystems HOWTO located at http://www.tldp.org/HOWTO/Filesystems-HOWTO.html
There is also the proc filesystem, usually accessible as the /proc directory, which is not really a filesystem at all, even though it looks like one. The proc filesystem makes it easy to access certain kernel data structures, such as the process list (hence the name). It makes these data structures look like a filesystem, and that filesystem can be manipulated with all the usual file tools. For example, to get a listing of all processes one might use the command
$ ls -l /proc total 0 dr-xr-xr-x 4 root root 0 Jan 31 20:37 1 dr-xr-xr-x 4 liw users 0 Jan 31 20:37 63 dr-xr-xr-x 4 liw users 0 Jan 31 20:37 94 dr-xr-xr-x 4 liw users 0 Jan 31 20:37 95 dr-xr-xr-x 4 root users 0 Jan 31 20:37 98 dr-xr-xr-x 4 liw users 0 Jan 31 20:37 99 -r--r--r-- 1 root root 0 Jan 31 20:37 devices -r--r--r-- 1 root root 0 Jan 31 20:37 dma -r--r--r-- 1 root root 0 Jan 31 20:37 filesystems -r--r--r-- 1 root root 0 Jan 31 20:37 interrupts -r-------- 1 root root 8654848 Jan 31 20:37 kcore -r--r--r-- 1 root root 0 Jan 31 11:50 kmsg -r--r--r-- 1 root root 0 Jan 31 20:37 ksyms -r--r--r-- 1 root root 0 Jan 31 11:51 loadavg -r--r--r-- 1 root root 0 Jan 31 20:37 meminfo -r--r--r-- 1 root root 0 Jan 31 20:37 modules dr-xr-xr-x 2 root root 0 Jan 31 20:37 net dr-xr-xr-x 4 root root 0 Jan 31 20:37 self -r--r--r-- 1 root root 0 Jan 31 20:37 stat -r--r--r-- 1 root root 0 Jan 31 20:37 uptime -r--r--r-- 1 root root 0 Jan 31 20:37 version $ |
Note that even though it is called a filesystem, no part of the proc filesystem touches any disk. It exists only in the kernel's imagination. Whenever anyone tries to look at any part of the proc filesystem, the kernel makes it look as if the part existed somewhere, even though it doesn't. So, even though there is a multi-megabyte /proc/kcore file, it doesn't take any disk space.
5.10.3. Which filesystem should be used?
There is usually little point in using many different filesystems. Currently, ext3 is the most popular filesystem, because it is a journaled filesystem. Currently it is probably the wisest choice. Reiserfs is another popular choice because it to is journaled. Depending on the overhead for bookkeeping structures, speed, (perceived) reliability, compatibility, and various other reasons, it may be advisable to use another file system. This needs to be decided on a case-by-case basis.
A filesystem that uses journaling is also called a journaled filesystem. A journaled filesystem maintains a log, or journal, of what has happened on a filesystem. In the event of a system crash, or if your 2 year old son hits the power button like mine loves to do, a journaled filesystem is designed to use the filesystem's logs to recreate unsaved and lost data. This makes data loss much less likely and will likely become a standard feature in Linux filesystems. However, do not get a false sense of security from this. Like everything else, errors can arise. Always make sure to back up your data in the event of an emergency.
See Section 5.10.6 for more details about the features of the different filesystem types.
5.10.4. Creating a filesystem
Filesystems are created, i.e., initialized, with the mkfs command. There is actually a separate program for each filesystem type. mkfs is just a front end that runs the appropriate program depending on the desired filesystem type. The type is selected with the -t fstype option.
The programs called by mkfs have slightly different command line interfaces. The common and most important options are summarized below; see the manual pages for more.
- -t fstype
Select the type of the filesystem.
- -c
Search for bad blocks and initialize the bad block list accordingly.
- -l filename
Read the initial bad block list from the name file.
There are also many programs written to add specific options when creating a specific filesystem. For example mkfs.ext3 adds a -b option to allow the administrator to specify what block size should be used. Be sure to find out if there is a specific program available for the filesystem type you want to use. For more information on determining what block size to use please see Section 5.10.5.
To create an ext2 filesystem on a floppy, one would give the following commands:
$ fdformat -n /dev/fd0H1440 Double-sided, 80 tracks, 18 sec/track. Total capacity 1440 KB. Formatting ... done $ badblocks /dev/fd0H1440 1440 $>$ bad-blocks $ mkfs.ext2 -l bad-blocks /dev/fd0H1440 mke2fs 0.5a, 5-Apr-94 for EXT2 FS 0.5, 94/03/10 360 inodes, 1440 blocks 72 blocks (5.00%) reserved for the super user First data block=1 Block size=1024 (log=0) Fragment size=1024 (log=0) 1 block group 8192 blocks per group, 8192 fragments per group 360 inodes per group Writing inode tables: done Writing superblocks and filesystem accounting information: done $ |
The -c option could have been used with mkfs instead of badblocks and a separate file. The example below does that.
$ mkfs.ext2 -c /dev/fd0H1440 mke2fs 0.5a, 5-Apr-94 for EXT2 FS 0.5, 94/03/10 360 inodes, 1440 blocks 72 blocks (5.00%) reserved for the super user First data block=1 Block size=1024 (log=0) Fragment size=1024 (log=0) 1 block group 8192 blocks per group, 8192 fragments per group 360 inodes per group Checking for bad blocks (read-only test): done Writing inode tables: done Writing superblocks and filesystem accounting information: done $ |
The process to prepare filesystems on hard disks or partitions is the same as for floppies, except that the formatting isn't needed.
5.10.5. Filesystem block size
The block size specifies size that the filesystem will use to read and write data. Larger block sizes will help improve disk I/O performance when using large files, such as databases. This happens because the disk can read or write data for a longer period of time before having to search for the next block.
On the downside, if you are going to have a lot of smaller files on that filesystem, like the /etc, there the potential for a lot of wasted disk space.
For example, if you set your block size to 4096, or 4K, and you create a file that is 256 bytes in size, it will still consume 4K of space on your harddrive. For one file that may seem trivial, but when your filesystem contains hundreds or thousands of files, this can add up.
Block size can also effect the maximum supported file size on some filesystems. This is because many modern filesystem are limited not by block size or file size, but by the number of blocks. Therefore you would be using a "block size * max # of blocks = max block size" formula.
5.10.6. Filesystem comparison
Table 5-1. Comparing Filesystem Features
| FS Name | Year Introduced | Original OS | Max File Size | Max FS Size | Journaling |
|---|---|---|---|---|---|
| FAT16 | 1983 | MSDOS V2 | 4GB | 16MB to 8GB | N |
| FAT32 | 1997 | Windows 95 | 4GB | 8GB to 2TB | N |
| HPFS | 1988 | OS/2 | 4GB | 2TB | N |
| NTFS | 1993 | Windows NT | 16EB | 16EB | Y |
| HFS+ | 1998 | Mac OS | 8EB | ? | N |
| UFS2 | 2002 | FreeBSD | 512GB to 32PB | 1YB | N |
| ext2 | 1993 | Linux | 16GB to 2TB4 | 2TB to 32TB | N |
| ext3 | 1999 | Linux | 16GB to 2TB4 | 2TB to 32TB | Y |
| ReiserFS3 | 2001 | Linux | 8TB8 | 16TB | Y |
| ReiserFS4 | 2005 | Linux | ? | ? | Y |
| XFS | 1994 | IRIX | 9EB | 9EB | Y |
| JFS | ? | AIX | 8EB | 512TB to 4PB | Y |
| VxFS | 1991 | SVR4.0 | 16EB | ? | Y |
| ZFS | 2004 | Solaris 10 | 1YB | 16EB | N |
Legend
Table 5-2. Sizes
| Kilobyte - KB | 1024 Bytes |
| Megabyte - MB | 1024 KBs |
| Gigabyte - GB | 1024 MBs |
| Terabyte - TB | 1024 GBs |
| Petabyte - PB | 1024 TBs |
| Exabyte - EB | 1024 PBs |
| Zettabyte - ZB | 1024 EBs |
| Yottabyte - YB | 1024 ZBs |
It should be noted that Exabytes, Zettabytes, and Yottabytes are rarely encountered, if ever. There is a current estimate that the worlds printed material is equal to 5 Exabytes. Therefore, some of these filesystem limitations are considered by many as theoretical. However, the filesystem software has been written with these capabilities.
For more detailed information you can visit http://en.wikipedia.org/wiki/Comparison_of_file_systems.
5.10.7. Mounting and unmounting
Before one can use a filesystem, it has to be mounted. The operating system then does various bookkeeping things to make sure that everything works. Since all files in UNIX are in a single directory tree, the mount operation will make it look like the contents of the new filesystem are the contents of an existing subdirectory in some already mounted filesystem.
For example, Figure 5-3 shows three separate filesystems, each with their own root directory. When the last two filesystems are mounted below /home and /usr, respectively, on the first filesystem, we can get a single directory tree, as in Figure 5-4.
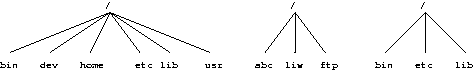
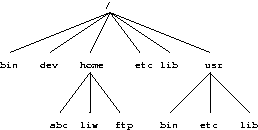
The mounts could be done as in the following example:
$ mount /dev/hda2 /home $ mount /dev/hda3 /usr $ |
Linux supports many filesystem types. mount tries to guess the type of the filesystem. You can also use the -t fstype option to specify the type directly; this is sometimes necessary, since the heuristics mount uses do not always work. For example, to mount an MS-DOS floppy, you could use the following command:
$ mount -t msdos /dev/fd0 /floppy $ |
The mounted-on directory need not be empty, although it must exist. Any files in it, however, will be inaccessible by name while the filesystem is mounted. (Any files that have already been opened will still be accessible. Files that have hard links from other directories can be accessed using those names.) There is no harm done with this, and it can even be useful. For instance, some people like to have /tmp and /var/tmp synonymous, and make /tmp be a symbolic link to /var/tmp. When the system is booted, before the /var filesystem is mounted, a /var/tmp directory residing on the root filesystem is used instead. When /var is mounted, it will make the /var/tmp directory on the root filesystem inaccessible. If /var/tmp didn't exist on the root filesystem, it would be impossible to use temporary files before mounting /var.
If you don't intend to write anything to the filesystem, use the -r switch for mount to do a read-only mount. This will make the kernel stop any attempts at writing to the filesystem, and will also stop the kernel from updating file access times in the inodes. Read-only mounts are necessary for unwritable media, e.g., CD-ROMs.
The alert reader has already noticed a slight logistical problem. How is the first filesystem (called the root filesystem, because it contains the root directory) mounted, since it obviously can't be mounted on another filesystem? Well, the answer is that it is done by magic. The root filesystem is magically mounted at boot time, and one can rely on it to always be mounted. If the root filesystem can't be mounted, the system does not boot. The name of the filesystem that is magically mounted as root is either compiled into the kernel, or set using LILO or rdev.
For more information, see the kernel source or the Kernel Hackers' Guide.
The root filesystem is usually first mounted read-only. The startup scripts will then run fsck to verify its validity, and if there are no problems, they will re-mount it so that writes will also be allowed. fsck must not be run on a mounted filesystem, since any changes to the filesystem while fsck is running will cause trouble. Since the root filesystem is mounted read-only while it is being checked, fsck can fix any problems without worry, since the remount operation will flush any metadata that the filesystem keeps in memory.
On many systems there are other filesystems that should also be mounted automatically at boot time. These are specified in the /etc/fstab file; see the fstab man page for details on the format. The details of exactly when the extra filesystems are mounted depend on many factors, and can be configured by each administrator if need be; see Chapter 8.
When a filesystem no longer needs to be mounted, it can be unmounted with umount. umount takes one argument: either the device file or the mount point. For example, to unmount the directories of the previous example, one could use the commands
$ umount /dev/hda2 $ umount /usr $ |
See the man page for further instructions on how to use the command. It is imperative that you always unmount a mounted floppy. Don't just pop the floppy out of the drive! Because of disk caching, the data is not necessarily written to the floppy until you unmount it, so removing the floppy from the drive too early might cause the contents to become garbled. If you only read from the floppy, this is not very likely, but if you write, even accidentally, the result may be catastrophic.
Mounting and unmounting requires super user privileges, i.e., only root can do it. The reason for this is that if any user can mount a floppy on any directory, then it is rather easy to create a floppy with, say, a Trojan horse disguised as /bin/sh, or any other often used program. However, it is often necessary to allow users to use floppies, and there are several ways to do this:
Give the users the root password. This is obviously bad security, but is the easiest solution. It works well if there is no need for security anyway, which is the case on many non-networked, personal systems.
Use a program such as sudo to allow users to use mount. This is still bad security, but doesn't directly give super user privileges to everyone. It requires several seconds of hard thinking on the users' behalf. Furthermore sudo can be configured to only allow users to execute certain commands. See the sudo(8), sudoers(5), and visudo(8) manual pages.
Make the users use mtools, a package for manipulating MS-DOS filesystems, without mounting them. This works well if MS-DOS floppies are all that is needed, but is rather awkward otherwise.
List the floppy devices and their allowable mount points together with the suitable options in /etc/fstab.
/dev/fd0 /floppy msdos user,noauto 0 0 |
The noauto option stops this mount to be done automatically when the system is started (i.e., it stops mount -a from mounting it). The user option allows any user to mount the filesystem, and, because of security reasons, disallows execution of programs (normal or setuid) and interpretation of device files from the mounted filesystem. After this, any user can mount a floppy with an msdos filesystem with the following command:
$ mount /floppy $ |
If you want to provide access to several types of floppies, you need to give several mount points. The settings can be different for each mount point. For example, to give access to both MS-DOS and ext2 floppies, you could have the following to lines in /etc/fstab:
/dev/fd0 /mnt/dosfloppy msdos user,noauto 0 0 /dev/fd0 /mnt/ext2floppy ext2 user,noauto 0 0 |
/dev/fd0 /mnt/floppy auto user,noauto 0 0
|
For MS-DOS filesystems (not just floppies), you probably want to restrict access to it by using the uid, gid, and umask filesystem options, described in detail on the mount manual page. If you aren't careful, mounting an MS-DOS filesystem gives everyone at least read access to the files in it, which is not a good idea.
5.10.8. Filesystem Security
TO BE ADDED
This section will describe mount options and how to use them in /etc/fstab to provide additional system security.
5.10.9. Checking filesystem integrity with fsck
Filesystems are complex creatures, and as such, they tend to be somewhat error-prone. A filesystem's correctness and validity can be checked using the fsck command. It can be instructed to repair any minor problems it finds, and to alert the user if there any unrepairable problems. Fortunately, the code to implement filesystems is debugged quite effectively, so there are seldom any problems at all, and they are usually caused by power failures, failing hardware, or operator errors; for example, by not shutting down the system properly.
Most systems are setup to run fsck automatically at boot time, so that any errors are detected (and hopefully corrected) before the system is used. Use of a corrupted filesystem tends to make things worse: if the data structures are messed up, using the filesystem will probably mess them up even more, resulting in more data loss. However, fsck can take a while to run on big filesystems, and since errors almost never occur if the system has been shut down properly, a couple of tricks are used to avoid doing the checks in such cases. The first is that if the file /etc/fastboot exists, no checks are made. The second is that the ext2 filesystem has a special marker in its superblock that tells whether the filesystem was unmounted properly after the previous mount. This allows e2fsck (the version of fsck for the ext2 filesystem) to avoid checking the filesystem if the flag indicates that the unmount was done (the assumption being that a proper unmount indicates no problems). Whether the /etc/fastboot trick works on your system depends on your startup scripts, but the ext2 trick works every time you use e2fsck. It has to be explicitly bypassed with an option to e2fsck to be avoided. (See the e2fsck man page for details on how.)
The automatic checking only works for the filesystems that are mounted automatically at boot time. Use fsck manually to check other filesystems, e.g., floppies.
If fsck finds unrepairable problems, you need either in-depth knowledge of how filesystems work in general, and the type of the corrupt filesystem in particular, or good backups. The latter is easy (although sometimes tedious) to arrange, the former can sometimes be arranged via a friend, the Linux newsgroups and mailing lists, or some other source of support, if you don't have the know-how yourself. I'd like to tell you more about it, but my lack of education and experience in this regard hinders me. The debugfs program by Theodore Ts'o should be useful.
fsck must only be run on unmounted filesystems, never on mounted filesystems (with the exception of the read-only root during startup). This is because it accesses the raw disk, and can therefore modify the filesystem without the operating system realizing it. There will be trouble, if the operating system is confused.
5.10.10. Checking for disk errors with badblocks
It can be a good idea to periodically check for bad blocks. This is done with the badblocks command. It outputs a list of the numbers of all bad blocks it can find. This list can be fed to fsck to be recorded in the filesystem data structures so that the operating system won't try to use the bad blocks for storing data. The following example will show how this could be done.
$ badblocks /dev/fd0H1440 1440 > bad-blocks $ fsck -t ext2 -l bad-blocks /dev/fd0H1440 Parallelizing fsck version 0.5a (5-Apr-94) e2fsck 0.5a, 5-Apr-94 for EXT2 FS 0.5, 94/03/10 Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure Pass 3: Checking directory connectivity Pass 4: Check reference counts. Pass 5: Checking group summary information. /dev/fd0H1440: ***** FILE SYSTEM WAS MODIFIED ***** /dev/fd0H1440: 11/360 files, 63/1440 blocks $ |
5.10.11. Fighting fragmentation?
When a file is written to disk, it can't always be written in consecutive blocks. A file that is not stored in consecutive blocks is fragmented. It takes longer to read a fragmented file, since the disk's read-write head will have to move more. It is desirable to avoid fragmentation, although it is less of a problem in a system with a good buffer cache with read-ahead.
Modern Linux filesystem keep fragmentation at a minimum by keeping all blocks in a file close together, even if they can't be stored in consecutive sectors. Some filesystems, like ext3, effectively allocate the free block that is nearest to other blocks in a file. Therefore it is not necessary to worry about fragmentation in a Linux system.
In the earlier days of the ext2 filesystem, there was a concern over file fragmentation that lead to the development of a defragmentation program called, defrag. A copy of it can still be downloaded at http://www.go.dlr.de/linux/src/defrag-0.73.tar.gz. However, it is HIGHLY recommended that you NOT use it. It was designed for and older version of ext2, and has not bee updated since 1998! I only mention it here for references purposes.
There are many MS-DOS defragmentation programs that move blocks around in the filesystem to remove fragmentation. For other filesystems, defragmentation must be done by backing up the filesystem, re-creating it, and restoring the files from backups. Backing up a filesystem before defragmenting is a good idea for all filesystems, since many things can go wrong during the defragmentation.
5.10.12. Other tools for all filesystems
Some other tools are also useful for managing filesystems. df shows the free disk space on one or more filesystems; du shows how much disk space a directory and all its files contain. These can be used to hunt down disk space wasters. Both have manual pages which detail the (many) options which can be used.
sync forces all unwritten blocks in the buffer cache (see Section 6.6) to be written to disk. It is seldom necessary to do this by hand; the daemon process update does this automatically. It can be useful in catastrophes, for example if update or its helper process bdflush dies, or if you must turn off power now and can't wait for update to run. Again, there are manual pages. The man is your very best friend in Linux. Its cousin apropos is also very useful when you don't know what the name of the command you want is.
5.10.13. Other tools for the ext2/ext3 filesystem
In addition to the filesystem creator (mke2fs) and checker (e2fsck) accessible directly or via the filesystem type independent front ends, the ext2 filesystem has some additional tools that can be useful.
tune2fs adjusts filesystem parameters. Some of the more interesting parameters are:
A maximal mount count. e2fsck enforces a check when filesystem has been mounted too many times, even if the clean flag is set. For a system that is used for developing or testing the system, it might be a good idea to reduce this limit.
A maximal time between checks. e2fsck can also enforce a maximal time between two checks, even if the clean flag is set, and the filesystem hasn't been mounted very often. This can be disabled, however.
Number of blocks reserved for root. Ext2 reserves some blocks for root so that if the filesystem fills up, it is still possible to do system administration without having to delete anything. The reserved amount is by default 5 percent, which on most disks isn't enough to be wasteful. However, for floppies there is no point in reserving any blocks.
dumpe2fs shows information about an ext2 or ext3 filesystem, mostly from the superblock. Below is a sample output. Some of the information in the output is technical and requires understanding of how the filesystem works, but much of it is readily understandable even for lay-admins.
# dumpe2fs dumpe2fs 1.32 (09-Nov-2002) Filesystem volume name: / Last mounted on: not available Filesystem UUID: 51603f82-68f3-4ae7-a755-b777ff9dc739 Filesystem magic number: 0xEF53 Filesystem revision #: 1 (dynamic) Filesystem features: has_journal filetype needs_recovery sparse_super Default mount options: (none) Filesystem state: clean Errors behavior: Continue Filesystem OS type: Linux Inode count: 3482976 Block count: 6960153 Reserved block count: 348007 Free blocks: 3873525 Free inodes: 3136573 First block: 0 Block size: 4096 Fragment size: 4096 Blocks per group: 32768 Fragments per group: 32768 Inodes per group: 16352 Inode blocks per group: 511 Filesystem created: Tue Aug 26 08:11:55 2003 Last mount time: Mon Dec 22 08:23:12 2003 Last write time: Mon Dec 22 08:23:12 2003 Mount count: 3 Maximum mount count: -1 Last checked: Mon Nov 3 11:27:38 2003 Check interval: 0 (none) Reserved blocks uid: 0 (user root) Reserved blocks gid: 0 (group root) First inode: 11 Inode size: 128 Journal UUID: none Journal inode: 8 Journal device: 0x0000 First orphan inode: 655612 Group 0: (Blocks 0-32767) Primary superblock at 0, Group descriptors at 1-2 Block bitmap at 3 (+3), Inode bitmap at 4 (+4) Block bitmap at 3 (+3), Inode bitmap at 4 (+4) Inode table at 5-515 (+5) 3734 free blocks, 16338 free inodes, 2 directories |
debugfs is a filesystem debugger. It allows direct access to the filesystem data structures stored on disk and can thus be used to repair a disk that is so broken that fsck can't fix it automatically. It has also been known to be used to recover deleted files. However, debugfs very much requires that you understand what you're doing; a failure to understand can destroy all your data.
dump and restore can be used to back up an ext2 filesystem. They are ext2 specific versions of the traditional UNIX backup tools. See Section 12.1 for more information on backups.
5.11. Disks without filesystems
Not all disks or partitions are used as filesystems. A swap partition, for example, will not have a filesystem on it. Many floppies are used in a tape-drive emulating fashion, so that a tar (tape archive) or other file is written directly on the raw disk, without a filesystem. Linux boot floppies don't contain a filesystem, only the raw kernel.
Avoiding a filesystem has the advantage of making more of the disk usable, since a filesystem always has some bookkeeping overhead. It also makes the disks more easily compatible with other systems: for example, the tar file format is the same on all systems, while filesystems are different on most systems. You will quickly get used to disks without filesystems if you need them. Bootable Linux floppies also do not necessarily have a filesystem, although they may.
One reason to use raw disks is to make image copies of them. For instance, if the disk contains a partially damaged filesystem, it is a good idea to make an exact copy of it before trying to fix it, since then you can start again if your fixing breaks things even more. One way to do this is to use dd:
$ dd if=/dev/fd0H1440 of=floppy-image 2880+0 records in 2880+0 records out $ dd if=floppy-image of=/dev/fd0H1440 2880+0 records in 2880+0 records out $ |
5.12. Allocating disk space
5.12.1. Partitioning schemes
When it comes to partitioning your machine, there is no universally correct way to do it. There are many factors that must be taken into account depending on the purpose of the machine.
For a simple workstation with limited disk space, such as a laptop, you may have as few a 3 partitions. A partition for /, /boot, and swap. However, for most users this is not a recommended solution.
The traditional way is to have a (relatively) small root filesystem, and separate partitions for filesystems such as /usr and /home>. Creating a separate root filesystem if the root filesystem is small and not heavily used, it is less likely to become corrupt when the system crashes, and therefore make it easier to recover a crashed system. The reason is to prevent having the root filesystem get filled and cause a system crash.
When creating your partitioning scheme, there are some things you need to remember. You cannot create separate partitions for the following directories: /bin, /etc, /dev, /initrd, /lib, and /sbin. The contents of these directories are required at bootup and must always be part of the / partition.
It is also recommended that you create separate partitions for /var and /tmp. This is because both directories typically have data that is constantly changing. Not creating separate partitions for these filesystems puts you at risk of having log file fill up our / partition.
An example of a server partition is:
Filesystem Size Used Avail Use% Mounted on /dev/hda2 9.7G 1.3G 8.0G 14% / /dev/hda1 128M 44M 82M 34% /boot /dev/hda3 4.9G 4.0G 670M 86% /usr /dev/hda5 4.9G 2.1G 2.5G 46% /var /dev/hda7 31G 24G 5.6G 81% /home /dev/hda8 4.9G 2.0G 670M 43% /opt |
The problem with having many partitions is that it splits the total amount of free disk space into many small pieces. One way to avoid this problem is to use to create Logical Volumes.
5.12.2. Logical Volume Manager (LVM)
Using LVM allows administrators the flexibility to create logical disks that can be expanded dynamically as more disk space is required.
This is done first by creating partitions with as an 0x8e Linux LVM partition type. Then the Physical Partitions are added to a Volume Group and broken up into chunks, or Physical Extents Volume Group. These extends can then be grouped into Logical Volumes. These Logical Volumes then can be formatted just like a physical partition. The big difference is that they can be expanded by adding more extents to them.
Right now, a full discussion of LVM is beyond the scope of this guide. However, and excellent resource for learning more about LVM can be found at http://www.tldp.org/HOWTO/LVM-HOWTO.html.
5.12.3. Space requirements
The Linux distribution you install will give some indication of how much disk space you need for various configurations. Programs installed separately may also do the same. This will help you plan your disk space usage, but you should prepare for the future and reserve some extra space for things you will notice later that you need.
The amount you need for user files depends on what your users wish to do. Most people seem to need as much space for their files as possible, but the amount they will live happily with varies a lot. Some people do only light text processing and will survive nicely with a few megabytes, others do heavy image processing and will need gigabytes.
By the way, when comparing file sizes given in kilobytes or megabytes and disk space given in megabytes, it can be important to know that the two units can be different. Some disk manufacturers like to pretend that a kilobyte is 1000 bytes and a megabyte is 1000 kilobytes, while all the rest of the computing world uses 1024 for both factors. Therefore, a 345 MB hard disk is really a 330 MB hard disk.
Swap space allocation is discussed in Section 6.5.
5.12.4. Examples of hard disk allocation
I used to have a 10 GB hard disk. Now I am using a 30 GB hard disk. I'll explain how and why I partitioned those disks.
First, I created a /boot partition at 128 MG. This is larger than I will need, and big enough to give me space if I need it. I created a separate /boot partition to ensure that this filesystem will never get filled up, and therefore will be bootable. Then I created a 5 GB /var partition. Since the /var filesystem is where log files and email is stored I wanted to isolate it from my root partition. (I have had log files grow overnight and fill my root filesystem in the past.) Next, I created a 15 GB /home partition. This is handy in the event of a system crash. If I ever have to re-install Linux from scratch, I can tell the installation program to not format this partition, and instead remount it without the data being lost. Finally since I had 512 MG of RAM I created a 1024 MG (or 1 GB) swap partition. This left me with roughly a 9 GB root filesystem. I using my old 10 GB hard drive, I created an 8 GB /usr partition and left 2 GB unused. This is incase I need more space in the future.
In the end, my partition tables looked like this:
5.12.5. Adding more disk space for Linux
Adding more disk space for Linux is easy, at least after the hardware has been properly installed (the hardware installation is outside the scope of this book). You format it if necessary, then create the partitions and filesystem as described above, and add the proper lines to /etc/fstab so that it is mounted automatically.
5.12.6. Tips for saving disk space
The best tip for saving disk space is to avoid installing unnecessary programs. Most Linux distributions have an option to install only part of the packages they contain, and by analyzing your needs you might notice that you don't need most of them. This will help save a lot of disk space, since many programs are quite large. Even if you do need a particular package or program, you might not need all of it. For example, some on-line documentation might be unnecessary, as might some of the Elisp files for GNU Emacs, some of the fonts for X11, or some of the libraries for programming.
If you cannot uninstall packages, you might look into compression. Compression programs such as gzip or zip will compress (and uncompress) individual files or groups of files. The gzexe system will compress and uncompress programs invisibly to the user (unused programs are compressed, then uncompressed as they are used). The experimental DouBle system will compress all files in a filesystem, invisibly to the programs that use them. (If you are familiar with products such as Stacker for MS-DOS or DriveSpace for Windows, the principle is the same.)
Another way to save space is to take special care when formatting you partitions. Most modern filesystems will allow you to specify the block size. The block size is chunk size that the filesystem will use to read and write data. Larger block sizes will help disk I/O performance when using large files, such as databases. This happens because the disk can read or write data for a longer period of time before having to search for the next block. The
Chapter 6. Memory Management
"Minnet, jag har tappat mitt minne, �r jag svensk eller finne, kommer inte ih�g..." (Bosse �sterberg)
A Swedish drinking song, (rough) translation: ``Memory, I have lost my memory. Am I Swedish or Finnish? I can't remember''
This section describes the Linux memory management features, i.e., virtual memory and the disk buffer cache. The purpose and workings and the things the system administrator needs to take into consideration are described.
6.1. What is virtual memory?
Linux supports virtual memory, that is, using a disk as an extension of RAM so that the effective size of usable memory grows correspondingly. The kernel will write the contents of a currently unused block of memory to the hard disk so that the memory can be used for another purpose. When the original contents are needed again, they are read back into memory. This is all made completely transparent to the user; programs running under Linux only see the larger amount of memory available and don't notice that parts of them reside on the disk from time to time. Of course, reading and writing the hard disk is slower (on the order of a thousand times slower) than using real memory, so the programs don't run as fast. The part of the hard disk that is used as virtual memory is called the swap space.
Linux can use either a normal file in the filesystem or a separate partition for swap space. A swap partition is faster, but it is easier to change the size of a swap file (there's no need to repartition the whole hard disk, and possibly install everything from scratch). When you know how much swap space you need, you should go for a swap partition, but if you are uncertain, you can use a swap file first, use the system for a while so that you can get a feel for how much swap you need, and then make a swap partition when you're confident about its size.
You should also know that Linux allows one to use several swap partitions and/or swap files at the same time. This means that if you only occasionally need an unusual amount of swap space, you can set up an extra swap file at such times, instead of keeping the whole amount allocated all the time.
A note on operating system terminology: computer science usually distinguishes between swapping (writing the whole process out to swap space) and paging (writing only fixed size parts, usually a few kilobytes, at a time). Paging is usually more efficient, and that's what Linux does, but traditional Linux terminology talks about swapping anyway.
6.2. Creating a swap space
A swap file is an ordinary file; it is in no way special to the kernel. The only thing that matters to the kernel is that it has no holes, and that it is prepared for use with mkswap. It must reside on a local disk, however; it can't reside in a filesystem that has been mounted over NFS due to implementation reasons.
The bit about holes is important. The swap file reserves the disk space so that the kernel can quickly swap out a page without having to go through all the things that are necessary when allocating a disk sector to a file. The kernel merely uses any sectors that have already been allocated to the file. Because a hole in a file means that there are no disk sectors allocated (for that place in the file), it is not good for the kernel to try to use them.
One good way to create the swap file without holes is through the following command:
$ dd if=/dev/zero of=/extra-swap bs=1024 count=1024 1024+0 records in 1024+0 records out $ |
A swap partition is also not special in any way. You create it just like any other partition; the only difference is that it is used as a raw partition, that is, it will not contain any filesystem at all. It is a good idea to mark swap partitions as type 82 (Linux swap); this will the make partition listings clearer, even though it is not strictly necessary to the kernel.
After you have created a swap file or a swap partition, you need to write a signature to its beginning; this contains some administrative information and is used by the kernel. The command to do this is mkswap, used like this:
$ mkswap /extra-swap 1024 Setting up swapspace, size = 1044480 bytes $ |
You should be very careful when using mkswap, since it does not check that the file or partition isn't used for anything else. You can easily overwrite important files and partitions with mkswap! Fortunately, you should only need to use mkswap when you install your system.
The Linux memory manager limits the size of each swap space to 2 GB. You can, however, use up to 8 swap spaces simultaneously, for a total of 16GB.
6.3. Using a swap space
An initialized swap space is taken into use with swapon. This command tells the kernel that the swap space can be used. The path to the swap space is given as the argument, so to start swapping on a temporary swap file one might use the following command.
$ swapon /extra-swap $ |
/dev/hda8 none swap sw 0 0 /swapfile none swap sw 0 0 |
You can monitor the use of swap spaces with free. It will tell the total amount of swap space used.
$ free
total used free shared
buffers
Mem: 15152 14896 256 12404 2528
-/+ buffers: 12368 2784
Swap: 32452 6684 25768
$ |
That last line (Swap:) shows similar information for the swap spaces. If this line is all zeroes, your swap space is not activated.
The same information is available via top, or using the proc filesystem in file /proc/meminfo. It is currently difficult to get information on the use of a specific swap space.
A swap space can be removed from use with swapoff. It is usually not necessary to do it, except for temporary swap spaces. Any pages in use in the swap space are swapped in first; if there is not sufficient physical memory to hold them, they will then be swapped out (to some other swap space). If there is not enough virtual memory to hold all of the pages Linux will start to thrash; after a long while it should recover, but meanwhile the system is unusable. You should check (e.g., with free) that there is enough free memory before removing a swap space from use.
All the swap spaces that are used automatically with swapon -a can be removed from use with swapoff -a; it looks at the file /etc/fstab to find what to remove. Any manually used swap spaces will remain in use.
Sometimes a lot of swap space can be in use even though there is a lot of free physical memory. This can happen for instance if at one point there is need to swap, but later a big process that occupied much of the physical memory terminates and frees the memory. The swapped-out data is not automatically swapped in until it is needed, so the physical memory may remain free for a long time. There is no need to worry about this, but it can be comforting to know what is happening.
6.4. Sharing swap spaces with other operating systems
Virtual memory is built into many operating systems. Since they each need it only when they are running, i.e., never at the same time, the swap spaces of all but the currently running one are being wasted. It would be more efficient for them to share a single swap space. This is possible, but can require a bit of hacking. The Tips-HOWTO at http://www.tldp.org/HOWTO/Tips-HOWTO.html, which contains some advice on how to implement this.
6.5. Allocating swap space
Some people will tell you that you should allocate twice as much swap space as you have physical memory, but this is a bogus rule. Here's how to do it properly:
Estimate your total memory needs. This is the largest amount of memory you'll probably need at a time, that is the sum of the memory requirements of all the programs you want to run at the same time. This can be done by running at the same time all the programs you are likely to ever be running at the same time.
For instance, if you want to run X, you should allocate about 8 MB for it, gcc wants several megabytes (some files need an unusually large amount, up to tens of megabytes, but usually about four should do), and so on. The kernel will use about a megabyte by itself, and the usual shells and other small utilities perhaps a few hundred kilobytes (say a megabyte together). There is no need to try to be exact, rough estimates are fine, but you might want to be on the pessimistic side.
Remember that if there are going to be several people using the system at the same time, they are all going to consume memory. However, if two people run the same program at the same time, the total memory consumption is usually not double, since code pages and shared libraries exist only once.
The free and ps commands are useful for estimating the memory needs.
Add some security to the estimate in step 1. This is because estimates of program sizes will probably be wrong, because you'll probably forget some programs you want to run, and to make certain that you have some extra space just in case. A couple of megabytes should be fine. (It is better to allocate too much than too little swap space, but there's no need to over-do it and allocate the whole disk, since unused swap space is wasted space; see later about adding more swap.) Also, since it is nicer to deal with even numbers, you can round the value up to the next full megabyte.
Based on the computations above, you know how much memory you'll be needing in total. So, in order to allocate swap space, you just need to subtract the size of your physical memory from the total memory needed, and you know how much swap space you need. (On some versions of UNIX, you need to allocate space for an image of the physical memory as well, so the amount computed in step 2 is what you need and you shouldn't do the subtraction.)
If your calculated swap space is very much larger than your physical memory (more than a couple times larger), you should probably invest in more physical memory, otherwise performance will be too low.
It's a good idea to have at least some swap space, even if your calculations indicate that you need none. Linux uses swap space somewhat aggressively, so that as much physical memory as possible can be kept free. Linux will swap out memory pages that have not been used, even if the memory is not yet needed for anything. This avoids waiting for swapping when it is needed: the swapping can be done earlier, when the disk is otherwise idle.
Swap space can be divided among several disks. This can sometimes improve performance, depending on the relative speeds of the disks and the access patterns of the disks. You might want to experiment with a few schemes, but be aware that doing the experiments properly is quite difficult. You should not believe claims that any one scheme is superior to any other, since it won't always be true.
6.6. The buffer cache
Reading from a disk is very slow compared to accessing (real) memory. In addition, it is common to read the same part of a disk several times during relatively short periods of time. For example, one might first read an e-mail message, then read the letter into an editor when replying to it, then make the mail program read it again when copying it to a folder. Or, consider how often the command ls might be run on a system with many users. By reading the information from disk only once and then keeping it in memory until no longer needed, one can speed up all but the first read. This is called disk buffering, and the memory used for the purpose is called the buffer cache.
Since memory is, unfortunately, a finite, nay, scarce resource, the buffer cache usually cannot be big enough (it can't hold all the data one ever wants to use). When the cache fills up, the data that has been unused for the longest time is discarded and the memory thus freed is used for the new data.
Disk buffering works for writes as well. On the one hand, data that is written is often soon read again (e.g., a source code file is saved to a file, then read by the compiler), so putting data that is written in the cache is a good idea. On the other hand, by only putting the data into the cache, not writing it to disk at once, the program that writes runs quicker. The writes can then be done in the background, without slowing down the other programs.
Most operating systems have buffer caches (although they might be called something else), but not all of them work according to the above principles. Some are write-through: the data is written to disk at once (it is kept in the cache as well, of course). The cache is called write-back if the writes are done at a later time. Write-back is more efficient than write-through, but also a bit more prone to errors: if the machine crashes, or the power is cut at a bad moment, or the floppy is removed from the disk drive before the data in the cache waiting to be written gets written, the changes in the cache are usually lost. This might even mean that the filesystem (if there is one) is not in full working order, perhaps because the unwritten data held important changes to the bookkeeping information.
Because of this, you should never turn off the power without using a proper shutdown procedure or remove a floppy from the disk drive until it has been unmounted (if it was mounted) or after whatever program is using it has signaled that it is finished and the floppy drive light doesn't shine anymore. The sync command flushes the buffer, i.e., forces all unwritten data to be written to disk, and can be used when one wants to be sure that everything is safely written. In traditional UNIX systems, there is a program called update running in the background which does a sync every 30 seconds, so it is usually not necessary to use sync. Linux has an additional daemon, bdflush, which does a more imperfect sync more frequently to avoid the sudden freeze due to heavy disk I/O that sync sometimes causes.
Under Linux, bdflush is started by update. There is usually no reason to worry about it, but if bdflush happens to die for some reason, the kernel will warn about this, and you should start it by hand (/sbin/update).
The cache does not actually buffer files, but blocks, which are the smallest units of disk I/O (under Linux, they are usually 1 KB). This way, also directories, super blocks, other filesystem bookkeeping data, and non-filesystem disks are cached.
The effectiveness of a cache is primarily decided by its size. A small cache is next to useless: it will hold so little data that all cached data is flushed from the cache before it is reused. The critical size depends on how much data is read and written, and how often the same data is accessed. The only way to know is to experiment.
If the cache is of a fixed size, it is not very good to have it too big, either, because that might make the free memory too small and cause swapping (which is also slow). To make the most efficient use of real memory, Linux automatically uses all free RAM for buffer cache, but also automatically makes the cache smaller when programs need more memory.
Under Linux, you do not need to do anything to make use of the cache, it happens completely automatically. Except for following the proper procedures for shutdown and removing floppies, you do not need to worry about it.
Chapter 7. System Monitoring
"That's Hall Monitor to you!"Spongebob Squarepants
One of the most important responsibilities a system administrator has, is monitoring their systems. As a system administrator you'll need the ability to find out what is happening on your system at any given time. Whether it's the percentage of system's resources currently used, what commands are being run, or who is logged on. This chapter will cover how to monitor your system, and in some cases, how to resolve problems that may arise.
When a performance issue arises, there are 4 main areas to consider: CPU, Memory, Disk I/O, and Network. The ability to determine where the bottleneck is can save you a lot of time.
7.1. System Resources
Being able to monitor the performance of your system is essential. If system resources become to low it can cause a lot of problems. System resources can be taken up by individual users, or by services your system may host such as email or web pages. The ability to know what is happening can help determine whether system upgrades are needed, or if some services need to be moved to another machine.
7.1.1. The top command.
The most common of these commands is top. The top will display a continually updating report of system resource usage.
# top
12:10:49 up 1 day, 3:47, 7 users, load average: 0.23, 0.19, 0.10
125 processes: 105 sleeping, 2 running, 18 zombie, 0 stopped
CPU states: 5.1% user 1.1% system 0.0% nice 0.0% iowait 93.6% idle
Mem: 512716k av, 506176k used, 6540k free, 0k shrd, 21888k buff
Swap: 1044216k av, 161672k used, 882544k free 199388k cached
PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME CPU COMMAND
2330 root 15 0 161M 70M 2132 S 4.9 14.0 1000m 0 X
2605 weeksa 15 0 8240 6340 3804 S 0.3 1.2 1:12 0 kdeinit
3413 weeksa 15 0 6668 5324 3216 R 0.3 1.0 0:20 0 kdeinit
18734 root 15 0 1192 1192 868 R 0.3 0.2 0:00 0 top
1619 root 15 0 776 608 504 S 0.1 0.1 0:53 0 dhclient
1 root 15 0 480 448 424 S 0.0 0.0 0:03 0 init
2 root 15 0 0 0 0 SW 0.0 0.0 0:00 0 keventd
3 root 15 0 0 0 0 SW 0.0 0.0 0:00 0 kapmd
4 root 35 19 0 0 0 SWN 0.0 0.0 0:00 0 ksoftirqd_CPU0
9 root 25 0 0 0 0 SW 0.0 0.0 0:00 0 bdflush
5 root 15 0 0 0 0 SW 0.0 0.0 0:00 0 kswapd
10 root 15 0 0 0 0 SW 0.0 0.0 0:00 0 kupdated
11 root 25 0 0 0 0 SW 0.0 0.0 0:00 0 mdrecoveryd
15 root 15 0 0 0 0 SW 0.0 0.0 0:01 0 kjournald
81 root 25 0 0 0 0 SW 0.0 0.0 0:00 0 khubd
1188 root 15 0 0 0 0 SW 0.0 0.0 0:00 0 kjournald
1675 root 15 0 604 572 520 S 0.0 0.1 0:00 0 syslogd
1679 root 15 0 428 376 372 S 0.0 0.0 0:00 0 klogd
1707 rpc 15 0 516 440 436 S 0.0 0.0 0:00 0 portmap
1776 root 25 0 476 428 424 S 0.0 0.0 0:00 0 apmd
1813 root 25 0 752 528 524 S 0.0 0.1 0:00 0 sshd
1828 root 25 0 704 548 544 S 0.0 0.1 0:00 0 xinetd
1847 ntp 15 0 2396 2396 2160 S 0.0 0.4 0:00 0 ntpd
1930 root 24 0 76 4 0 S 0.0 0.0 0:00 0 rpc.rquotad |
The top portion of the report lists information such as the system time, uptime, CPU usage, physical ans swap memory usage, and number of processes. Below that is a list of the processes sorted by CPU utilization.
You can modify the output of top while is is running. If you hit an i, top will no longer display idle processes. Hit i again to see them again. Hitting M will sort by memory usage, S will sort by how long they processes have been running, and P will sort by CPU usage again.
In addition to viewing options, you can also modify processes from within the top command. You can use u to view processes owned by a specific user, k to kill processes, and r to renice them.
For more in-depth information about processes you can look in the /proc filesystem. In the /proc filesystem you will find a series of sub-directories with numeric names. These directories are associated with the processes ids of currently running processes. In each directory you will find a series of files containing information about the process.
YOU MUST TAKE EXTREME CAUTION TO NOT MODIFY THESE FILES, DOING SO MAY CAUSE SYSTEM PROBLEMS!
7.1.2. The iostat command.
The iostat will display the current CPU load average and disk I/O information. This is a great command to monitor your disk I/O usage.
# iostat
Linux 2.4.20-24.9 (myhost) 12/23/2003
avg-cpu: %user %nice %sys %idle
62.09 0.32 2.97 34.62
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
dev3-0 2.22 15.20 47.16 1546846 4799520 |
# iostat -x
Linux 2.4.20-24.9 (myhost) 12/23/2003
avg-cpu: %user %nice %sys %idle
62.01 0.32 2.97 34.71
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/hdc 0.00 0.00 .00 0.00 0.00 0.00 0.00 0.00 0.00 2.35 0.00 0.00 14.71
/dev/hda 1.13 4.50 .81 1.39 15.18 47.14 7.59 23.57 28.24 1.99 63.76 70.48 15.56
/dev/hda1 1.08 3.98 .73 1.27 14.49 42.05 7.25 21.02 28.22 0.44 21.82 4.97 1.00
/dev/hda2 0.00 0.51 .07 0.12 0.55 5.07 0.27 2.54 30.35 0.97 52.67 61.73 2.99
/dev/hda3 0.05 0.01 .02 0.00 0.14 0.02 0.07 0.01 8.51 0.00 12.55 2.95 0.01 |
The iostat man page contains a detailed explanation of what each of these columns mean.
7.1.3. The ps command
The ps will provide you a list of processes currently running. There is a wide variety of options that this command gives you.
A common use would be to list all processes currently running. To do this you would use the ps -ef command. (Screen output from this command is too large to include, the following is only a partial output.)
UID PID PPID C STIME TTY TIME CMD root 1 0 0 Dec22 ? 00:00:03 init root 2 1 0 Dec22 ? 00:00:00 [keventd] root 3 1 0 Dec22 ? 00:00:00 [kapmd] root 4 1 0 Dec22 ? 00:00:00 [ksoftirqd_CPU0] root 9 1 0 Dec22 ? 00:00:00 [bdflush] root 5 1 0 Dec22 ? 00:00:00 [kswapd] root 6 1 0 Dec22 ? 00:00:00 [kscand/DMA] root 7 1 0 Dec22 ? 00:01:28 [kscand/Normal] root 8 1 0 Dec22 ? 00:00:00 [kscand/HighMem] root 10 1 0 Dec22 ? 00:00:00 [kupdated] root 11 1 0 Dec22 ? 00:00:00 [mdrecoveryd] root 15 1 0 Dec22 ? 00:00:01 [kjournald] root 81 1 0 Dec22 ? 00:00:00 [khubd] root 1188 1 0 Dec22 ? 00:00:00 [kjournald] root 1675 1 0 Dec22 ? 00:00:00 syslogd -m 0 root 1679 1 0 Dec22 ? 00:00:00 klogd -x rpc 1707 1 0 Dec22 ? 00:00:00 portmap root 1813 1 0 Dec22 ? 00:00:00 /usr/sbin/sshd ntp 1847 1 0 Dec22 ? 00:00:00 ntpd -U ntp root 1930 1 0 Dec22 ? 00:00:00 rpc.rquotad root 1934 1 0 Dec22 ? 00:00:00 [nfsd] root 1942 1 0 Dec22 ? 00:00:00 [lockd] root 1943 1 0 Dec22 ? 00:00:00 [rpciod] root 1949 1 0 Dec22 ? 00:00:00 rpc.mountd root 1961 1 0 Dec22 ? 00:00:00 /usr/sbin/vsftpd /etc/vsftpd/vsftpd.conf root 2057 1 0 Dec22 ? 00:00:00 /usr/bin/spamd -d -c -a root 2066 1 0 Dec22 ? 00:00:00 gpm -t ps/2 -m /dev/psaux bin 2076 1 0 Dec22 ? 00:00:00 /usr/sbin/cannaserver -syslog -u bin root 2087 1 0 Dec22 ? 00:00:00 crond daemon 2195 1 0 Dec22 ? 00:00:00 /usr/sbin/atd root 2215 1 0 Dec22 ? 00:00:11 /usr/sbin/rcd weeksa 3414 3413 0 Dec22 pts/1 00:00:00 /bin/bash weeksa 4342 3413 0 Dec22 pts/2 00:00:00 /bin/bash weeksa 19121 18668 0 12:58 pts/2 00:00:00 ps -ef |
The first column shows who owns the process. The second column is the process ID. The Third column is the parent process ID. This is the process that generated, or started, the process. The forth column is the CPU usage (in percent). The fifth column is the start time, of date if the process has been running long enough. The sixth column is the tty associated with the process, if applicable. The seventh column is the cumulitive CPU usage (total amount of CPU time is has used while running). The eighth column is the command itself.
With this information you can see exacly what is running on your system and kill run-away processes, or those that are causing problems.
7.1.4. The vmstat command
The vmstat command will provide a report showing statistics for system processes, memory, swap, I/O, and the CPU. These statistics are generated using data from the last time the command was run to the present. In the case of the command never being run, the data will be from the last reboot until the present.
# vmstat procs memory swap io system cpu r b w swpd free buff cache si so bi bo in cs us sy id 0 0 0 181604 17000 26296 201120 0 2 8 24 149 9 61 3 36 |
The following was taken from the vmstat man page.
FIELD DESCRIPTIONS
Procs
r: The number of processes waiting for run time.
b: The number of processes in uninterruptable sleep.
w: The number of processes swapped out but otherwise runnable. This
field is calculated, but Linux never desperation swaps.
Memory
swpd: the amount of virtual memory used (kB).
free: the amount of idle memory (kB).
buff: the amount of memory used as buffers (kB).
Swap
si: Amount of memory swapped in from disk (kB/s).
so: Amount of memory swapped to disk (kB/s).
IO
bi: Blocks sent to a block device (blocks/s).
bo: Blocks received from a block device (blocks/s).
System
in: The number of interrupts per second, including the clock.
cs: The number of context switches per second.
CPU
These are percentages of total CPU time.
us: user time
sy: system time
id: idle time
7.1.5. The lsof command
The lsof command will print out a list of every file that is in use. Since Linux considers everythihng a file, this list can be very long. However, this command can be useful in diagnosing problems. An example of this is if you wish to unmount a filesystem, but you are being told that it is in use. You could use this command and grep for the name of the filesystem to see who is using it.
Or suppose you want to see all files in use by a particular process. To do this you would use lsof -p -processid-.
7.1.6. Finding More Utilities
To learn more about what command line tools are available, Chris Karakas has wrote a reference guide titled GNU/Linux Command-Line Tools Summary. It's a good resource for learning what tools are out there and how to do a number of tasks.
7.2. Filesystem Usage
Many reports are currently talking about how cheap storage has gotten, but if you're like most of us it isn't cheap enough. Most of us have a limited amount of space, and need to be able to monitor it and control how it's used.
7.2.1. The df command
The df is the simplest tool available to view disk usage. Simply type in df and you'll be shown disk usage for all your mounted filesystems in 1K blocks
user@server:~> df Filesystem 1K-blocks Used Available Use% Mounted on /dev/hda3 5242904 759692 4483212 15% / tmpfs 127876 8 127868 1% /dev/shm /dev/hda1 127351 33047 87729 28% /boot /dev/hda9 10485816 33508 10452308 1% /home /dev/hda8 5242904 932468 4310436 18% /srv /dev/hda7 3145816 32964 3112852 2% /tmp /dev/hda5 5160416 474336 4423928 10% /usr /dev/hda6 3145816 412132 2733684 14% /var |
You can also use the -h to see the output in "human-readable" format. This will be in K, Megs, or Gigs depending on the size of the filesystem. Alternately, you can also use the -B to specify block size.
In addition to space usage, you could use the -i option to view the number of used and available inodes.
user@server:~> df -i Filesystem Inodes IUsed IFree IUse% Mounted on /dev/hda3 0 0 0 - / tmpfs 31969 5 31964 1% /dev/shm /dev/hda1 32912 47 32865 1% /boot /dev/hda9 0 0 0 - /home /dev/hda8 0 0 0 - /srv /dev/hda7 0 0 0 - /tmp /dev/hda5 656640 26651 629989 5% /usr /dev/hda6 0 0 0 - /var |
7.2.2. The du command
Now that you know how much space has been used on a filesystem how can you find out where that data is? To view usage by a directory or file you can use du. Unless you specify a filename du will act recursively. For example:
user@server:~> du file.txt 1300 file.txt |
user@server:~> du -h file.txt 1.3M file.txt |
Unless you specify a filename du will act recursively.
user@server:~> du -h /usr/local 4.0K /usr/local/games 16K /usr/local/include/nessus/net 180K /usr/local/include/nessus 208K /usr/local/include 62M /usr/local/lib/nessus/plugins/.desc 97M /usr/local/lib/nessus/plugins 164K /usr/local/lib/nessus/plugins_factory 97M /usr/local/lib/nessus 12K /usr/local/lib/pkgconfig 2.7M /usr/local/lib/ladspa 104M /usr/local/lib 112K /usr/local/man/man1 4.0K /usr/local/man/man2 4.0K /usr/local/man/man3 4.0K /usr/local/man/man4 16K /usr/local/man/man5 4.0K /usr/local/man/man |
If you just want a summary of that directory you can use the -s option.
user@server:~> du -hs /usr/local 210M /usr/local |
7.3. Monitoring Users
Just because you're paranoid doesn't mean they AREN'T out to get you... Source Unknown
From time to time there are going to be occasions where you will want to know exactly what people are doing on your system. Maybe you notice that a lot of RAM is being used, or a lot of CPU activity. You are going to want to see who is on the system, what they are running, and what kind of resources they are using.
7.3.1. The who command
The easiest way to see who is on the system is to do a who or w. The --> who is a simple tool that lists out who is logged --> on the system and what port or terminal they are logged on at.
user@server:~> who bjones pts/0 May 23 09:33 wally pts/3 May 20 11:35 aweeks pts/1 May 22 11:03 aweeks pts/2 May 23 15:04 |
7.3.2. The ps command -again!
In the previous section we can see that user aweeks is logged onto both pts/1 and pts/2, but what if we want to see what they are doing? We could to a ps -u aweeks and get the following output
user@server:~> ps -u aweeks 20876 pts/1 00:00:00 bash 20904 pts/2 00:00:00 bash 20951 pts/2 00:00:00 ssh 21012 pts/1 00:00:00 ps |
This is a much more consolidated use of the ps than discussed previously.
7.3.3. The w command
Even easier than using the who and ps -u commands is to use the w. w will print out not only who is on the system, but also the commands they are running.
user@server:~> w aweeks :0 09:32 ?xdm? 30:09 0.02s -:0 aweeks pts/0 09:33 5:49m 0.00s 0.82s kdeinit: kded aweeks pts/2 09:35 8.00s 0.55s 0.36s vi sag-0.9.sgml aweeks pts/1 15:03 59.00s 0.03s 0.03s /bin/bash |
From this we can see that I have a kde session running, I'm working in this document :-), and have another terminal open sitting idle at a bash prompt.
Chapter 8. Boots And Shutdowns
Start me up
Ah... you've got to... you've got to
Never, never never stop
Start it up
Ah... start it up, never, never, never
You make a grown man cry,
you make a grown man cry
(Rolling Stones)
This section explains what goes on when a Linux system is brought up and taken down, and how it should be done properly. If proper procedures are not followed, files might be corrupted or lost.
8.1. An overview of boots and shutdowns
The act of turning on a computer system and causing its operating system to be loaded is called booting. The name comes from an image of the computer pulling itself up from its bootstraps, but the act itself slightly more realistic.
During bootstrapping, the computer first loads a small piece of code called the bootstrap loader, which in turn loads and starts the operating system. The bootstrap loader is usually stored in a fixed location on a hard disk or a floppy. The reason for this two step process is that the operating system is big and complicated, but the first piece of code that the computer loads must be very small (a few hundred bytes), to avoid making the firmware unnecessarily complicated.
Different computers do the bootstrapping differently. For PCs, the computer (its BIOS) reads in the first sector (called the boot sector) of a floppy or hard disk. The bootstrap loader is contained within this sector. It loads the operating system from elsewhere on the disk (or from some other place).
After Linux has been loaded, it initializes the hardware and device drivers, and then runs init. init starts other processes to allow users to log in, and do things. The details of this part will be discussed below.
In order to shut down a Linux system, first all processes are told to terminate (this makes them close any files and do other necessary things to keep things tidy), then filesystems and swap areas are unmounted, and finally a message is printed to the console that the power can be turned off. If the proper procedure is not followed, terrible things can and will happen; most importantly, the filesystem buffer cache might not be flushed, which means that all data in it is lost and the filesystem on disk is inconsistent, and therefore possibly unusable.
8.2. The boot process in closer look
When a PC is booted, the BIOS will do various tests to check that everything looks all right, and will then start the actual booting. This process is called the power on self test , or POST for short. It will choose a disk drive (typically the first floppy drive, if there is a floppy inserted, otherwise the first hard disk, if one is installed in the computer; the order might be configurable, however) and will then read its very first sector. This is called the boot sector; for a hard disk, it is also called the master boot record, since a hard disk can contain several partitions, each with their own boot sectors.
The boot sector contains a small program (small enough to fit into one sector) whose responsibility is to read the actual operating system from the disk and start it. When booting Linux from a floppy disk, the boot sector contains code that just reads the first few hundred blocks (depending on the actual kernel size, of course) to a predetermined place in memory. On a Linux boot floppy, there is no filesystem, the kernel is just stored in consecutive sectors, since this simplifies the boot process. It is possible, however, to boot from a floppy with a filesystem, by using LILO, the LInux LOader, or GRUB, the GRand Unifying Bootloader.
When booting from the hard disk, the code in the master boot record will examine the partition table (also in the master boot record), identify the active partition (the partition that is marked to be bootable), read the boot sector from that partition, and then start the code in that boot sector. The code in the partition's boot sector does what a floppy disk's boot sector does: it will read in the kernel from the partition and start it. The details vary, however, since it is generally not useful to have a separate partition for just the kernel image, so the code in the partition's boot sector can't just read the disk in sequential order, it has to find the sectors wherever the filesystem has put them. There are several ways around this problem, but the most common way is to use a boot loader like LILO or GRUB. (The details about how to do this are irrelevant for this discussion, however; see the LILO or GRUB documentation for more information; it is most thorough.)
When booting, the bootloader will normally go right ahead and read in and boot the default kernel. It is also possible to configure the boot loader to be able to boot one of several kernels, or even other operating systems than Linux, and it is possible for the user to choose which kernel or operating system is to be booted at boot time. LILO, for example, can be configured so that if one holds down the alt, shift, or ctrl key at boot time (when LILO is loaded), LILO will ask what is to be booted and not boot the default right away. Alternatively, the bootloader can be configured so that it will always ask, with an optional timeout that will cause the default kernel to be booted.
It is also possible to give a kernel command line argument, after the name of the kernel or operating system. For a list of possible options you can read http://www.tldp.org/HOWTO/BootPrompt-HOWTO.html.
Booting from floppy and from hard disk have both their advantages, but generally booting from the hard disk is nicer, since it avoids the hassle of playing around with floppies. It is also faster. Most Linux distributions will setup the bootloader for you during the install process.
After the Linux kernel has been read into the memory, by whatever means, and is started for real, roughly the following things happen:
The Linux kernel is installed compressed, so it will first uncompress itself. The beginning of the kernel image contains a small program that does this.
If you have a super-VGA card that Linux recognizes and that has some special text modes (such as 100 columns by 40 rows), Linux asks you which mode you want to use. During the kernel compilation, it is possible to preset a video mode, so that this is never asked. This can also be done with LILO, GRUB or rdev.
After this, the kernel checks what other hardware there is (hard disks, floppies, network adapters, etc), and configures some of its device drivers appropriately; while it does this, it outputs messages about its findings. For example, when I boot, I it looks like this:
The exact texts are different on different systems, depending on the hardware, the version of Linux being used, and how it has been configured.LILO boot: Loading linux. Console: colour EGA+ 80x25, 8 virtual consoles Serial driver version 3.94 with no serial options enabled tty00 at 0x03f8 (irq = 4) is a 16450 tty01 at 0x02f8 (irq = 3) is a 16450 lp_init: lp1 exists (0), using polling driver Memory: 7332k/8192k available (300k kernel code, 384k reserved, 176k data) Floppy drive(s): fd0 is 1.44M, fd1 is 1.2M Loopback device init Warning WD8013 board not found at i/o = 280. Math coprocessor using irq13 error reporting. Partition check: hda: hda1 hda2 hda3 VFS: Mounted root (ext filesystem). Linux version 0.99.pl9-1 (root@haven) 05/01/93 14:12:20
Then the kernel will try to mount the root filesystem. The place is configurable at compilation time, or any time with rdev or the bootloader. The filesystem type is detected automatically. If the mounting of the root filesystem fails, for example because you didn't remember to include the corresponding filesystem driver in the kernel, the kernel panics and halts the system (there isn't much it can do, anyway).
The root filesystem is usually mounted read-only (this can be set in the same way as the place). This makes it possible to check the filesystem while it is mounted; it is not a good idea to check a filesystem that is mounted read-write.
After this, the kernel starts the program init (located in /sbin/init) in the background (this will always become process number 1). init does various startup chores. The exact things it does depends on how it is configured; see Section 2.3.1 for more information (not yet written). It will at least start some essential background daemons.
init then switches to multi-user mode, and starts a getty for virtual consoles and serial lines. getty is the program which lets people log in via virtual consoles and serial terminals. init may also start some other programs, depending on how it is configured.
After this, the boot is complete, and the system is up and running normally.
8.2.1. A Word About Bootloaders
TO BE ADDED
This section will give an overview of the difference between GRUB and LILO.
For more information on LILO, you can read http://www.tldp.org/HOWTO/LILO.html
For more information on GRUB, you can visit http://www.gnu.org/software/grub/grub.html
8.3. More about shutdowns
It is important to follow the correct procedures when you shut down a Linux system. If you fail do so, your filesystems probably will become trashed and the files probably will become scrambled. This is because Linux has a disk cache that won't write things to disk at once, but only at intervals. This greatly improves performance but also means that if you just turn off the power at a whim the cache may hold a lot of data and that what is on the disk may not be a fully working filesystem (because only some things have been written to the disk).
Another reason against just flipping the power switch is that in a multi-tasking system there can be lots of things going on in the background, and shutting the power can be quite disastrous. By using the proper shutdown sequence, you ensure that all background processes can save their data.
The command for properly shutting down a Linux system is shutdown. It is usually used in one of two ways.
If you are running a system where you are the only user, the usual way of using shutdown is to quit all running programs, log out on all virtual consoles, log in as root on one of them (or stay logged in as root if you already are, but you should change to root's home directory or the root directory, to avoid problems with unmounting), then give the command shutdown -h now (substitute now with a plus sign and a number in minutes if you want a delay, though you usually don't on a single user system).
Alternatively, if your system has many users, use the command shutdown -h +time message, where time is the time in minutes until the system is halted, and message is a short explanation of why the system is shutting down.
# shutdown -h +10 'We will install a new disk. System should > be back on-line in three hours.' # |
Broadcast message from root (ttyp0) Wed Aug 2 01:03:25 1995... We will install a new disk. System should be back on-line in three hours. The system is going DOWN for system halt in 10 minutes !! |
When the real shutting down starts after any delays, all filesystems (except the root one) are unmounted, user processes (if anybody is still logged in) are killed, daemons are shut down, all filesystem are unmounted, and generally everything settles down. When that is done, init prints out a message that you can power down the machine. Then, and only then, should you move your fingers towards the power switch.
Sometimes, although rarely on any good system, it is impossible to shut down properly. For instance, if the kernel panics and crashes and burns and generally misbehaves, it might be completely impossible to give any new commands, hence shutting down properly is somewhat difficult, and just about everything you can do is hope that nothing has been too severely damaged and turn off the power. If the troubles are a bit less severe (say, somebody hit your keyboard with an axe), and the kernel and the update program still run normally, it is probably a good idea to wait a couple of minutes to give update a chance to flush the buffer cache, and only cut the power after that.
In the old days, some people like to shut down using the command sync three times, waiting for the disk I/O to stop, then turn off the power. If there are no running programs, this is equivalent to using shutdown. However, it does not unmount any filesystems and this can lead to problems with the ext2fs ``clean filesystem'' flag. The triple-sync method is not recommended.
(In case you're wondering: the reason for three syncs is that in the early days of UNIX, when the commands were typed separately, that usually gave sufficient time for most disk I/O to be finished.)
8.4. Rebooting
Rebooting means booting the system again. This can be accomplished by first shutting it down completely, turning power off, and then turning it back on. A simpler way is to ask shutdown to reboot the system, instead of merely halting it. This is accomplished by using the -r option to shutdown, for example, by giving the command shutdown -r now.
Most Linux systems run shutdown -r now when ctrl-alt-del is pressed on the keyboard. This reboots the system. The action on ctrl-alt-del is configurable, however, and it might be better to allow for some delay before the reboot on a multiuser machine. Systems that are physically accessible to anyone might even be configured to do nothing when ctrl-alt-del is pressed.
8.5. Single user mode
The shutdown command can also be used to bring the system down to single user mode, in which no one can log in, but root can use the console. This is useful for system administration tasks that can't be done while the system is running normally.
8.6. Emergency boot floppies
It is not always possible to boot a computer from the hard disk. For example, if you make a mistake in configuring LILO, you might make your system unbootable. For these situations, you need an alternative way of booting that will always work (as long as the hardware works). For typical PCs, this means booting from the floppy drive.
Most Linux distributions allow one to create an emergency boot floppy during installation. It is a good idea to do this. However, some such boot disks contain only the kernel, and assume you will be using the programs on the distribution's installation disks to fix whatever problem you have. Sometimes those programs aren't enough; for example, you might have to restore some files from backups made with software not on the installation disks.
Thus, it might be necessary to create a custom root floppy as well. The Bootdisk HOWTO by Graham Chapman contains instructions for doing this. You can find this HOWTO at http://www.tldp.org/HOWTO/Bootdisk-HOWTO/index.html. You must, of course, remember to keep your emergency boot and root floppies up to date.
You can't use the floppy drive you use to mount the root floppy for anything else. This can be inconvenient if you only have one floppy drive. However, if you have enough memory, you can configure your boot floppy to load the root disk to a ramdisk (the boot floppy's kernel needs to be specially configured for this). Once the root floppy has been loaded into the ramdisk, the floppy drive is free to mount other disks.
Chapter 9. init
"Uuno on numero yksi" (Slogan for a series of Finnish movies.)
This chapter describes the init process, which is the first user level process started by the kernel. init has many important duties, such as starting getty (so that users can log in), implementing run levels, and taking care of orphaned processes. This chapter explains how init is configured and how you can make use of the different run levels.
9.1. init comes first
init is one of those programs that are absolutely essential to the operation of a Linux system, but that you still can mostly ignore. A good Linux distribution will come with a configuration for init that will work for most systems, and on these systems there is nothing you need to do about init. Usually, you only need to worry about init if you hook up serial terminals, dial-in (not dial-out) modems, or if you want to change the default run level.
When the kernel has started itself (has been loaded into memory, has started running, and has initialized all device drivers and data structures and such), it finishes its own part of the boot process by starting a user level program, init. Thus, init is always the first process (its process number is always 1).
The kernel looks for init in a few locations that have been historically used for it, but the proper location for it (on a Linux system) is /sbin/init. If the kernel can't find init, it tries to run /bin/sh, and if that also fails, the startup of the system fails.
When init starts, it finishes the boot process by doing a number of administrative tasks, such as checking filesystems, cleaning up /tmp, starting various services, and starting a getty for each terminal and virtual console where users should be able to log in (see Chapter 10).
After the system is properly up, init restarts getty for each terminal after a user has logged out (so that the next user can log in). init also adopts orphan processes: when a process starts a child process and dies before its child, the child immediately becomes a child of init. This is important for various technical reasons, but it is good to know it, since it makes it easier to understand process lists and process tree graphs. There are a few variants of init available. Most Linux distributions use sysvinit (written by Miquel van Smoorenburg), which is based on the System V init design. The BSD versions of Unix have a different init. The primary difference is run levels: System V has them, BSD does not (at least traditionally). This difference is not essential. We'll look at sysvinit only.
9.2. Configuring init to start getty: the /etc/inittab file
When it starts up, init reads the /etc/inittab configuration file. While the system is running, it will re-read it, if sent the HUP signal (kill -HUP 1); this feature makes it unnecessary to boot the system to make changes to the init configuration take effect.
The /etc/inittab file is a bit complicated. We'll start with the simple case of configuring getty lines. Lines in /etc/inittab consist of four colon-delimited fields:
id:runlevels:action:process |
- id
This identifies the line in the file. For getty lines, it specifies the terminal it runs on (the characters after /dev/tty in the device file name). For other lines, it doesn't matter (except for length restrictions), but it should be unique.
- runlevels
The run levels the line should be considered for. The run levels are given as single digits, without delimiters. (Run levels are described in the next section.)
- action
What action should be taken by the line, e.g., respawn to run the command in the next field again, when it exits, or once to run it just once.
- process
The command to run.
1:2345:respawn:/sbin/getty 9600 tty1 |
Different versions of getty are run differently. Consult your manual page, and make sure it is the correct manual page.
If you wanted to add terminals or dial-in modem lines to a system, you'd add more lines to /etc/inittab, one for each terminal or dial-in line. For more details, see the manual pages init, inittab, and getty.
If a command fails when it starts, and init is configured to restart it, it will use a lot of system resources: init starts it, it fails, init starts it, it fails, init starts it, it fails, and so on, ad infinitum. To prevent this, init will keep track of how often it restarts a command, and if the frequency grows to high, it will delay for five minutes before restarting again.
9.3. Run levels
A run level is a state of init and the whole system that defines what system services are operating. Run levels are identified by numbers. Some system administrators use run levels to define which subsystems are working, e.g., whether X is running, whether the network is operational, and so on. Others have all subsystems always running or start and stop them individually, without changing run levels, since run levels are too coarse for controlling their systems. You need to decide for yourself, but it might be easiest to follow the way your Linux distribution does things.
The following table defines how most Linux Distributions define the different run levels. However, run-levels 2 through 5 can be modified to suit your own tastes.
Table 9-1. Run level numbers
| 0 | Halt the system. |
| 1 | Single-user mode (for special administration). |
| 2 | Local Multiuser with Networking but without network service (like NFS) |
| 3 | Full Multiuser with Networking |
| 4 | Not Used |
| 5 | Full Multiuser with Networking and X Windows(GUI) |
| 6 | Reboot. |
Services that get started at a certain runtime are determined by the contents of the various rcN.d directories. Most distributions locate these directories either at /etc/init.d/rcN.d or /etc/rcN.d. (Replace the N with the run-level number.)
In each run-level you will find a series of if links pointing to start-up scripts located in /etc/init.d. The names of these links all start as either K or S, followed by a number. If the name of the link starts with an S, then that indicates the service will be started when you go into that run level. If the name of the link starts with a K, the service will be killed (if running).
The number following the K or S indicates the order the scripts will be run. Here is a sample of what an /etc/init.d/rc3.d may look like.
# ls -l /etc/init.d/rc3.d lrwxrwxrwx 1 root root 10 2004-11-29 22:09 K12nfsboot -> ../nfsboot lrwxrwxrwx 1 root root 6 2005-03-29 13:42 K15xdm -> ../xdm lrwxrwxrwx 1 root root 9 2004-11-29 22:08 S01pcmcia -> ../pcmcia lrwxrwxrwx 1 root root 9 2004-11-29 22:06 S01random -> ../random lrwxrwxrwx 1 root root 11 2005-03-01 11:56 S02firewall -> ../firewall lrwxrwxrwx 1 root root 10 2004-11-29 22:34 S05network -> ../network lrwxrwxrwx 1 root root 9 2004-11-29 22:07 S06syslog -> ../syslog lrwxrwxrwx 1 root root 10 2004-11-29 22:09 S08portmap -> ../portmap lrwxrwxrwx 1 root root 9 2004-11-29 22:07 S08resmgr -> ../resmgr lrwxrwxrwx 1 root root 6 2004-11-29 22:09 S10nfs -> ../nfs lrwxrwxrwx 1 root root 12 2004-11-29 22:40 S12alsasound -> ../alsasound lrwxrwxrwx 1 root root 8 2004-11-29 22:09 S12fbset -> ../fbset lrwxrwxrwx 1 root root 7 2004-11-29 22:10 S12sshd -> ../sshd lrwxrwxrwx 1 root root 8 2005-02-01 09:24 S12xntpd -> ../xntpd lrwxrwxrwx 1 root root 7 2004-12-02 20:34 S13cups -> ../cups lrwxrwxrwx 1 root root 6 2004-11-29 22:09 S13kbd -> ../kbd lrwxrwxrwx 1 root root 13 2004-11-29 22:10 S13powersaved -> ../powersaved lrwxrwxrwx 1 root root 9 2004-11-29 22:09 S14hwscan -> ../hwscan lrwxrwxrwx 1 root root 7 2004-11-29 22:10 S14nscd -> ../nscd lrwxrwxrwx 1 root root 10 2004-11-29 22:10 S14postfix -> ../postfix lrwxrwxrwx 1 root root 6 2005-02-04 13:27 S14smb -> ../smb lrwxrwxrwx 1 root root 7 2004-11-29 22:10 S15cron -> ../cron lrwxrwxrwx 1 root root 8 2004-12-22 20:35 S15smbfs -> ../smbfs |
How run levels start are configured in /etc/inittab by lines like the following:
l2:2:wait:/etc/init.d/rc 2 |
The command in the fourth field does all the hard work of setting up a run level. It starts services that aren't already running, and stops services that shouldn't be running in the new run level any more. Exactly what the command is, and how run levels are configured, depends on the Linux distribution.
When init starts, it looks for a line in /etc/inittab that specifies the default run level:
id:2:initdefault: |
While the system is running, the telinit command can change the run level. When the run level is changed, init runs the relevant command from /etc/inittab.
9.4. Special configuration in /etc/inittab
The /etc/inittab has some special features that allow init to react to special circumstances. These special features are marked by special keywords in the third field. Some examples:
- powerwait
Allows init to shut the system down, when the power fails. This assumes the use of a UPS, and software that watches the UPS and informs init that the power is off.
- ctrlaltdel
Allows init to reboot the system, when the user presses ctrl-alt-del on the console keyboard. Note that the system administrator can configure the reaction to ctrl-alt-del to be something else instead, e.g., to be ignored, if the system is in a public location. (Or to start nethack.)
- sysinit
Command to be run when the system is booted. This command usually cleans up /tmp, for example.
9.5. Booting in single user mode
An important run level is single user mode (run level 1), in which only the system administrator is using the machine and as few system services, including logins, as possible are running. Single user mode is necessary for a few administrative tasks, such as running fsck on a /usr partition, since this requires that the partition be unmounted, and that can't happen, unless just about all system services are killed.
A running system can be taken to single user mode by using telinit to request run level 1. At bootup, it can be entered by giving the word single or emergency on the kernel command line: the kernel gives the command line to init as well, and init understands from that word that it shouldn't use the default run level. (The kernel command line is entered in a way that depends on how you boot the system.)
Booting into single user mode is sometimes necessary so that one can run fsck by hand, before anything mounts or otherwise touches a broken /usr partition (any activity on a broken filesystem is likely to break it more, so fsck should be run as soon as possible).
The bootup scripts init runs will automatically enter single user mode, if the automatic fsck at bootup fails. This is an attempt to prevent the system from using a filesystem that is so broken that fsck can't fix it automatically. Such breakage is relatively rare, and usually involves a broken hard disk or an experimental kernel release, but it's good to be prepared.
As a security measure, a properly configured system will ask for the root password before starting the shell in single user mode. Otherwise, it would be simple to just enter a suitable line to LILO to get in as root. (This will break if /etc/passwd has been broken by filesystem problems, of course, and in that case you'd better have a boot floppy handy.)
Chapter 10. Logging In And Out
"I don't care to belong to a club that accepts people like me as a member." (Groucho Marx)
This section describes what happens when a user logs in or out. The various interactions of background processes, log files, configuration files, and so on are described in some detail.
10.1. Logins via terminals
Section 2.3.2 shows how logins happen via terminals. First, init makes sure there is a getty program for the terminal connection (or console). getty listens at the terminal and waits for the user to notify that he is ready to login in (this usually means that the user must type something). When it notices a user, getty outputs a welcome message (stored in /etc/issue), and prompts for the username, and finally runs the login program. login gets the username as a parameter, and prompts the user for the password. If these match, login starts the shell configured for the user; else it just exits and terminates the process (perhaps after giving the user another chance at entering the username and password). init notices that the process terminated, and starts a new getty for the terminal.
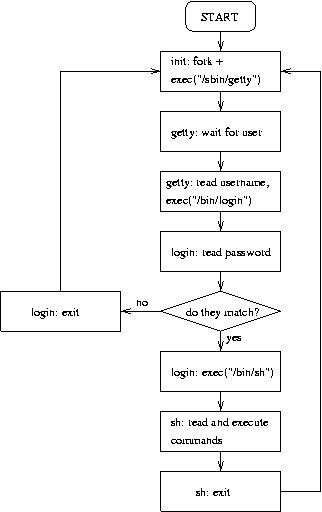
Note that the only new process is the one created by init (using the fork system call); getty and login only replace the program running in the process (using the exec system call).
A separate program, for noticing the user, is needed for serial lines, since it can be (and traditionally was) complicated to notice when a terminal becomes active. getty also adapts to the speed and other settings of the connection, which is important especially for dial-in connections, where these parameters may change from call to call.
There are several versions of getty and init in use, all with their good and bad points. It is a good idea to learn about the versions on your system, and also about the other versions (you could use the Linux Software Map to search them). If you don't have dial-ins, you probably don't have to worry about getty, but init is still important.
10.2. Logins via the network
Two computers in the same network are usually linked via a single physical cable. When they communicate over the network, the programs in each computer that take part in the communication are linked via a virtual connection, a sort of imaginary cable. As far as the programs at either end of the virtual connection are concerned, they have a monopoly on their own cable. However, since the cable is not real, only imaginary, the operating systems of both computers can have several virtual connections share the same physical cable. This way, using just a single cable, several programs can communicate without having to know of or care about the other communications. It is even possible to have several computers use the same cable; the virtual connections exist between two computers, and the other computers ignore those connections that they don't take part in.
That's a complicated and over-abstracted description of the reality. It might, however, be good enough to understand the important reason why network logins are somewhat different from normal logins. The virtual connections are established when there are two programs on different computers that wish to communicate. Since it is in principle possible to login from any computer in a network to any other computer, there is a huge number of potential virtual communications. Because of this, it is not practical to start a getty for each potential login.
There is a single process inetd (corresponding to getty) that handles all network logins. When it notices an incoming network login (i.e., it notices that it gets a new virtual connection to some other computer), it starts a new process to handle that single login. The original process remains and continues to listen for new logins.
To make things a bit more complicated, there is more than one communication protocol for network logins. The two most important ones are telnet and rlogin. In addition to logins, there are many other virtual connections that may be made (for FTP, Gopher, HTTP, and other network services). It would be ineffective to have a separate process listening for a particular type of connection, so instead there is only one listener that can recognize the type of the connection and can start the correct type of program to provide the service. This single listener is called inetd; see the Linux Network Administrators' Guide for more information.
10.3. What login does
The login program takes care of authenticating the user (making sure that the username and password match), and of setting up an initial environment for the user by setting permissions for the serial line and starting the shell.
Part of the initial setup is outputting the contents of the file /etc/motd (short for message of the day) and checking for electronic mail. These can be disabled by creating a file called .hushlogin in the user's home directory.
If the file /etc/nologin exists, logins are disabled. That file is typically created by shutdown and relatives. login checks for this file, and will refuse to accept a login if it exists. If it does exist, login outputs its contents to the terminal before it quits.
login logs all failed login attempts in a system log file (via syslog). It also logs all logins by root. Both of these can be useful when tracking down intruders.
Currently logged in people are listed in /var/run/utmp. This file is valid only until the system is next rebooted or shut down; it is cleared when the system is booted. It lists each user and the terminal (or network connection) he is using, along with some other useful information. The who, w, and other similar commands look in utmp to see who are logged in.
All successful logins are recorded into /var/log/wtmp. This file will grow without limit, so it must be cleaned regularly, for example by having a weekly cron job to clear it. The last command browses wtmp.
Both utmp and wtmp are in a binary format (see the utmp manual page); it is unfortunately not convenient to examine them without special programs.
10.5. Access control
The user database is traditionally contained in the /etc/passwd file. Some systems use shadow passwords, and have moved the passwords to /etc/shadow. Sites with many computers that share the accounts use NIS or some other method to store the user database; they might also automatically copy the database from one central location to all other computers.
The user database contains not only the passwords, but also some additional information about the users, such as their real names, home directories, and login shells. This other information needs to be public, so that anyone can read it. Therefore the password is stored encrypted. This does have the drawback that anyone with access to the encrypted password can use various cryptographic methods to guess it, without trying to actually log into the computer. Shadow passwords try to avoid this by moving the password into another file, which only root can read (the password is still stored encrypted). However, installing shadow passwords later onto a system that did not support them can be difficult.
With or without passwords, it is important to make sure that all passwords in a system are good, i.e., not easily guessed. The crack program can be used to crack passwords; any password it can find is by definition not a good one. While crack can be run by intruders, it can also be run by the system administrator to avoid bad passwords. Good passwords can also be enforced by the passwd program; this is in fact more effective in CPU cycles, since cracking passwords requires quite a lot of computation.
The user group database is kept in /etc/group; for systems with shadow passwords, there can be a /etc/shadow.group.
root usually can't login via most terminals or the network, only via terminals listed in the /etc/securetty file. This makes it necessary to get physical access to one of these terminals. It is, however, possible to log in via any terminal as any other user, and use the su command to become root.
10.6. Shell startup
When an interactive login shell starts, it automatically executes one or more pre-defined files. Different shells execute different files; see the documentation of each shell for further information.
Most shells first run some global file, for example, the Bourne shell (/bin/sh) and its derivatives execute /etc/profile; in addition, they execute .profile in the user's home directory. /etc/profile allows the system administrator to have set up a common user environment, especially by setting the PATH to include local command directories in addition to the normal ones. On the other hand, .profile allows the user to customize the environment to his own tastes by overriding, if necessary, the default environment.
Chapter 11. Managing user accounts
"The similarities of sysadmins and drug dealers: both measure stuff in Ks, and both have users." (Old, tired computer joke.)
This chapter explains how to create new user accounts, how to modify the properties of those accounts, and how to remove the accounts. Different Linux systems have different tools for doing this.
11.1. What's an account?
When a computer is used by many people it is usually necessary to differentiate between the users, for example, so that their private files can be kept private. This is important even if the computer can only be used by a single person at a time, as with most microcomputers. Thus, each user is given a unique username, and that name is used to log in.
There's more to a user than just a name, however. An account is all the files, resources, and information belonging to one user. The term hints at banks, and in a commercial system each account usually has some money attached to it, and that money vanishes at different speeds depending on how much the user stresses the system. For example, disk space might have a price per megabyte and day, and processing time might have a price per second.
11.2. Creating a user
The Linux kernel itself treats users are mere numbers. Each user is identified by a unique integer, the user id or uid, because numbers are faster and easier for a computer to process than textual names. A separate database outside the kernel assigns a textual name, the username, to each user id. The database contains additional information as well.
To create a user, you need to add information about the user to the user database, and create a home directory for him. It may also be necessary to educate the user, and set up a suitable initial environment for him.
Most Linux distributions come with a program for creating accounts. There are several such programs available. Two command line alternatives are adduser and useradd; there may be a GUI tool as well. Whatever the program, the result is that there is little if any manual work to be done. Even if the details are many and intricate, these programs make everything seem trivial. However, Section 11.2.4 describes how to do it by hand.
11.2.1. /etc/passwd and other informative files
The basic user database in a Unix system is the text file, /etc/passwd (called the password file), which lists all valid usernames and their associated information. The file has one line per username, and is divided into seven colon-delimited fields:
Username.
Previously this was where the user's password was stored.
Numeric user id.
Numeric group id.
Full name or other description of account.
Home directory.
Login shell (program to run at login).
Most Linux systems use shadow passwords. As mentioned, previously passwords were stored in the /etc/passwd file. This newer method of storing the password: the encrypted password is stored in a separate file, /etc/shadow, which only root can read. The /etc/passwd file only contains a special marker in the second field. Any program that needs to verify a user is setuid, and can therefore access the shadow password file. Normal programs, which only use the other fields in the password file, can't get at the password.
11.2.2. Picking numeric user and group ids
On most systems it doesn't matter what the numeric user and group ids are, but if you use the Network filesystem (NFS), you need to have the same uid and gid on all systems. This is because NFS also identifies users with the numeric uids. If you aren't using NFS, you can let your account creation tool pick them automatically.
If you are using NFS, you'll have to be invent a mechanism for synchronizing account information. One alternative is to the NIS system (see XXX network-admin-guide).
However, you should try to avoid re-using numeric uids (and textual usernames), because the new owner of the uid (or username) may get access to the old owner's files (or mail, or whatever).
11.2.3. Initial environment: /etc/skel
When the home directory for a new user is created, it is initialized with files from the /etc/skel directory. The system administrator can create files in /etc/skel that will provide a nice default environment for users. For example, he might create a /etc/skel/.profile that sets the EDITOR environment variable to some editor that is friendly towards new users.
However, it is usually best to try to keep /etc/skel as small as possible, since it will be next to impossible to update existing users' files. For example, if the name of the friendly editor changes, all existing users would have to edit their .profile. The system administrator could try to do it automatically, with a script, but that is almost certain going to break someone's file.
Whenever possible, it is better to put global configuration into global files, such as /etc/profile. This way it is possible to update it without breaking users' own setups.
11.2.4. Creating a user by hand
To create a new account manually, follow these steps:
Edit /etc/passwd with vipw and add a new line for the new account. Be careful with the syntax. Do not edit directly with an editor! vipw locks the file, so that other commands won't try to update it at the same time. You should make the password field be `*', so that it is impossible to log in.
Similarly, edit /etc/group with vigr, if you need to create a new group as well.
Create the home directory of the user with mkdir.
Copy the files from /etc/skel to the new home directory.
Fix ownerships and permissions with chown and chmod. The -R option is most useful. The correct permissions vary a little from one site to another, but usually the following commands do the right thing:
cd /home/newusername chown -R username.group . chmod -R go=u,go-w . chmod go= .
Set the password with passwd.
After you set the password in the last step, the account will work. You shouldn't set it until everything else has been done, otherwise the user may inadvertently log in while you're still copying the files.
It is sometimes necessary to create dummy accounts that are not used by people. For example, to set up an anonymous FTP server (so that anyone can download files from it, without having to get an account first), you need to create an account called ftp. In such cases, it is usually not necessary to set the password (last step above). Indeed, it is better not to, so that no-one can use the account, unless they first become root, since root can become any user.
11.3. Changing user properties
There are a few commands for changing various properties of an account (i.e., the relevant field in /etc/passwd):
- chfn
Change the full name field.
- chsh
Change the login shell.
- passwd
Change the password.
Other tasks need to be done by hand. For example, to change the username, you need to edit /etc/passwd directly (with vipw, remember). Likewise, to add or remove the user to more groups, you need to edit /etc/group (with vigr). Such tasks tend to be rare, however, and should be done with caution: for example, if you change the username, e-mail will no longer reach the user, unless you also create a mail alias.
11.4. Removing a user
To remove a user, you first remove all his files, mailboxes, mail aliases, print jobs, cron and at jobs, and all other references to the user. Then you remove the relevant lines from /etc/passwd and /etc/group (remember to remove the username from all groups it's been added to). It may be a good idea to first disable the account (see below), before you start removing stuff, to prevent the user from using the account while it is being removed.
Remember that users may have files outside their home directory. The find command can find them:
find / -user username |
Some Linux distributions come with special commands to do this; look for deluser or userdel. However, it is easy to do it by hand as well, and the commands might not do everything.
11.5. Disabling a user temporarily
It is sometimes necessary to temporarily disable an account, without removing it. For example, the user might not have paid his fees, or the system administrator may suspect that a cracker has got the password of that account.
The best way to disable an account is to change its shell into a special program that just prints a message. This way, whoever tries to log into the account, will fail, and will know why. The message can tell the user to contact the system administrator so that any problems may be dealt with.
It would also be possible to change the username or password to something else, but then the user won't know what is going on. Confused users mean more work.
A simple way to create the special programs is to write `tail scripts':
#!/usr/bin/tail +2 This account has been closed due to a security breach. Please call 555-1234 and wait for the men in black to arrive. |
If user billg is suspected of a security breach, the system administrator would do something like this:
# chsh -s /usr/local/lib/no-login/security billg # su - tester This account has been closed due to a security breach. Please call 555-1234 and wait for the men in black to arrive. # |
Tail scripts should be kept in a separate directory, so that their names don't interfere with normal user commands.
Chapter 12. Backups
Hardware is indeterministically reliable.
Software is deterministically unreliable.
People are indeterministically unreliable.
Nature is deterministically reliable.
This chapter explains about why, how, and when to make backups, and how to restore things from backups.
12.1. On the importance of being backed up
Your data is valuable. It will cost you time and effort re-create it, and that costs money or at least personal grief and tears; sometimes it can't even be re-created, e.g., if it is the results of some experiments. Since it is an investment, you should protect it and take steps to avoid losing it.
There are basically four reasons why you might lose data: hardware failures, software bugs, human action, or natural disasters. Although modern hardware tends to be quite reliable, it can still break seemingly spontaneously. The most critical piece of hardware for storing data is the hard disk, which relies on tiny magnetic fields remaining intact in a world filled with electromagnetic noise. Modern software doesn't even tend to be reliable; a rock solid program is an exception, not a rule. Humans are quite unreliable, they will either make a mistake, or they will be malicious and destroy data on purpose. Nature might not be evil, but it can wreak havoc even when being good. All in all, it is a small miracle that anything works at all.
Backups are a way to protect the investment in data. By having several copies of the data, it does not matter as much if one is destroyed (the cost is only that of the restoration of the lost data from the backup).
It is important to do backups properly. Like everything else that is related to the physical world, backups will fail sooner or later. Part of doing backups well is to make sure they work; you don't want to notice that your backups didn't work. Adding insult to injury, you might have a bad crash just as you're making the backup; if you have only one backup medium, it might destroyed as well, leaving you with the smoking ashes of hard work. Or you might notice, when trying to restore, that you forgot to back up something important, like the user database on a 15000 user site. Best of all, all your backups might be working perfectly, but the last known tape drive reading the kind of tapes you used was the one that now has a bucketful of water in it.
When it comes to backups, paranoia is in the job description.
12.2. Selecting the backup medium
The most important decision regarding backups is the choice of backup medium. You need to consider cost, reliability, speed, availability, and usability.
Cost is important, since you should preferably have several times more backup storage than what you need for the data. A cheap medium is usually a must.
Reliability is extremely important, since a broken backup can make a grown man cry. A backup medium must be able to hold data without corruption for years. The way you use the medium affects it reliability as a backup medium. A hard disk is typically very reliable, but as a backup medium it is not very reliable, if it is in the same computer as the disk you are backing up.
Speed is usually not very important, if backups can be done without interaction. It doesn't matter if a backup takes two hours, as long as it needs no supervision. On the other hand, if the backup can't be done when the computer would otherwise be idle, then speed is an issue.
Availability is obviously necessary, since you can't use a backup medium if it doesn't exist. Less obvious is the need for the medium to be available even in the future, and on computers other than your own. Otherwise you may not be able to restore your backups after a disaster.
Usability is a large factor in how often backups are made. The easier it is to make backups, the better. A backup medium mustn't be hard or boring to use.
The typical alternatives are floppies and tapes. Floppies are very cheap, fairly reliable, not very fast, very available, but not very usable for large amounts of data. Tapes are cheap to somewhat expensive, fairly reliable, fairly fast, quite available, and, depending on the size of the tape, quite comfortable.
There are other alternatives. They are usually not very good on availability, but if that is not a problem, they can be better in other ways. For example, magneto-optical disks can have good sides of both floppies (they're random access, making restoration of a single file quick) and tapes (contain a lot of data).
12.3. Selecting the backup tool
There are many tools that can be used to make backups. The traditional UNIX tools used for backups are tar, cpio, and dump. In addition, there are large number of third party packages (both freeware and commercial) that can be used. The choice of backup medium can affect the choice of tool.
tar and cpio are similar, and mostly equivalent from a backup point of view. Both are capable of storing files on tapes, and retrieving files from them. Both are capable of using almost any media, since the kernel device drivers take care of the low level device handling and the devices all tend to look alike to user level programs. Some UNIX versions of tar and cpio may have problems with unusual files (symbolic links, device files, files with very long pathnames, and so on), but the Linux versions should handle all files correctly.
dump is different in that it reads the filesystem directly and not via the filesystem. It is also written specifically for backups; tar and cpio are really for archiving files, although they work for backups as well.
Reading the filesystem directly has some advantages. It makes it possible to back files up without affecting their time stamps; for tar and cpio, you would have to mount the filesystem read-only first. Directly reading the filesystem is also more effective, if everything needs to be backed up, since it can be done with much less disk head movement. The major disadvantage is that it makes the backup program specific to one filesystem type; the Linux dump program understands the ext2 filesystem only.
dump also directly supports backup levels (which we'll be discussing below); with tar and cpio this has to be implemented with other tools.
A comparison of the third party backup tools is beyond the scope of this book. The Linux Software Map lists many of the freeware ones.
12.4. Simple backups
A simple backup scheme is to back up everything once, then back up everything that has been modified since the previous backup. The first backup is called a full backup, the subsequent ones are incremental backups. A full backup is often more laborious than incremental ones, since there is more data to write to the tape and a full backup might not fit onto one tape (or floppy). Restoring from incremental backups can be many times more work than from a full one. Restoration can be optimized so that you always back up everything since the previous full backup; this way, backups are a bit more work, but there should never be a need to restore more than a full backup and an incremental backup.
If you want to make backups every day and have six tapes, you could use tape 1 for the first full backup (say, on a Friday), and tapes 2 to 5 for the incremental backups (Monday through Thursday). Then you make a new full backup on tape 6 (second Friday), and start doing incremental ones with tapes 2 to 5 again. You don't want to overwrite tape 1 until you've got a new full backup, lest something happens while you're making the full backup. After you've made a full backup to tape 6, you want to keep tape 1 somewhere else, so that when your other backup tapes are destroyed in the fire, you still have at least something left. When you need to make the next full backup, you fetch tape 1 and leave tape 6 in its place.
If you have more than six tapes, you can use the extra ones for full backups. Each time you make a full backup, you use the oldest tape. This way you can have full backups from several previous weeks, which is good if you want to find an old, now deleted file, or an old version of a file.
12.4.1. Making backups with tar
A full backup can easily be made with tar:
# tar --create --file /dev/ftape /usr/src tar: Removing leading / from absolute path names in the archive # |
If your backup doesn't fit on one tape, you need to use the --multi-volume (-M) option:
# tar -cMf /dev/fd0H1440 /usr/src tar: Removing leading / from absolute path names in the archive Prepare volume #2 for /dev/fd0H1440 and hit return: # |
After you've made a backup, you should check that it is OK, using the --compare (-d) option:
# tar --compare --verbose -f /dev/ftape usr/src/ usr/src/linux usr/src/linux-1.2.10-includes/ .... # |
An incremental backup can be done with tar using the --newer (-N) option:
# tar --create --newer '8 Sep 1995' --file /dev/ftape /usr/src --verbose tar: Removing leading / from absolute path names in the archive usr/src/ usr/src/linux-1.2.10-includes/ usr/src/linux-1.2.10-includes/include/ usr/src/linux-1.2.10-includes/include/linux/ usr/src/linux-1.2.10-includes/include/linux/modules/ usr/src/linux-1.2.10-includes/include/asm-generic/ usr/src/linux-1.2.10-includes/include/asm-i386/ usr/src/linux-1.2.10-includes/include/asm-mips/ usr/src/linux-1.2.10-includes/include/asm-alpha/ usr/src/linux-1.2.10-includes/include/asm-m68k/ usr/src/linux-1.2.10-includes/include/asm-sparc/ usr/src/patch-1.2.11.gz # |
12.4.2. Restoring files with tar
The --extract (-x) option for tar extracts files:
# tar --extract --same-permissions --verbose --file /dev/fd0H1440 usr/src/ usr/src/linux usr/src/linux-1.2.10-includes/ usr/src/linux-1.2.10-includes/include/ usr/src/linux-1.2.10-includes/include/linux/ usr/src/linux-1.2.10-includes/include/linux/hdreg.h usr/src/linux-1.2.10-includes/include/linux/kernel.h ... # |
# tar xpvf /dev/fd0H1440 usr/src/linux-1.2.10-includes/include/linux/hdreg.h usr/src/linux-1.2.10-includes/include/linux/hdreg.h # |
# tar --list --file /dev/fd0H1440 usr/src/ usr/src/linux usr/src/linux-1.2.10-includes/ usr/src/linux-1.2.10-includes/include/ usr/src/linux-1.2.10-includes/include/linux/ usr/src/linux-1.2.10-includes/include/linux/hdreg.h usr/src/linux-1.2.10-includes/include/linux/kernel.h ... # |
tar doesn't handle deleted files properly. If you need to restore a filesystem from a full and an incremental backup, and you have deleted a file between the two backups, it will exist again after you have done the restore. This can be a big problem, if the file has sensitive data that should no longer be available.
12.5. Multilevel backups
The simple backup method outlined in the previous section is often quite adequate for personal use or small sites. For more heavy duty use, multilevel backups are more appropriate.
The simple method has two backup levels: full and incremental backups. This can be generalized to any number of levels. A full backup would be level 0, and the different levels of incremental backups levels 1, 2, 3, etc. At each incremental backup level you back up everything that has changed since the previous backup at the same or a previous level.
The purpose for doing this is that it allows a longer backup history cheaply. In the example in the previous section, the backup history went back to the previous full backup. This could be extended by having more tapes, but only a week per new tape, which might be too expensive. A longer backup history is useful, since deleted or corrupted files are often not noticed for a long time. Even a version of a file that is not very up to date is better than no file at all.
With multiple levels the backup history can be extended more cheaply. For example, if we buy ten tapes, we could use tapes 1 and 2 for monthly backups (first Friday each month), tapes 3 to 6 for weekly backups (other Fridays; note that there can be five Fridays in one month, so we need four more tapes), and tapes 7 to 10 for daily backups (Monday to Thursday). With only four more tapes, we've been able to extend the backup history from two weeks (after all daily tapes have been used) to two months. It is true that we can't restore every version of each file during those two months, but what we can restore is often good enough.
Figure 12-1 shows which backup level is used each day, and which backups can be restored from at the end of the month.
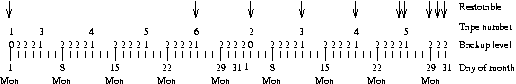
Backup levels can also be used to keep filesystem restoration time to a minimum. If you have many incremental backups with monotonously growing level numbers, you need to restore all of them if you need to rebuild the whole filesystem. Instead you can use level numbers that aren't monotonous, and keep down the number of backups to restore.
To minimize the number of tapes needed to restore, you could use a smaller level for each incremental tape. However, then the time to make the backups increases (each backup copies everything since the previous full backup). A better scheme is suggested by the dump manual page and described by the table XX (efficient-backup-levels). Use the following succession of backup levels: 3, 2, 5, 4, 7, 6, 9, 8, 9, etc. This keeps both the backup and restore times low. The most you have to backup is two day's worth of work. The number of tapes for a restore depends on how long you keep between full backups, but it is less than in the simple schemes.
Table 12-1. Efficient backup scheme using many backup levels
| Tape | Level | Backup (days) | Restore tapes |
|---|---|---|---|
| 1 | 0 | n/a | 1 |
| 2 | 3 | 1 | 1, 2 |
| 3 | 2 | 2 | 1, 3 |
| 4 | 5 | 1 | 1, 2, 4 |
| 5 | 4 | 2 | 1, 2, 5 |
| 6 | 7 | 1 | 1, 2, 5, 6 |
| 7 | 6 | 2 | 1, 2, 5, 7 |
| 8 | 9 | 1 | 1, 2, 5, 7, 8 |
| 9 | 8 | 2 | 1, 2, 5, 7, 9 |
| 10 | 9 | 1 | 1, 2, 5, 7, 9, 10 |
| 11 | 9 | 1 | 1, 2, 5, 7, 9, 10, 11 |
| ... | 9 | 1 | 1, 2, 5, 7, 9, 10, 11, ... |
A fancy scheme can reduce the amount of labor needed, but it does mean there are more things to keep track of. You must decide if it is worth it.
dump has built-in support for backup levels. For tar and cpio it must be implemented with shell scripts.
12.6. What to back up
You want to back up as much as possible. The major exception is software that can be easily reinstalled, but even they may have configuration files that it is important to back up, lest you need to do all the work to configure them all over again. Another major exception is the /proc filesystem; since that only contains data that the kernel always generates automatically, it is never a good idea to back it up. Especially the /proc/kcore file is unnecessary, since it is just an image of your current physical memory; it's pretty large as well.
Gray areas include the news spool, log files, and many other things in /var. You must decide what you consider important.
The obvious things to back up are user files (/home) and system configuration files (/etc, but possibly other things scattered all over the filesystem).
12.7. Compressed backups
Backups take a lot of space, which can cost quite a lot of money. To reduce the space needed, the backups can be compressed. There are several ways of doing this. Some programs have support for for compression built in; for example, the --gzip (-z) option for GNU tar pipes the whole backup through the gzip compression program, before writing it to the backup medium.
Unfortunately, compressed backups can cause trouble. Due to the nature of how compression works, if a single bit is wrong, all the rest of the compressed data will be unusable. Some backup programs have some built in error correction, but no method can handle a large number of errors. This means that if the backup is compressed the way GNU tar does it, with the whole output compressed as a unit, a single error makes all the rest of the backup lost. Backups must be reliable, and this method of compression is not a good idea.
An alternative way is to compress each file separately. This still means that the one file is lost, but all other files are unharmed. The lost file would have been corrupted anyway, so this situation is not much worse than not using compression at all. The afio program (a variant of cpio) can do this.
Compression takes some time, which may make the backup program unable to write data fast enough for a tape drive. This can be avoided by buffering the output (either internally, if the backup program if smart enough, or by using another program), but even that might not work well enough. This should only be a problem on slow computers.
Chapter 13. Task Automation --To Be Added
"Never put off until tomorrow what you can do the day after tomorrow.'Mark Twain'"
Basic discussion on scripting, cron & at - refer to other HOWTO's for details. Discuss non-crontab cron jobs such at those in the /etc directory.
Chapter 14. Keeping Time
"Time is an illusion. Lunchtime double so." (Douglas Adams.)
This chapter explains how a Linux system keeps time, and what you need to do to avoid causing trouble. Usually, you don't need to do anything about time, but it is good to understand it.
14.1. The concept of localtime
Time measurement is based on mostly regular natural phenomena, such as alternating light and dark periods caused by the rotation of the planet. The total time taken by two successive periods is constant, but the lengths of the light and dark period vary. One simple constant is noon.
Noon is the time of the day when the Sun is at its highest position. Since (according to recent research) the Earth is round, noon happens at different times in different places. This leads to the concept of local time. Humans measure time in many units, most of which are tied to natural phenomena like noon. As long as you stay in the same place, it doesn't matter that local times differ.
As soon as you need to communicate with distant places, you'll notice the need for a common time. In modern times, most of the places in the world communicate with most other places in the world, so a global standard for measuring time has been defined. This time is called universal time (UT or UTC, formerly known as Greenwich Mean Time or GMT, since it used to be local time in Greenwich, England). When people with different local times need to communicate, they can express times in universal time, so that there is no confusion about when things should happen.
Each local time is called a time zone. While geography would allow all places that have noon at the same time have the same time zone, politics makes it difficult. For various reasons, many countries use daylight savings time, that is, they move their clocks to have more natural light while they work, and then move the clocks back during winter. Other countries do not do this. Those that do, do not agree when the clocks should be moved, and they change the rules from year to year. This makes time zone conversions definitely non-trivial.
Time zones are best named by the location or by telling the difference between local and universal time. In the US and some other countries, the local time zones have a name and a three letter abbreviation. The abbreviations are not unique, however, and should not be used unless the country is also named. It is better to talk about the local time in, say, Helsinki, than about East European time, since not all countries in Eastern Europe follow the same rules.
Linux has a time zone package that knows about all existing time zones, and that can easily be updated when the rules change. All the system administrator needs to do is to select the appropriate time zone. Also, each user can set his own time zone; this is important since many people work with computers in different countries over the Internet. When the rules for daylight savings time change in your local time zone, make sure you'll upgrade at least that part of your Linux system. Other than setting the system time zone and upgrading the time zone data files, there is little need to bother about time.
14.2. The hardware and software clocks
A personal computer has a battery driven hardware clock. The battery ensures that the clock will work even if the rest of the computer is without electricity. The hardware clock can be set from the BIOS setup screen or from whatever operating system is running.
The Linux kernel keeps track of time independently from the hardware clock. During the boot, Linux sets its own clock to the same time as the hardware clock. After this, both clocks run independently. Linux maintains its own clock because looking at the hardware is slow and complicated.
The kernel clock always shows universal time. This way, the kernel does not need to know about time zones at all. The simplicity results in higher reliability and makes it easier to update the time zone information. Each process handles time zone conversions itself (using standard tools that are part of the time zone package).
The hardware clock can be in local time or in universal time. It is usually better to have it in universal time, because then you don't need to change the hardware clock when daylight savings time begins or ends (UTC does not have DST). Unfortunately, some PC operating systems, including MS-DOS, Windows, and OS/2, assume the hardware clock shows local time. Linux can handle either, but if the hardware clock shows local time, then it must be modified when daylight savings time begins or ends (otherwise it wouldn't show local time).
14.3. Showing and setting time
In Linux, the system time zone is determined by the symbolic link /etc/localtime. This link points to a time zone data file that describes the local time zone. The time zone data files are located at either /usr/lib/zoneinfo or /usr/share/zoneinfo depending on what distribution of Linux you use.
For example, on a SuSE system located in New Jersey the /etc/localtime link would point to /usr/share/zoneinfo/US/Eastern. On a Debian system the /etc/localtime link would point to /usr/lib/zoneinfo/US/Eastern.
If you fail to find the zoneinfo directory in either the /usr/lib or /usr/share directories, either do a find /usr -print | grep zoneinfo or consult your distribution's documentation.
What happens when you have a users located in a different timezone? A user can change his private time zone by setting the TZ environment variable. If it is unset, the system time zone is assumed. The syntax of the TZ variable is described in the tzset manual page.
The date command shows the current date and time. For example:
$ date Sun Jul 14 21:53:41 EET DST 1996 $ |
$ date -u Sun Jul 14 18:53:42 UTC 1996 $ |
# date 07142157 Sun Jul 14 21:57:00 EET DST 1996 # date Sun Jul 14 21:57:02 EET DST 1996 # |
Beware of the time command. This is not used to get the system time. Instead it's used to time how long something takes. Refer the the time man page.
date only shows or sets the software clock. The clock commands synchronizes the hardware and software clocks. It is used when the system boots, to read the hardware clock and set the software clock. If you need to set both clocks, you first set the software clock with date, and then the hardware clock with clock -w.
The -u option to clock tells it that the hardware clock is in universal time. You must use the -u option correctly. If you don't, your computer will be quite confused about what the time is.
The clocks should be changed with care. Many parts of a Unix system require the clocks to work correctly. For example, the cron daemon runs commands periodically. If you change the clock, it can be confused of whether it needs to run the commands or not. On one early Unix system, someone set the clock twenty years into the future, and cron wanted to run all the periodic commands for twenty years all at once. Current versions of cron can handle this correctly, but you should still be careful. Big jumps or backward jumps are more dangerous than smaller or forward ones.
14.4. When the clock is wrong
The Linux software clock is not always accurate. It is kept running by a periodic timer interrupt generated by PC hardware. If the system has too many processes running, it may take too long to service the timer interrupt, and the software clock starts slipping behind. The hardware clock runs independently and is usually more accurate. If you boot your computer often (as is the case for most systems that aren't servers), it will usually keep fairly accurate time.
If you need to adjust the hardware clock, it is usually simplest to reboot, go into the BIOS setup screen, and do it from there. This avoids all trouble that changing system time might cause. If doing it via BIOS is not an option, set the new time with date and clock (in that order), but be prepared to reboot, if some part of the system starts acting funny.
Another method would be to use either hwclock -w or hwclock --systohc to sync the hardware clock to the software clock. If you want to sync your software clock to your hardware clock then you would use hwclock -s or hwclock --hwtosys. For more information on this command read man hwclock.
14.5. NTP - Network Time Protocol
A networked computer (even if just over a modem) can check its own clock automatically by comparing it to the time on another computer known to keep accurate time. Network Time Protocol (or NTP) does exactly that. It is a method of verifying and correcting your computer's time by synchronizing it with a another system. With NTP your system's time can be maintained to within milliseconds of Coordinated Universal Time. Visit http://www.time.gov/about.html for more info.
For more casual Linux users, this is just a nice luxury. At my home all our clocks are set based upon what my Linux system says the time is. For larger organizations this "luxury" can become essential. Being able to search log files for events based upon time can make life a lot easier and take a lot of the "guess work" out of debugging.
Another example of how important NTP can be is with a SAN. Some SAN's require NTP be configured and running properly to allow for proper synchronization over filesystem usage, and proper timestamp control. Some SANs (and some applications) can become confused when dealing with files that have timestamps that are in the future.
Most Linux distributions come with a NTP package of some kind, either a .deb or .rpm package. You can use that to install NTP, or you can download the source files from http://www.ntp.org/downloads.html and compile it yourself. Either way, the basic configuration is the same.
14.6. Basic NTP configuration
The NTP program is configured using either the /etc/ntp.conf or /etc/xntp.conf file depending on what distribution of Linux you have. I won't go into too much detail on how to configure NTP. Instead I'll just cover the basics.
An example of a basic ntp.conf file would look like:
# --- GENERAL CONFIGURATION --- server aaa.bbb.ccc.ddd server 127.127.1.0 fudge 127.127.1.0 stratum 10 # Drift file. driftfile /etc/ntp/drift |
The most basic ntp.conf file will simply list 2 servers, one that it wishes to synchronize with, and a pseudo IP address for itself (in this case 127.127.1.0). The pseudo IP is used in case of network problems or if the remote NTP server goes down. NTP will synchronize against itself until the it can start synchronizing with the remote server again. It is recommended that you list at least 2 remote servers that you can synchronize against. One will act as a primary server and the other as a backup.
You should also list a location for a drift file. Over time NTP will "learn" the system clock's error rate and automatically adjust for it.
The restrict option can be used to provide better control and security over what NTP can do, and who can effect it. For example:
# Prohibit general access to this service. restrict default ignore # Permit systems on this network to synchronize with this # time service. But not modify our time. restrict aaa.bbb.ccc.ddd nomodify # Allow the following unrestricted access to ntpd restrict aaa.bbb.ccc.ddd restrict 127.0.0.1 |
NTP slowly corrects your systems time. Be patient! A simple test is to change your system clock by 10 minutes before you go to bed and then check it when you get up. The time should be correct.
Many people get the idea that instead of running the NTP daemon, they should just setup a cron job job to periodically run the ntpdate command. There are 2 main disadvantages of using using this method.
The first is that ntpdate does a "brute force" method of changing the time. So if your computer's time is off my 5 minutes, it immediately corrects it. In some environments, this can cause problems if time drastically changes. For example, if you are using time sensitive security software, you can inadvertently kill someones access. The NTP daemon slowly changes the time to avoid causing this kind of disruption.
The other reason is that the NTP daemon can be configured to try to learn your systems time drift and then automatically adjust for it.
14.7. NTP Toolkit
There are a number of utilities available to check if NTP is doing it's job. The ntpq -p command will print out your system's current time status.
# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
*cudns.cit.corne ntp0.usno.navy. 2 u 832 1024 377 43.208 0.361 2.646
LOCAL(0) LOCAL(0) 10 l 13 64 377 0.000 0.000 0.008 |
The ntpdc -c loopinfo will display how far off the system time is in seconds, based upon the last time the remote server was contacted.
# ntpdc -c loopinfo offset: -0.004479 s frequency: 133.625 ppm poll adjust: 30 watchdog timer: 404 s |
ntpdc -c kerninfo will display the current remaining correction.
# ntpdc -c kerninfo pll offset: -0.003917 s pll frequency: 133.625 ppm maximum error: 0.391414 s estimated error: 0.003676 s status: 0001 pll pll time constant: 6 precision: 1e-06 s frequency tolerance: 512 ppm pps frequency: 0.000 ppm pps stability: 512.000 ppm pps jitter: 0.0002 s calibration interval: 4 s calibration cycles: 0 jitter exceeded: 0 stability exceeded: 0 calibration errors: 0 |
A slightly more different version of ntpdc -c kerninfo is ntptime
# ntptime ntp_gettime() returns code 0 (OK) time c35e2cc7.879ba000 Thu, Nov 13 2003 11:16:07.529, (.529718), maximum error 425206 us, estimated error 3676 us ntp_adjtime() returns code 0 (OK) modes 0x0 (), offset -3854.000 us, frequency 133.625 ppm, interval 4 s, maximum error 425206 us, estimated error 3676 us, status 0x1 (PLL), time constant 6, precision 1.000 us, tolerance 512 ppm, pps frequency 0.000 ppm, stability 512.000 ppm, jitter 200.000 us, intervals 0, jitter exceeded 0, stability exceeded 0, errors 0. |
Yet another way to see how well NTP is working is with the ntpdate -d command. This will contact an NTP server and determine the time difference but not change your system's time.
# ntpdate -d 132.236.56.250
13 Nov 14:43:17 ntpdate[29631]: ntpdate 4.1.1c-rc1@1.836 Thu Feb 13 12:17:20 EST 2003 (1)
transmit(132.236.56.250)
receive(132.236.56.250)
transmit(132.236.56.250)
receive(132.236.56.250)
transmit(132.236.56.250)
receive(132.236.56.250)
transmit(132.236.56.250)
receive(132.236.56.250)
transmit(132.236.56.250)
server 132.236.56.250, port 123
stratum 2, precision -17, leap 00, trust 000
refid [192.5.41.209], delay 0.06372, dispersion 0.00044
transmitted 4, in filter 4
reference time: c35e5998.4a46cfc8 Thu, Nov 13 2003 14:27:20.290
originate timestamp: c35e5d55.d69a6f82 Thu, Nov 13 2003 14:43:17.838
transmit timestamp: c35e5d55.d16fc9bc Thu, Nov 13 2003 14:43:17.818
filter delay: 0.06522 0.06372 0.06442 0.06442
0.00000 0.00000 0.00000 0.00000
filter offset: 0.000036 0.001020 0.000527 0.000684
0.000000 0.000000 0.000000 0.000000
delay 0.06372, dispersion 0.00044
offset 0.001020
13 Nov 14:43:17 ntpdate[29631]: adjust time server 132.236.56.250 offset 0.001020 sec |
If you want actually watch the system synchronize you can use ntptrace.
# ntptrace 132.236.56.250 cudns.cit.cornell.edu: stratum 2, offset -0.003278, synch distance 0.02779 truetime.ntp.com: stratum 1, offset -0.014363, synch distance 0.00000, refid 'ACTS' |
If you need your system time synchronized immediately you can use the ntpdate remote-servername to force a synchronization. No waiting!
# ntpdate 132.236.56.250 13 Nov 14:56:28 ntpdate[29676]: adjust time server 132.236.56.250 offset -0.003151 sec |
14.8. Some known NTP servers
A list of public NTP servers can be obtained from: http://www.eecis.udel.edu/~mills/ntp/servers.html. Please read the usage information on the page prior so using a server. Not all servers have the available bandwidth to allow a large number of systems synchronizing against them. Therefore it is a good idea to contact a system's administrator prior to using his/her server for NTP services.
14.9. NTP Links
More detailed information on NTP can be obtained from the NTP homepage:http://www.ntp.org.
Chapter 16. System Updates --To Be Added
"A lie gets halfway around the world before the truth has a chance to get its pants on." Winston Churchill
Discussion on how and when to update the system.
Chapter 17. The Linux Kernel Source
"Black holes are where God divided by zero. " Steven Wright
BASIC info on the kernel source and compiling it. It will also provide some info on kdb debugger. Refer to other kernel HOWTO's for more info.
Chapter 18. Finding Help
"Help me if you can I'm feeling down. And I do appreciate you being 'round." - The Beatles
Help is out there. You just have to know where to look. With Linux there are an amazing number of places you can go. There are mailing lists, IRC channels, web pages with public forums, and many other resources available. This chapter will try to help you get the most out of your quest for help.
18.1. Newsgroups and Mailing Lists
This guide cannot teach you everything about Linux. There just isn't enough space. It is almost inevitable that at some point you will find something you need to do, that isn't covered in this (or any other) document at the LDP.
One of the nicest things about Linux is the large number of forums devoted to it. There are forums relating to almost all facets of Linux ranging from newbie FAQs to in depth kernel development issues. To receive the most from them, there are a few things you can do.
18.1.1. Finding The Right Forum
The first thing to do is to find an appropriate forum. There are many newsgroups and mailing lists devoted to Linux, so try to find and use the one which most closely matches your question. For example, there isn't much point in you asking a question about sendmail in a forum devoted to Linux kernel development. At best the people there will think you are stupid and you will get few responses, at worst you may receive lots of highly insulting replies (flames). A quick look through the newsgroups available finds comp.mail.sendmail, which looks like an appropriate place to ask a sendmail question. Your news client probably has a list of the newsgroups available to you, but if not then a full list of newsgroups is available at http://groups.google.com/groups?group=*.
18.1.2. Before You Post
Now that you have found your appropriate forum, you may think you are ready to post your question. Stop. You aren't ready yet. Have you already looked for the answer yourself? There are a huge number of HOWTOs and FAQs available, if any of them relate to the thing you are having a problem with then read them first. Even if they don't contain the answer to your problem, what they will do is give you a better understanding of the subject area, and that understanding will allow you to ask a more informed and sensible question. There are also archives of newsgroups and mailing lists and it is entirely possible that your question has been asked and answered previously. http://www.google.com or a similar search engine should be something you try before posting a question.
18.1.3. Writing Your Post
Okay, you have found your appropriate forum, you have read the relevant HOWTOs and FAQs, you have searched the web, but you still have not found the answer you need. Now you can start writing your post. It is always a good idea to make it clear that you already have read up on the subject by saying something like ``I have read the Winmodem-HOWTO and the PPP FAQ, but neither contained what I was looking for, searching for `Winmodem Linux PPP Setup' on google didn't return anything of use either''. This shows you to be someone who is willing to make an effort rather than a lazy idiot who requires spoonfeeding. The former is likely to receive help if anyone knows the answer, the latter is likely to meet with either stony silence or outright derision.
Write in clear, grammatical and correctly spelt English. This is incredibly important. It marks you as a precise and considered thinker. There are no such words as ``u'' or ``b4.'' Try to make yourself look like an educated and intelligent person rather than an idiot. It will help. I promise.
Similarly do not type in all capitals LIKE THIS. That is considered shouting and looks very rude.
Provide clear details stating what the problem is and what you have already tried to do to fix it. A question like ``My linux has stopped working, what can I do?'' is totally useless. Where has it stopped working? In what way has it stopped working? You need to be as precise as possible. There are limits however. Try not to include irrelevant information either. If you are having problems with your mail client it is unlikely that a dump of your kernel boot log (dmesg) would be of help.
Don't ask for replies by private email. The point of most Linux forums is that everybody can learn something from each other. Asking for private replies simply removes value from the newsgroup or mailing list.
18.1.4. Formatting Your Post
Do not post in HTML. Many Linux users have mail clients which can't easily read HTML email. Whilst with some effort, they can read HTML email, they usually don't. If you send them HTML mail it often gets deleted unread. Send plain text emails, they will reach a wider audience that way.
18.1.5. Follow Up
After your problem has been solved, post a short followup explaining what the problem was and how you solved it. People will appreciate this as it not only gives a sense of closure about the problem but also helps the next time someone has a similar question. When they look at the archives of the newsgroup or mailing list, they will see you had the same problem, the discussion that followed your question and your final solution.
18.1.6. More Information
This short guide is simply a paraphrase and summary of the excellent (and more detailed) document ``How To Ask Questions The Smart Way'' by Eric S Raymond. http://www.catb.org/~esr/faqs/smart-questions.html. It is recommend that you read it before you post anything. It will help you formulate your question to maximize your chances of getting the answer you are looking for.
18.2. IRC
IRC (Internet Relay Chat) is not covered in the Eric Raymond document, but IRC can also be an excellent way of finding the answers you need. However it does require some practice in asking questions in the right way. Most IRC networks have busy #linux channels and if the answer to your question is contained in the man pages, or in the HOWTOs then expect to be told to go read them. The rule about typing in clear and grammatical English still applies.
Most of what has been said about newsgroups and mailing lists is still relevant for IRC, with a the following additions
18.2.1. Colours
Do not use colours, bold, underline or strange (non ASCII) characters. This breaks some older terminals and is just plain ugly to look at. If you arrive in a channel and start spewing colour or bold then expect to be kicked out.
18.2.2. Be Polite
Remember you are not entitled to an answer. If you ask the question in the right way then you will probably get one, but you have no right to get one. The people in Linux IRC channels are all there on their own time, nobody is paying them, especially not you.
Be polite. Treat others as you would like to be treated. If you think people are not being polite to you then don't start calling them names or getting annoyed, become even politer. This makes them look foolish rather than dragging you down to their level.
Don't go slapping anyone with large trouts. Would you believe this has been done before once or twice? And that we it wasn't funny the first time?
18.2.3. Type Properly, in English
Most #linux channels are English channels. Speak English whilst in them. Most of the larger IRC networks also have #linux channel in other languages, for example the French language channel might be called #linuxfr, the Spanish one might be #linuxes or #linuxlatino. If you can't find the right channel then asking in the main #linux channel (preferably in English) should help you find the one you are looking for.
Do not type like a ``1337 H4X0R d00d!!!''. Even if other people are. It looks silly and thereby makes you look silly. At best you will only look like an idiot, at worst you will be derided then kicked out.
18.2.4. Port scanning
Never ever ask anyone to port scan you, or try to ``hack'' you. This is inviolable. There is no way of knowing that you are who you say you are, or that the IP that you are connected from belongs to you. Don't put people in the position where they have to say no to a request like this.
Don't ever port scan anyone, even if they ask you to. You have no way to tell that they are who they say they are or that the IP they are connected from is their own IP. In some jurisdictions port scanning may be illegal and it is certainly against the Terms of Service of most ISPs. Most people log TCP connections, they will notice they are being scanned. Most people will report you to your ISP for this (it is trivial to find out who that is).
18.2.5. Keep it in the Channel
Don't /msg anyone unless they ask you to. It diminishes the usefulness of the channel and some people just prefer that you not do it.
18.2.6. Stay On Topic
Stay on topic. The channel is a ``Linux'' channel, not a ``What Uncle Bob Got Up To Last Weekend'' channel. Even if you see other people being off topic, this does not mean that you should be. They are probably channel regulars and different conventions apply to them.
18.2.7. CTCPs
If you are thinking of mass CTCP pinging the channel or CTCP version or CTCP anything, then think again. It is liable to get you kicked out very quickly.
If you are not familiar with IRC, CTCP stands for Client To Client Protocol. It is a method whereby you can find out things about other peoples' clients. See the documentation for your IRC for more details.
18.2.8. Hacking, Cracking, Phreaking, Warezing
Don't ask about exploits, unless you are looking for a further way to be unceremoniously kicked out.
Don't be in hacker/cracker/phreaker/warezer channels whilst in a #linux channel. For some reason the people in charge of #linux channels seem to hate people who like causing destruction to people's machines or who like to steal software. Can't imagine why.
18.2.9. Round Up
Apologies if that seems like a lot of DON'Ts, and very few DOs. The DOs were already pretty much covered in the section on newsgroups and mailing lists.
Probably the best thing you can do is to go into a #linux channel, sit there and watch, getting the feel for a half hour before you say anything. This can help you to recognize the correct tone you should be using.
18.2.10. Further Reading
There are excellent FAQs about how to get the most of IRC #linux channels. Most #linux channels have an FAQ and/or set or channel rules. How to find this will usually be in the channel topic (which you can see at any time using the /topic command. Make sure you read the rules if there are any and follow them. One fairly generic set of rules and advice is the ``Undernet #linux FAQ'' which can be found at http://linuxfaq.quartz.net.nz .
Appendix A. GNU Free Documentation License
A.1. PREAMBLE
The purpose of this License is to make a manual, textbook, or other functional and useful document "free" in the sense of freedom: to assure everyone the effective freedom to copy and redistribute it, with or without modifying it, either commercially or noncommercially. Secondarily, this License preserves for the author and publisher a way to get credit for their work, while not being considered responsible for modifications made by others.
This License is a kind of "copyleft", which means that derivative works of the document must themselves be free in the same sense. It complements the GNU General Public License, which is a copyleft license designed for free software.
We have designed this License in order to use it for manuals for free software, because free software needs free documentation: a free program should come with manuals providing the same freedoms that the software does. But this License is not limited to software manuals; it can be used for any textual work, regardless of subject matter or whether it is published as a printed book. We recommend this License principally for works whose purpose is instruction or reference.
A.2. APPLICABILITY AND DEFINITIONS
This License applies to any manual or other work, in any medium, that contains a notice placed by the copyright holder saying it can be distributed under the terms of this License. Such a notice grants a world-wide, royalty-free license, unlimited in duration, to use that work under the conditions stated herein. The "Document", below, refers to any such manual or work. Any member of the public is a licensee, and is addressed as "you". You accept the license if you copy, modify or distribute the work in a way requiring permission under copyright law.
A "Modified Version" of the Document means any work containing the Document or a portion of it, either copied verbatim, or with modifications and/or translated into another language.
A "Secondary Section" is a named appendix or a front-matter section of the Document that deals exclusively with the relationship of the publishers or authors of the Document to the Document's overall subject (or to related matters) and contains nothing that could fall directly within that overall subject. (Thus, if the Document is in part a textbook of mathematics, a Secondary Section may not explain any mathematics.) The relationship could be a matter of historical connection with the subject or with related matters, or of legal, commercial, philosophical, ethical or political position regarding them.
The "Invariant Sections" are certain Secondary Sections whose titles are designated, as being those of Invariant Sections, in the notice that says that the Document is released under this License. If a section does not fit the above definition of Secondary then it is not allowed to be designated as Invariant. The Document may contain zero Invariant Sections. If the Document does not identify any Invariant Sections then there are none.
The "Cover Texts" are certain short passages of text that are listed, as Front-Cover Texts or Back-Cover Texts, in the notice that says that the Document is released under this License. A Front-Cover Text may be at most 5 words, and a Back-Cover Text may be at most 25 words.
A "Transparent" copy of the Document means a machine-readable copy, represented in a format whose specification is available to the general public, that is suitable for revising the document straightforwardly with generic text editors or (for images composed of pixels) generic paint programs or (for drawings) some widely available drawing editor, and that is suitable for input to text formatters or for automatic translation to a variety of formats suitable for input to text formatters. A copy made in an otherwise Transparent file format whose markup, or absence of markup, has been arranged to thwart or discourage subsequent modification by readers is not Transparent. An image format is not Transparent if used for any substantial amount of text. A copy that is not "Transparent" is called "Opaque".
Examples of suitable formats for Transparent copies include plain ASCII without markup, Texinfo input format, LaTeX input format, SGML or XML using a publicly available DTD, and standard-conforming simple HTML, PostScript or PDF designed for human modification. Examples of transparent image formats include PNG, XCF and JPG. Opaque formats include proprietary formats that can be read and edited only by proprietary word processors, SGML or XML for which the DTD and/or processing tools are not generally available, and the machine-generated HTML, PostScript or PDF produced by some word processors for output purposes only.
The "Title Page" means, for a printed book, the title page itself, plus such following pages as are needed to hold, legibly, the material this License requires to appear in the title page. For works in formats which do not have any title page as such, "Title Page" means the text near the most prominent appearance of the work's title, preceding the beginning of the body of the text.
A section "Entitled XYZ" means a named subunit of the Document whose title either is precisely XYZ or contains XYZ in parentheses following text that translates XYZ in another language. (Here XYZ stands for a specific section name mentioned below, such as "Acknowledgements", "Dedications", "Endorsements", or "History".) To "Preserve the Title" of such a section when you modify the Document means that it remains a section "Entitled XYZ" according to this definition.
The Document may include Warranty Disclaimers next to the notice which states that this License applies to the Document. These Warranty Disclaimers are considered to be included by reference in this License, but only as regards disclaiming warranties: any other implication that these Warranty Disclaimers may have is void and has no effect on the meaning of this License.
A.3. VERBATIM COPYING
You may copy and distribute the Document in any medium, either commercially or noncommercially, provided that this License, the copyright notices, and the license notice saying this License applies to the Document are reproduced in all copies, and that you add no other conditions whatsoever to those of this License. You may not use technical measures to obstruct or control the reading or further copying of the copies you make or distribute. However, you may accept compensation in exchange for copies. If you distribute a large enough number of copies you must also follow the conditions in section 3.
You may also lend copies, under the same conditions stated above, and you may publicly display copies.
A.4. COPYING IN QUANTITY
If you publish printed copies (or copies in media that commonly have printed covers) of the Document, numbering more than 100, and the Document's license notice requires Cover Texts, you must enclose the copies in covers that carry, clearly and legibly, all these Cover Texts: Front-Cover Texts on the front cover, and Back-Cover Texts on the back cover. Both covers must also clearly and legibly identify you as the publisher of these copies. The front cover must present the full title with all words of the title equally prominent and visible. You may add other material on the covers in addition. Copying with changes limited to the covers, as long as they preserve the title of the Document and satisfy these conditions, can be treated as verbatim copying in other respects.
If the required texts for either cover are too voluminous to fit legibly, you should put the first ones listed (as many as fit reasonably) on the actual cover, and continue the rest onto adjacent pages.
If you publish or distribute Opaque copies of the Document numbering more than 100, you must either include a machine-readable Transparent copy along with each Opaque copy, or state in or with each Opaque copy a computer-network location from which the general network-using public has access to download using public-standard network protocols a complete Transparent copy of the Document, free of added material. If you use the latter option, you must take reasonably prudent steps, when you begin distribution of Opaque copies in quantity, to ensure that this Transparent copy will remain thus accessible at the stated location until at least one year after the last time you distribute an Opaque copy (directly or through your agents or retailers) of that edition to the public.
It is requested, but not required, that you contact the authors of the Document well before redistributing any large number of copies, to give them a chance to provide you with an updated version of the Document.
A.5. MODIFICATIONS
You may copy and distribute a Modified Version of the Document under the conditions of sections 2 and 3 above, provided that you release the Modified Version under precisely this License, with the Modified Version filling the role of the Document, thus licensing distribution and modification of the Modified Version to whoever possesses a copy of it. In addition, you must do these things in the Modified Version:
GNU FDL Modification Conditions
Use in the Title Page (and on the covers, if any) a title distinct from that of the Document, and from those of previous versions (which should, if there were any, be listed in the History section of the Document). You may use the same title as a previous version if the original publisher of that version gives permission.
List on the Title Page, as authors, one or more persons or entities responsible for authorship of the modifications in the Modified Version, together with at least five of the principal authors of the Document (all of its principal authors, if it has fewer than five), unless they release you from this requirement.
State on the Title page the name of the publisher of the Modified Version, as the publisher.
Preserve all the copyright notices of the Document.
Add an appropriate copyright notice for your modifications adjacent to the other copyright notices.
Include, immediately after the copyright notices, a license notice giving the public permission to use the Modified Version under the terms of this License, in the form shown in the Addendum below.
Preserve in that license notice the full lists of Invariant Sections and required Cover Texts given in the Document's license notice.
Include an unaltered copy of this License.
Preserve the section Entitled "History", Preserve its Title, and add to it an item stating at least the title, year, new authors, and publisher of the Modified Version as given on the Title Page. If there is no section Entitled "History" in the Document, create one stating the title, year, authors, and publisher of the Document as given on its Title Page, then add an item describing the Modified Version as stated in the previous sentence.
Preserve the network location, if any, given in the Document for public access to a Transparent copy of the Document, and likewise the network locations given in the Document for previous versions it was based on. These may be placed in the "History" section. You may omit a network location for a work that was published at least four years before the Document itself, or if the original publisher of the version it refers to gives permission.
For any section Entitled "Acknowledgements" or "Dedications", Preserve the Title of the section, and preserve in the section all the substance and tone of each of the contributor acknowledgements and/or dedications given therein.
Preserve all the Invariant Sections of the Document, unaltered in their text and in their titles. Section numbers or the equivalent are not considered part of the section titles.
Delete any section Entitled "Endorsements". Such a section may not be included in the Modified Version.
Do not retitle any existing section to be Entitled "Endorsements" or to conflict in title with any Invariant Section.
Preserve any Warranty Disclaimers.
If the Modified Version includes new front-matter sections or appendices that qualify as Secondary Sections and contain no material copied from the Document, you may at your option designate some or all of these sections as invariant. To do this, add their titles to the list of Invariant Sections in the Modified Version's license notice. These titles must be distinct from any other section titles.
You may add a section Entitled "Endorsements", provided it contains nothing but endorsements of your Modified Version by various parties--for example, statements of peer review or that the text has been approved by an organization as the authoritative definition of a standard.
You may add a passage of up to five words as a Front-Cover Text, and a passage of up to 25 words as a Back-Cover Text, to the end of the list of Cover Texts in the Modified Version. Only one passage of Front-Cover Text and one of Back-Cover Text may be added by (or through arrangements made by) any one entity. If the Document already includes a cover text for the same cover, previously added by you or by arrangement made by the same entity you are acting on behalf of, you may not add another; but you may replace the old one, on explicit permission from the previous publisher that added the old one.
The author(s) and publisher(s) of the Document do not by this License give permission to use their names for publicity for or to assert or imply endorsement of any Modified Version.
A.6. COMBINING DOCUMENTS
You may combine the Document with other documents released under this License, under the terms defined in section 4 above for modified versions, provided that you include in the combination all of the Invariant Sections of all of the original documents, unmodified, and list them all as Invariant Sections of your combined work in its license notice, and that you preserve all their Warranty Disclaimers.
The combined work need only contain one copy of this License, and multiple identical Invariant Sections may be replaced with a single copy. If there are multiple Invariant Sections with the same name but different contents, make the title of each such section unique by adding at the end of it, in parentheses, the name of the original author or publisher of that section if known, or else a unique number. Make the same adjustment to the section titles in the list of Invariant Sections in the license notice of the combined work.
In the combination, you must combine any sections Entitled "History" in the various original documents, forming one section Entitled "History"; likewise combine any sections Entitled "Acknowledgements", and any sections Entitled "Dedications". You must delete all sections Entitled "Endorsements".
A.7. COLLECTIONS OF DOCUMENTS
You may make a collection consisting of the Document and other documents released under this License, and replace the individual copies of this License in the various documents with a single copy that is included in the collection, provided that you follow the rules of this License for verbatim copying of each of the documents in all other respects.
You may extract a single document from such a collection, and distribute it individually under this License, provided you insert a copy of this License into the extracted document, and follow this License in all other respects regarding verbatim copying of that document.
A.8. AGGREGATION WITH INDEPENDENT WORKS
A compilation of the Document or its derivatives with other separate and independent documents or works, in or on a volume of a storage or distribution medium, is called an "aggregate" if the copyright resulting from the compilation is not used to limit the legal rights of the compilation's users beyond what the individual works permit. When the Document is included in an aggregate, this License does not apply to the other works in the aggregate which are not themselves derivative works of the Document.
If the Cover Text requirement of section 3 is applicable to these copies of the Document, then if the Document is less than one half of the entire aggregate, the Document's Cover Texts may be placed on covers that bracket the Document within the aggregate, or the electronic equivalent of covers if the Document is in electronic form. Otherwise they must appear on printed covers that bracket the whole aggregate.
A.9. TRANSLATION
Translation is considered a kind of modification, so you may distribute translations of the Document under the terms of section 4. Replacing Invariant Sections with translations requires special permission from their copyright holders, but you may include translations of some or all Invariant Sections in addition to the original versions of these Invariant Sections. You may include a translation of this License, and all the license notices in the Document, and any Warranty Disclaimers, provided that you also include the original English version of this License and the original versions of those notices and disclaimers. In case of a disagreement between the translation and the original version of this License or a notice or disclaimer, the original version will prevail.
If a section in the Document is Entitled "Acknowledgements", "Dedications", or "History", the requirement (section 4) to Preserve its Title (section 1) will typically require changing the actual title.
A.10. TERMINATION
You may not copy, modify, sublicense, or distribute the Document except as expressly provided for under this License. Any other attempt to copy, modify, sublicense or distribute the Document is void, and will automatically terminate your rights under this License. However, parties who have received copies, or rights, from you under this License will not have their licenses terminated so long as such parties remain in full compliance.
A.11. FUTURE REVISIONS OF THIS LICENSE
The Free Software Foundation may publish new, revised versions of the GNU Free Documentation License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns. See http://www.gnu.org/copyleft/.
Each version of the License is given a distinguishing version number. If the Document specifies that a particular numbered version of this License "or any later version" applies to it, you have the option of following the terms and conditions either of that specified version or of any later version that has been published (not as a draft) by the Free Software Foundation. If the Document does not specify a version number of this License, you may choose any version ever published (not as a draft) by the Free Software Foundation.
A.12. ADDENDUM: How to use this License for your documents
To use this License in a document you have written, include a copy of the License in the document and put the following copyright and license notices just after the title page:
Sample Invariant Sections list
Copyright (c) YEAR YOUR NAME. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled "GNU Free Documentation License".
If you have Invariant Sections, Front-Cover Texts and Back-Cover Texts, replace the "with...Texts." line with this:
Sample Invariant Sections list
with the Invariant Sections being LIST THEIR TITLES, with the Front-Cover Texts being LIST, and with the Back-Cover Texts being LIST.
If you have Invariant Sections without Cover Texts, or some other combination of the three, merge those two alternatives to suit the situation.
If your document contains nontrivial examples of program code, we recommend releasing these examples in parallel under your choice of free software license, such as the GNU General Public License, to permit their use in free software.
Glossary (DRAFT, but not for long hopefully)
"The Librarian of the Unseen University had unilaterally decided to aid comprehension by producing an Orang-utan/Human Dictionary. He'd been working on it for three months. It wasn't easy. He'd got as far as `Oook.'" (Terry Pratchett, ``Men At Arms'')
This is a short list of word definitions for concepts relating to Linux and system administration.
- CMOS RAM
CMOS stands for "Complementary Metal Oxide Semiconductor". It is a complex technology, but put very simply it is a type of transistor which maintains its state even if computer is powered off. This is due to a small battery on the motherboard. As a result, it does not lose what was stored on it when the power is switched off.
- account
A Unix system gives users accounts. It gives them a username and a password with which to log on to the account. A home directory in which to store files is usually provided, and permissions to access hardware and software. These things taken as a whole are an account.
- application program
Software that does something useful. The results of using an application program is what the computer was bought for. See also system program, operating system.
- bad block
A block (usually one sector on a disk) that cannot reliably hold data.
- bad sector
Similar to bad block but more precise in the case where a block and a sector may be of differing sizes.
- boot sector
Usually the first sector on any given partition. It contains a very short program (on the order of a few hundred bytes) which will load and start running the operating system proper.
- booting
Everything that happens between the time the computer is switched on and it is ready to accept commands/input from the user is known as booting.
- bootstrap loader
A very small program (usually residing in ROM) which reads a fixed location on a disk (eg. the MBR) and passes control over to it. The data residing on that fixed location is, in general, slightly bigger and more sophisticated, and it then takes responsibility for loading the actual operating system and passing control to it.
- cylinder
The set of tracks on a multi-headed disk that may be accessed without head movement. In other words the tracks which are the same distance from the spindle about which the disk platters rotate. Placing data that is more likely to be accessed at the same time on the same cylinder can reduce the access time significantly as moving the read-write heads is slow compared to the speed with which the disks rotate.
- daemon
A process lurking in the background, usually unnoticed, until something triggers it into action. For example, the update daemon wakes up every thirty seconds or so to flush the buffer cache, and the sendmail daemon awakes whenever someone sends mail.
- daylight savings time
A time of the year during which clocks are set forward one hour. Widely used around the world in summer so that evenings have more daylight than they would otherwise.
- disk controller
A hardware circuit which translates instructions about disk access from the operating system to the physical disk. This provides a layer of abstraction that means that an operating system does not need to know how to talk to the many different types of disks, but only needs to know about the (comparatively low) number of types of disk controller. Common disk controller types are IDE and SCSI.
- emergency boot floppy
A floppy disk which can be used to boot the system even if the hard disk has suffered damage on its filesystem. Most linux distributions offer to make one of these during installation, this is highly recommended. If your Linux distribution does not offer this facility then read the Boot floppy HOWTO, available at the LDP (**Find URL to cite**).
- fibre channel
A high speed networking protocol primarily used in Storage Area Networks. Unlike it's name suggests, fibre channel can be ran over fiber optic, or copper cables.
- filesystem
A term which is used for two purposes and which can have two subtly different meanings. It is either the collection of files and directories on a drive (whether hard drive, floppy, Cd-ROM, etc). Or it is the markers put onto the disk media which the OS uses to decide where to write files to (inodes, blocks, superblocks etc). The actual meaning can almost always be inferred from context.
- formatting
Strictly, formatting is organizing and marking the surface of a disk into tracks, sectors , and cylinders. It is also sometimes (incorrectly) a term used to signify the action of writing a filesystem to a disk (especially in the MS Windows/MS DOS world).
- fragmented
When a file is not written to a disk in contiguous blocks. If there is not enough free space to write a full file to a disk in one continuous stream of blocks then the file gets split up between two or more parts of the disk surface. This is known as fragmenting and can make the time for loading a file longer as the disk has to seek for the rest of the file.
- full backup
Taking a copy of the whole filesystem to a backup media (eg tape, floppy, or CD).
- geometry
How many cylinders, sectors per cylinder and heads a disk drive has.
- high level formatting
An incorrect term for writing a filesystem to a disk. Often used in the MS Windows and MS DOS world.
- incremental backups
A backup of what has changed in a filesystem since the last full backup. Incremental backups if used sensibly as part of a backup regime, can save a lot of time and effort in maintaining a backup of data.
- inode
A data structure holding information about files in a Unix file system. There is an inode for each file and a file is uniquely identified by the file system on which it resides and its inode number on that system. Each inode contains the following information: the device where the inode resides, locking information, mode and type of file, the number of links to the file, the owner's user and group ids, the number of bytes in the file, access and modification times, the time the inode itself was last modified and the addresses of the file's blocks on disk. A Unix directory is an association between file leafnames and inode numbers. A file's inode number can be found using the "-i" switch to ls.
- iSCSI
A network storage protocol that enables the sending of SCSI commands over a TCP/IP network. Primarily used in Storage Area Networks.
- kernel
Part of an operating system that implements the interaction with hardware and the sharing of resources. See also system program.
- local time
The official time in a local region (adjusted for location around the Earth); established by law or custom.
- logical partition
A partition inside an extended partition, which is ``logical'' in that it does not exist in reality, but only inside the logical structure of the software.
- logical volume manager (LVM)
A collection of programs that allow larger physical disks to be reassembled into "logical" disks that can be shrunk or expanded as data needs change.
- low level formatting
Synonymous with formatting and used in the MS DOS world so differentiate from creating a filesystem which is also known as formatting sometimes.
- mail transfer agent
(MTA) The program responsible for delivering e-mail messages. Upon receiving a message from a mail user agent or another MTA it stores it temporarily locally and analyzes the recipients and either delivers it (local addressee) or forwards it to another MTA. In either case it may edit and/or add to the message headers. A widely used MTA for Unix is sendmail.
- mail user agent
(MUA) The program that allows the user to compose and read electronic mail messages. The MUA provides the interface between the user and the mail transfer agent . Outgoing mail is eventually handed over to an MTA for delivery while the incoming messages are picked up from where the MTA left it (although MUAs running on single-user machines may pick up mail using POP). Examples of MUAs are pine, elm and mutt.
- master boot record
(MBR) The first logical sector on a disk, this is (usually) where the BIOS looks to load a small program that will boot the computer.
- network file system
(NFS) A protocol developed by Sun Microsystems, and defined in RFC 1094 (FIND URL), which allows a computer to access files over a network as if they were on its local disks.
- operating system
Software that shares a computer system's resources (processor, memory, disk space, network bandwidth, and so on) between users and the application programs they run. Controls access to the system to provide security. See also kernel, system program, application program.
- partition
A logical section of a disk. Each partition normally has its own file system. Unix tends to treat partitions as though they were separate physical entities.
- password file
A file that holds usernames and information about their accounts like their password. On Unix systems this file is usually /etc/passwd. On most modern Linux systems the /etc/passwd file does not actually hold password data. That tends to be held in a different file /etc/shadow for security reasons. See manual pages passwd(5) and shadow(5) for more information.
- physical extents
A term used to describe a the chunks a physical volume is broken down into when using the Logical Volume Manager.
- physical volume
A term used an actual disk partition, usually in reference to the logical volume manager.
- platters
A physical disk inside a hard drive. Usually a hard drive is made up of multiple physical disks stacked up on top of each other. One individual disk is known as a platter .
- power on self test
(POST) A series of diagnostic tests which are run when a computer is powered on. Typically this might include testing the memory, testing that the hardware configuration is the same as the last saved configuration, checking that any floppy drives, or hard drives which are known about by the BIOS are installed and working.
- print queue
A file (or set of files) which the print daemon uses so that applications which wish to use the printer do not have to wait until the print job they have sent is finished before they can continue. It also allows multiple users to share a printer.
- read-write head
A tiny electromagnetic coil and metal pole used to write and read magnetic patterns on a disk. These coils move laterally against the rotary motion on the platters.
- root filesystem
The parent of all the other filesystems mounted in a Unix filesystem tree. Mounted as / it might have other filesystems mounted on it (/usr for example). If the root filesystem cannot be mounted then the kernel will panic and the system will not be able to continue booting
- run level
Linux has up to 10 runlevels (0-9) available (of which usually only the first 7 are defined). Each runlevel may start a different set of services, giving multiple different configurations in the same system. Runlevel 0 is defined as ``system halt'', runlevel 1 is defined as ``single user mode'', and runlevel 6 is defined as ``reboot system''. The remaining runlevels can, theoretically, be defined by the system administrator in any way. However most distributions provide some other predefined runlevels. For example, runlevel 2 might be defined as ``multi-user console'', and runlevel 5 as ``multi-user X-Window system''. These definitions vary considerably from distribution to distribution, so please check the documentation for your own distribution.
- sectors
The minimum track length that can be allocated to store data. This is usually (but not always) 512 bytes.
- shadow passwords
Because the password file on Unix systems often needs to be world readable it usually does not actually contain the encrypted passwords for users' accounts. Instead a shadow file is employed (which is not world readable) which holds the encrypted passwords for users' accounts.
- single user mode
Usually runlevel 1. A runlevel where logins are not allowed except by the root account. Used either for system repairs (if the filesystem is partially damaged it may still be possible to boot into runlevel 1 and repair it), or for moving filesystems around between partitions. These are just two examples. Any task that requires a system where only one person can write to a disk at a time is a candidate for requiring runlevel 1.
- spool
To send a file (or other data) to a queue. Generally used in conjunction with printers, but might also be used for other things (mail for example). The term is reported to be an acronym for ``Simultaneous Peripheral Operation On-Line'', but according to the Jargon File it may have been a backronym (something made up later for effect).
- system call
The services provided by the kernel to application programs, and the way in which they are invoked. See section 2 of the manual pages.
- swap space
Space on a disk in which the system can write portions of memory to. Usually this is a dedicated partition, but it may also be a swapfile.
- system program
Programs that implement high level functionality of an operating system, i.e., things that aren't directly dependent on the hardware. May sometimes require special privileges to run (e.g., for delivering electronic mail), but often just commonly thought of as part of the system (e.g., a compiler). See also application program, kernel, operating system.
- time drift
This is a term for a computers inaccuracy at keeping track of time. All computers have some rate of error when keeping time. With newer computers this rate of error is extremely small.
- track
The part of a disk platter which passes under one read-write head while the head is stationary but the disk is spinning. Each track is divided into sectors, and a vertical collection of tracks is a cylinder
- volume group
A collection of physical volumes broken down into physical extents, and available for use in logical partitions.
Index-Draft
B
- BIOS, The root filesystem, Hard disks, Partitioning a hard disk
- booting
- vmlinuz, The root filesystem
C
- CMOS, Hard disks
- commands
- badblocks, Formatting
- cfdisk, Partitioning a hard disk
- chsh, The /etc directory
- depmod, depmod
- df, The /etc directory
- fdformat, Formatting
- fdisk, The MBR, boot sectors and partition table, Partition types, Partitioning a hard disk
- file, The /etc directory
- fips, Partitioning a hard disk
- free, The /proc filesystem
- fsck, Formatting
- ftpd, The /etc directory
- getty, init, The /etc directory
- gzexe, Tips for saving disk space
- gzip, Tips for saving disk space
- hdparm, The hdparm command
- init, init
- insmod, insmod
- login, The /etc directory, The /var filesystem
- losetup, The /dev directory
- lpr, Two kinds of devices
- ls, Two kinds of devices
- lsdev, The lsdev command
- lsmod, lsmod
- lspci, The lspci command
- lsraid, The lsraid command
- lsusb, The lsusb command
- MAKEDEV, The /dev directory, The MAKEDEV Script, The mknod command
- man, The /var filesystem
- mkfs, Formatting
- mknod, The mknod command
- modprobe, modprobe
- mount, The /etc directory, The /dev directory
- parted, Partitioning a hard disk
- rmmod, rmmod
- setfdparm, Floppies
- setfdprm, The /etc directory, Formatting
- su, The /etc directory
- sudo, The /etc directory
- swapon, The /etc directory
- syslog, The /var filesystem, Formatting
- zip, Tips for saving disk space
- Common Internet File System (CIFS), Network file systems, Network Attached Storage - Draft, CIFS
- cron, Periodic command execution: cron and at
- crontab , Periodic command execution: cron and at
D
- devices
- block, Two kinds of devices
- character, Two kinds of devices
- disks, Using Disks and Other Storage Media
- bad blocks, Formatting
- bad sectors, Formatting
- boot sectors, The MBR, boot sectors and partition table
- changing partition size, Partitioning a hard disk
- components, Hard disks
- cylinders, Hard disks
- extended partition, Extended and logical partitions, Device files and partitions
- filesystem, What are filesystems?
- data block, What are filesystems?
- directory block, What are filesystems?
- indirection block, What are filesystems?
- inode, What are filesystems?
- superblock, What are filesystems?
- formatting, Formatting
- high-level, Formatting
- low-level, Formatting
- geometry, Hard disks
- IDE, Partitioning a hard disk
- Logical Block Addressing (LBA), Partitioning a hard disk
- MBR, The MBR, boot sectors and partition table
- partition table, The MBR, boot sectors and partition table
- partition type, Partition types
- partitions, Partitions
- saving space, Tips for saving disk space
- sectors, Hard disks
- tracks, Hard disks
F
- fibre channel, Storage Area Networks - Draft
- filesystem, The filesystem layout, The /usr filesystem.
- / (root), Background, The root filesystem
- /bin, The filesystem layout, The root filesystem
- /boot, The root filesystem
- /dev, The filesystem layout, The root filesystem, The /dev directory, Two kinds of devices
- /dev/dsp, The /dev directory
- /dev/fb0, The /dev directory
- /dev/fd0, The /dev directory, Floppies, Formatting
- /dev/fd1, Floppies
- /dev/hda, The /dev directory, Hard disks
- /dev/hdb, The /dev directory, Hard disks
- /dev/hdc, The /dev directory, Hard disks
- /dev/hdc9, The /dev directory
- /dev/hdd, The /dev directory, Hard disks
- /dev/ht0, The /dev directory
- /dev/js0, The /dev directory
- /dev/loop0, The /dev directory
- /dev/lp0, The /dev directory
- /dev/md0, The /dev directory
- /dev/mixer, The /dev directory
- /dev/null, The /dev directory
- /dev/parport0, The /dev directory
- /dev/pcd0, The /dev directory
- /dev/pda, The /dev directory
- /dev/pdb, The /dev directory
- /dev/pdc, The /dev directory
- /dev/pdd, The /dev directory
- /dev/psaux, The /dev directory
- /dev/pt0, The /dev directory
- /dev/pt1, The /dev directory
- /dev/random, The /dev directory
- /dev/sda, The /dev directory, Two kinds of devices, Hard disks
- /dev/sdb, The /dev directory, Hard disks
- /dev/sdd, The /dev directory
- /dev/ttyS0, The /dev directory, The MAKEDEV Script, The mknod command
- /dev/urandom, The /dev directory
- /dev/zero, The /dev directory
- /etc, The filesystem layout, The root filesystem, The /etc directory
- /etc/bash.rc, The /etc directory
- /etc/csh.cshrc, The /etc directory
- /etc/fdprm, The /etc directory, Floppies
- /etc/fstab, The /etc directory
- /etc/group, The /etc directory
- /etc/inittab, The /etc directory
- /etc/issue, The /etc directory
- /etc/login.defs, The /etc directory
- /etc/magic, The /etc directory
- /etc/motd, The /etc directory
- /etc/mtab, The /etc directory
- /etc/passwd, The /etc directory
- /etc/printcap, The /etc directory
- /etc/profile, The /etc directory
- /etc/rc.d, The /etc directory
- /etc/securetty, The /etc directory
- /etc/shadow, The /etc directory
- /etc/shells, The /etc directory
- /etc/termcap, The /etc directory
- /home, The filesystem layout, Background, The root filesystem
- /lib, The filesystem layout, The root filesystem
- /lib/modules, The root filesystem
- /mnt, The root filesystem
- /proc, The root filesystem, The /proc filesystem, Filesystems galore
- /proc/1, The /proc filesystem
- /proc/cpuinfo, The /proc filesystem
- /proc/devices, The /proc filesystem
- /proc/dma, The /proc filesystem
- /proc/filesystems, The /proc filesystem
- /proc/interrupts, The /proc filesystem
- /proc/ioports, The /proc filesystem
- /proc/kcore, The /proc filesystem, Filesystems galore
- /proc/kmsg, The /proc filesystem
- /proc/ksyms, The /proc filesystem
- /proc/loadavg, The /proc filesystem
- /proc/meminfo, The /proc filesystem
- /proc/modules, The /proc filesystem
- /proc/net, The /proc filesystem
- /proc/self, The /proc filesystem
- /proc/stat, The /proc filesystem
- /proc/uptime, The /proc filesystem
- /proc/version, The /proc filesystem
- /root, The root filesystem
- /sbin, The root filesystem
- /tmp, The root filesystem, The /var filesystem
- /usr, The filesystem layout, Background, The root filesystem
- /usr/bin, The /usr filesystem.
- /usr/include, The /usr filesystem.
- /usr/lib, The /usr filesystem.
- /usr/local, The /usr filesystem., The /var filesystem
- /usr/sbin, The /usr filesystem.
- /usr/share/doc, The /usr filesystem.
- /usr/share/info, The /usr filesystem.
- /usr/share/man, The /usr filesystem.
- /usr/share/man/cat, The /var filesystem
- /usr/share/man/man, The /var filesystem
- /usr/X11R6, The /usr filesystem.
- /var, The filesystem layout, Background, The root filesystem, The /var filesystem
- /var/cache/man, The /var filesystem
- /var/games, The /var filesystem
- /var/lib, The /var filesystem
- /var/local, The /var filesystem
- /var/lock, The /var filesystem
- /var/log, The /var filesystem
- /var/log/messages, The /var filesystem
- /var/log/wtmp, The /var filesystem
- /var/mail, The /var filesystem
- /var/run, The /var filesystem
- /var/spool, The /var filesystem
- /var/spool/mail, The /var filesystem
- /var/spool/news, The /var filesystem
- /var/tmp, The /var filesystem
- /var/utmp, The /var filesystem
- Filesystem Hierarchy Standard (FHS) , The filesystem layout, Overview of the Directory Tree, Background
- filesystem types
- ext, Filesystems galore
- ext2, Filesystems galore, Filesystem comparison
- ext3, Filesystems galore, Filesystem comparison
- fat16, Filesystem comparison
- fat32, Filesystem comparison
- hfs+, Filesystem comparison
- hpfs, Filesystems galore, Filesystem comparison
- iso9660, Filesystems galore
- jfs, Filesystems galore, Filesystem comparison
- minix, Filesystems galore
- msdos, Filesystems galore
- nfs, Filesystems galore
- ntfs, Filesystems galore, Filesystem comparison
- reiserfs, Filesystems galore, Filesystem comparison
- smbfs, Filesystems galore
- sysv, Filesystems galore
- ufs2, Filesystem comparison
- umsdos, Filesystems galore
- vfat, Filesystems galore
- vxfs, Filesystem comparison
- xfs, Filesystems galore
- xia, Filesystems galore
- zfs, Filesystem comparison
- filesystems
- /etc
- /etc/fstab, Adding more disk space for Linux
- Free Software Foundation, Linux or GNU/Linux, that is the question.
G
- getty, Logins from terminals, Network logins
- GNOME, Graphical user interface
- GRUB , The root filesystem
- GUI, init, Graphical user interface
- blackbox, Graphical user interface
- fvwm, Graphical user interface
- icewm, Graphical user interface
- windowmaker , Graphical user interface
- X Windows, Graphical user interface
H
- hardware
- CD-ROM, CD-ROMs
- Central Processing Unit (CPU), Hard disks
- disk controller, Hard disks
- fibre channel, Storage Area Networks - Draft
- floppy disk, Floppies
- tape drive, Tapes
I
- init, init, Logins from terminals
- inittab, init
- iSCSI, Storage Area Networks - Draft
- ISO 9660, CD-ROMs
- Rock Ridge extensions, CD-ROMs
K
- KDE, Graphical user interface
- kernel
- devices, Hardware, Devices, and Tools
- documentation
- devices.txt, The mknod command
- driver, Important parts of the kernel
- memory management, Important parts of the kernel
- modules, Kernel Modules
- NFS, Network file systems
- overview, Various parts of an operating system, Important parts of the kernel
- process management, Important parts of the kernel
- virtual filesystem (VFS), Important parts of the kernel
L
- LILO, The root filesystem, Partitioning a hard disk
- Linux
- Distributions, Introduction
- GNU , Linux or GNU/Linux, that is the question.
- logging in, Network logins
- login, Logins from terminals
- logs
- /var/log/messages, The /var filesystem, Formatting
- /var/log/wtmp, The /var filesystem
N
- Network Attached Storage (NAS), Network Attached Storage - Draft
- Network File System (NFS), Network file systems, Background, Network Attached Storage - Draft, NFS
- networking, Networking
- Network Admin Guide (NAG), Networking
P
- partition types
- AIX, Partition types
- FAT16, Partition types
- FAT32, Partition types
- FreeBSD, Partition types
- HPFS, Partition types
- Linux, Partition types
- Linux LVM, Partition types
- Linux Swap, Partition types
- Minix, Partition types
- NetBSD, Partition types
- NTFS, Partition types
- printing, Printing
S
- Samba , Network file systems, Network Attached Storage - Draft, CIFS
- shells
- bash - Bourne Again SHell, The /etc directory
- csh - C SHell, The /etc directory
- sh - Bourne, The /etc directory
- ssh, Network logins
- Storage Area Network (SAN), Storage Area Networks - Draft, Network Attached Storage - Draft
- syslog , Syslog